
YOLOv3是什么?
YOLOv3(您只需看一次,版本3)是一种实时对象检测算法,可识别视频、实况馈送或图像中的特定对象。YOLO使用深度卷积神经网络学习的特征来检测目标。YOLO的版本1?EURO“3是由约瑟夫·雷德蒙和阿里·法哈迪创建的。YOLO的第一个版本创建于2016年,本文中广泛讨论的版本3是在两年后的2018年制作的。YOLO使用KERAS或OpenCV深度学习库实施。
简而言之,YOLOv3是如何工作的?
YOLO是一种用于实时执行目标检测的卷积神经网络(CNN)。CNN是基于分类器的系统,可以将输入图像处理为结构化的数据数组,并识别它们之间的模式。YOLO具有比其他网络快得多的优势,并且仍然保持准确性,因为它允许模型在测试时查看整个图像,因此它的预测是由图像中的全局上下文通知的。YOLO和其他卷积神经网络算法基于它们与预定义类的相似性,对œ�区域进行评分。
高分区域被认为是对它们最接近的类别的阳性检测。例如,在交通的实况馈送中,YOLO可用于检测不同类型的车辆,这取决于与预定义的车辆类别相比,视频得分的哪些区域较高
让?Euro™了解YOLOv3的体系结构
YOLOv3算法首先将图像分割成网格。每个栅格单元预测前面提到的预定义类得分很高的对象周围一定数量的边界框(有时称为锚框)。
每个边界框具有各自的置信度分数,其假设预测应该有多精确,并且每个边界框仅检测一个对象。边界框是通过对来自原始数据集的地面真值框的维度进行聚类以找到最常见的形状和大小来生成的。
其他可以实现相同目标的可比算法有R-CNN(2015年制造的基于区域的卷积神经网络)和Fast R-CNN(2017年开发的R-CNN改进),以及Mask R-CNN。
然而,与R-CNN和Fast R-CNN等系统不同的是,YOLO被训练成同时进行分类和边界盒回归。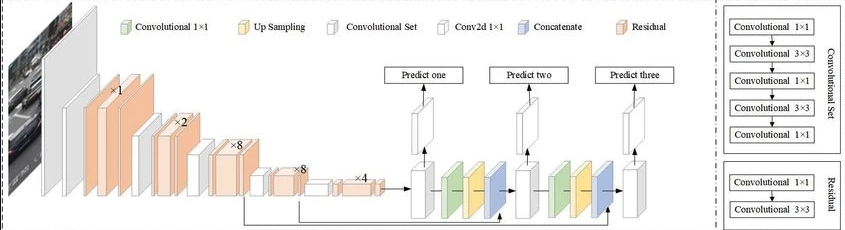
它还有什么比YOLOv2更好的呢?
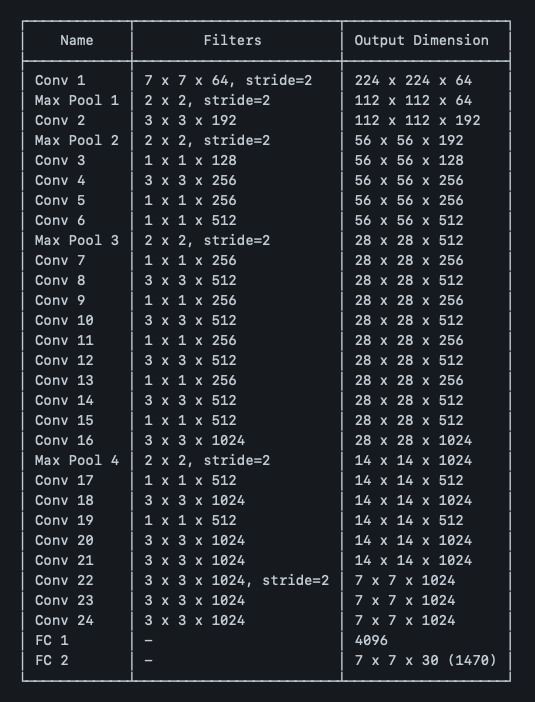
YOLOv2使用Darknet-19作为其主干特征提取器,而YOLOv3现在使用Darknet-53。暗网-53也是YOLO的创建者约瑟夫·雷德蒙和阿里·法哈迪制造的主干。
DarkNet-53有53层卷积层,而不是以前的19层,这使得它比Darknet-19更强大,比竞争主干(ResNet-101或ResNet-152)更有效率。
主干的比较。各种网络的精确度、数十亿次运算(Ops)、每秒10亿次浮点运算(BFLOP/s)和每秒帧数(FPS
YOLOv3在平均平均精度(MAP)和并集交集(IOU)值方面也是快速而准确的。与其他性能相当的检测方法相比,它的运行速度要快得多(因此得名“EURO”,您只需看一次)。
此外,您可以很容易地在速度和精度之间进行权衡,只需更改模型-Euro™的大小,而不需要重新培训。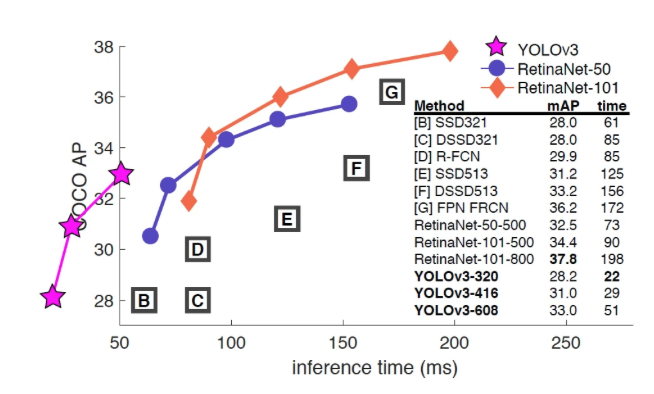
YOLOv3性能
我们在自定义数据集中使用的类有
- Hardhats - Vests - Marks - Boots使用BBox
理解YOLO的第一步是它如何对其输出进行编码。输入图像被划分为S x S网格的单元。对于出现在图像上的每个对象,一个网格单元被认为是负责预测它的“EuroœResponsible”�。这就是对象中心落入的单元格。每个网格单元预测B个边界框和C类概率。边界框预测有5个分量:(x,y,w,h,置信度)。(x,y)坐标表示方框的中心,相对于网格单元位置(请记住,如果方框的中心不落在网格单元内,则此单元不负责此位置)。这些坐标归一化为介于0和1之间。相对于图像大小,(w,h)框尺寸也归一化为[0,1]。让我们来看一个例子–Euro™s:
还需要预测类别概率Pr(Class(I)|Object)。此概率以包含一个对象的网格单元为条件(如果您不知道条件概率的含义,请参阅™)。实际上,这意味着如果网格单元上没有对象,损失函数不会因为错误的类别预测而惩罚它,我们将在后面看到这一点。网络只预测每个像元一组分类概率,而不考虑框B的数量。这使得S x S x C类概率总计为S x S x C
将类预测加到输出向量上,我们得到一个SxSx(B*5+C)张量作为输出。
它是怎么工作的?
- 小对象的精度
YOLOv2中对于小对象的精度是其他算法无法比拟的,因为YOLO在检测小对象方面非常不准确。AP为5.0,与RetinaNet(21.8)或SSD513(10.2)等其他算法相比就相形见绌了,后者对于小对象的AP是第二低的。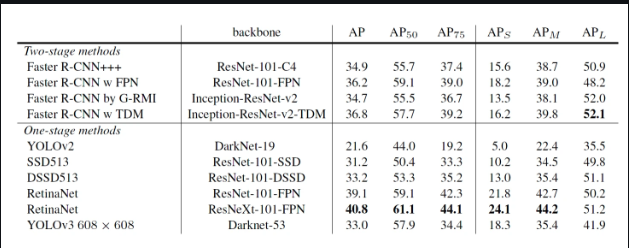
上图显示了使用各种算法和主干检测小、中、大图像的平均精度(AP)。AP越高,该变量的精度越高。
新的YOLOv3在训练过程中使用独立的Logistic分类器和二进制交叉熵损失进行类预测。这些编辑使得使用复杂的数据集成为可能,例如微软™的开放图像数据集(OID)用于YOLOv3模型培训。oid包含数十个重叠的标签,例如数据集中图像的“uroœmanâuro�”和“uroœPersonâuro�”。
YOLOv3使用多标签方法,允许类更具体,并且对于单个边界框是多个的。同时,YOLOv2使用了Softmax,这是一个数学函数,它将数字向量转换为概率向量,其中每个值的概率与向量中每个值的相对比例成比例。
使用Softmax使得每个边界框只能属于一个类,有时情况并非如此,特别是对于像OID这样的数据集。
在YOLOv3及其其他版本中,此预测映射的解释方式是每个单元格预测固定数量的边界框。然后,将包含感兴趣对象的地面真值框中心的任何一个单元格指定为最终负责预测该对象的单元格。预测体系结构的内部工作背后有大量的数学知识。
- 锚箱
虽然本文开始时稍微讨论了锚定框或边界框,但是关于实现它们和在YOLOv3中使用它们,还有更多细节。使用YOLOv3的对象检测器通常预测日志空间转换,这是对预定义的“œDefault”�边界框的偏移。这些特定的边界框称为锚点。稍后将转换应用于锚框以接收预测。YOLOv3特别具有三个锚点。这导致预测每个细胞有三个边界框(该细胞在更专业的术语中也称为神经元)。
- 非最大抑制
当一个以上的边界框将对象检测为肯定的类别检测时,有时可以多次检测该对象。非最大抑制有助于避免这种情况,并且只有在尚未检测到™的情况下才会通过检测。利用NMS阈值和置信度阈值实现NMS,以防止双重检测。这是有效使用YOLOv3不可缺少的一部分。在这里,我们简要描述了一些使预测成为可能的功能,例如锚定框和非最大抑制(NMS)值。然而,这并不是使用YOLOv3创建成功预测所需的所有功能的完整表示。
图像
视频

参考文献
贡献者
- 阿马尔·阿迪尔
- 克里西加
- Shashwat Dhanraaj
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/08/03/%e5%85%b7%e6%9c%89%e8%87%aa%e5%ae%9a%e4%b9%89%e6%95%b0%e6%8d%ae%e9%9b%86%e7%89%88%e6%9c%ac%e7%9a%84yolov3%ef%bc%9f%e6%98%af%e3%80%82-2/
