

目录:
1)介绍
在数字化时代,大量的文本仍然在纸上,幸运的是,计算机视觉的最新进展为我们提供了一种简单而准确的方法来检测和识别文本。在计算机视觉中,将图像或扫描文档中的文本转换为机器可读格式的方法称为光学字符识别(OCR),该格式稍后可编辑、搜索并可用于进一步处理。
2)业务问题
此问题陈述的主要目标是从图像中检测文本,并在该文本周围绘制一个边界框,然后在该边界框内识别该文本。
3)深度学习的使用
深度学习通过一个类似人脑的人工神经网络来学习,它允许机器以结构化的方式分析数据。深度学习可以识别复杂的模式。这里,计算机视觉用于图像分类,对图像和视频中与文本一起存在的对象进行分类和检测。
4)业务约束
5)数据来源和数据总览
要执行此任务,我们将使用两个数据集,
5.1)ICDAR2015数据集
此数据集由国际会议文件分析和识别提供。该数据集包含1000个用于训练的图像和500个用于测试的图像。由于此数据集还不够,我们还使用SynthText数据集。
5.2)SynthText数据集
https://www.robots.ox.ac.uk/~vgg/data/scenetext/https://www.robots.ox.ac.uk/~vgg/data/scenetext/
该数据集是人工生成的数据集,其中单词实例被放置在自然场景图像中。这个数据集由800K的图像组成,在训练文本识别时,这是一个非常大的数据集,由于资源的限制,这里我们只使用了22K的图像。
6)EDA(探索性数据分析)
6.1)否列车和测试图像中的边界框
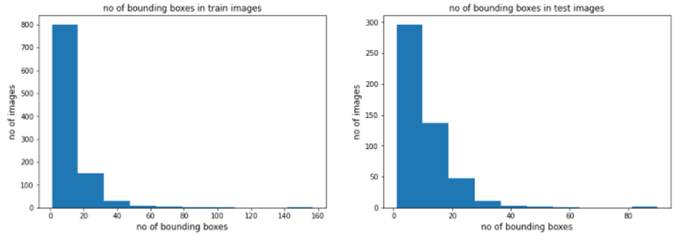
观察结果:
- 从上面的图中我们可以看到,在火车图像中,大多数图像包含1-18个边界框。
- 列车数据中有一些图像,大约包含142-157个包围盒。
- 在测试图像中,大多数图像包含1-10个边界框。
- 测试数据中包含82-92个边界框的图像很少。
6.2)列车图像中包围盒的高度和宽度:
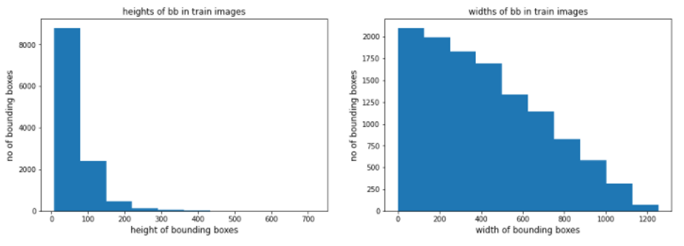
观察结果:
- 从上面的批次我们可以看到,火车图像中的大多数包围盒的高度都小于80。
- 某些边界框的高度也大于300。
- 列车图像中的大多数边界框的宽度都小于600。
- 某些边界框的宽度也大于1200。
6.3)列车图像中包围盒的高度和宽度:
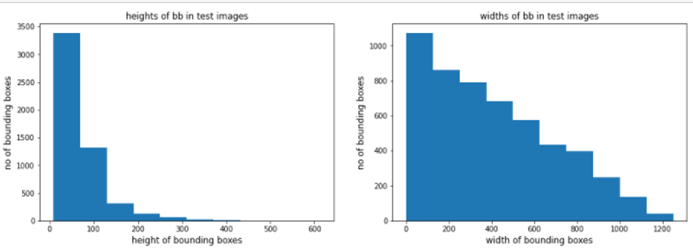
观察结果:
- 从上面的批次我们可以看到,测试图像中的大多数边界框的高度都小于80。
- 某些边界框的高度也大于300。
- 测试图像中的大多数边界框的宽度都小于600。
- 某些边界框的宽度也大于1200。
打印原始图像和带边界框的图像:
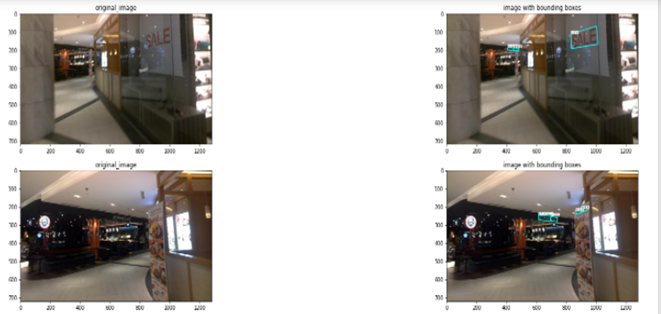

观察结果:
7)深度学习时代之前的文本检测方法
在深度学习时代之前,文本检测有两种方法。
7.1)MSER
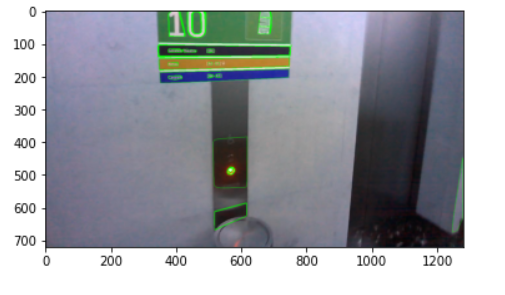
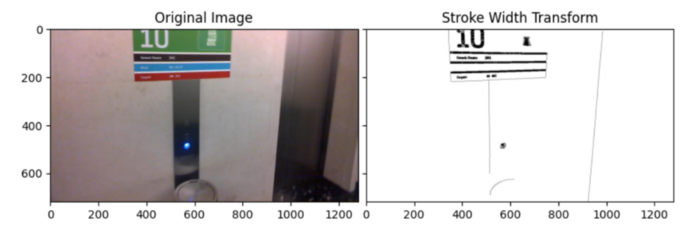
7.2)SWT
8)深度学习时代的方法
文本检测:
对于文本检测,我们使用EAST架构。
东部:
EAST代表高效、准确的现场文本检测器。EAST算法使用单个神经网络来预测单词或行级文本。它可以检测具有四边形的任意方向的文本。该算法由一个非最大抑制合并状态的完全卷积网络组成。使用完全卷积网络来定位图像中的文本,而NMS阶段基本上用于将许多不精确的检测到的文本框合并到每个文本区域的单个边界框中。
东方建筑主要由三部分组成,
a.特征提取器杆。
b.特征合并主干。
C.输出层。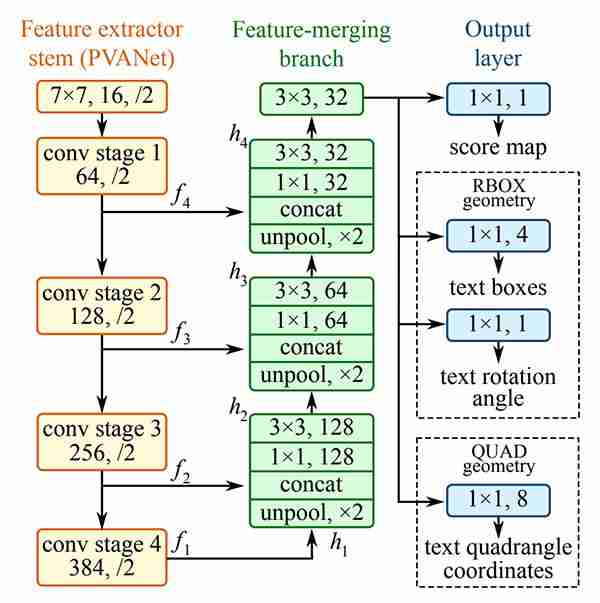
a.特征提取器杆:
此分支用于从网络的不同层提取特征。PVAnet有4个卷积阶段。每个卷积阶段都有聚合层。从该网络生成四个特征映射,这些特征映射从上图表示为f1、f2、f3、f4。这些f1、f2、f3、f4被发送到特征合并分支。
b.特征合并词干:
在该分支中,F1的输出被馈送到其大小加倍的Unpool层,然后与当前特征图连接,然后馈送到具有11个和128个滤波器的卷积层,然后再应用具有33个和128个滤波器的卷积层。
c.输出层:
特征合并分支的最终输出被发送到记分图、RBOX几何图形和四边形几何图形中。
分数图:
特征合并分支的最终输出通过1过滤传递到1*1卷积层,生成得分图。分数图范围在0到1之间。
RBOX几何体:
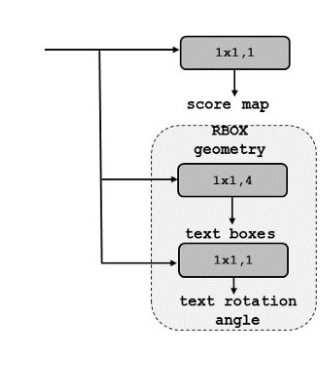
此几何体使用四通道轴对齐边界框(AABB)和通道旋转角度θ。4个通道表示4个距离,1个通道表示旋转角θ。
四边形几何图形:
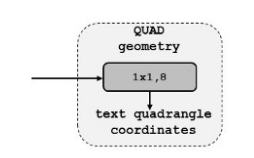
对于四边形几何体,我们使用8个通道。
实施:
我已经尝试过使用VGG16和RESNET50架构来实现。
a.VGG16:
b.Resnet50:
从上面的体系结构来看,我可以说Resnet50体系结构与VGG16相比执行得非常好。
损失函数:
我们有两个输出,一个是分数图,另一个是几何图,所以我们必须计算这两个图的损失。
总损失写成,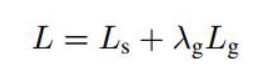
这里,ls表示得分图,lg表示几何图,λg表示两次损失之间的权重。我们将λg保持为1。
分数图丢失:
本研究采用正负两类权重的二元交叉熵来衡量失分。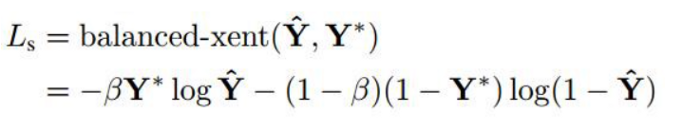
但在实现中,我们使用的是骰子损失。
几何体贴图丢失:
这里几何损失可以计算为,
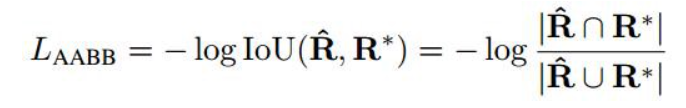
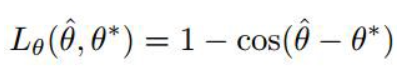
损失函数的执行情况:
推理管道:
实施:


文本识别:
对于文本识别,我们使用了卷积神经网络结构。
实施:
9)模型分析
由于Resnet50模型的性能最好,我们使用每个图像的损失对模型性能进行了分析。我们进一步将损失分为3类:最好的、中等的和最差的。
9.1区域图
列车数据:

观察结果:
测试数据:
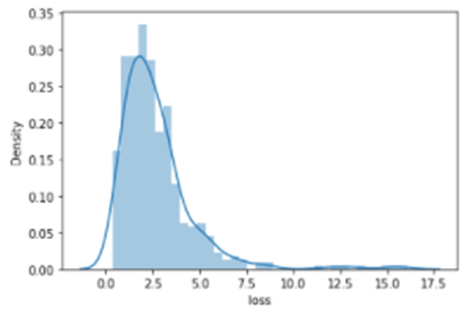
观察结果:
- 从上面的曲线图中,我们可以看到列车损失在btw 0和10之间。
- 因为存在大于1的损失,这意味着我们的模型在测试数据上表现不佳。
- 由于训练数据和测试数据的分布不同,我们可以说该模型在这两个数据上的表现是不同的。
将损失特征分为3类,即最佳、最差、中等
列车数据:
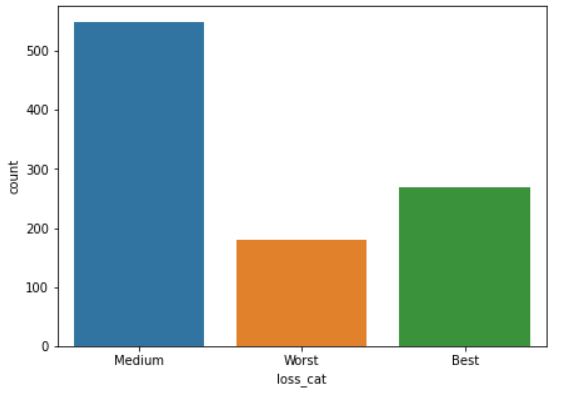
观察结果:
测试数据:
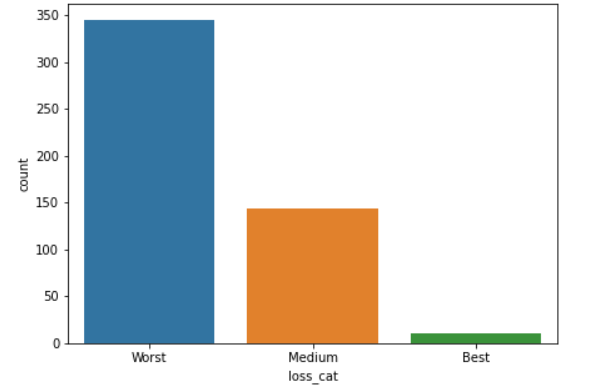
观察结果:
10)部署
对于部署,我们使用Streamlight和ngrok,ngrok使我们能够直接从Google CoLab进行部署。
步骤:
11)未来工作
12)个人资料
1.Github:
https://github.com/rajat-negi/Scene_Text_Detection_and_Recognitionhttps://github.com/rajat-negi/Scene_Text_Detection_and_Recognition
2.LinkedIn:
https://www.linkedin.com/in/rajat-negi-289361166https://www.linkedin.com/in/rajat-negi-289361166
13)参考文献
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/31/%e5%9c%ba%e6%99%af%e6%96%87%e6%9c%ac%e6%a3%80%e6%b5%8b%e4%b8%8e%e8%af%86%e5%88%ab/
