

前提–由于大流行,基于AR/VR的教育研究迅速加速。我在一家意大利机器人实验室做过同样的研究人员。该项目由欧盟资助,旨在开发虚拟矿场,用于采矿教育的VR头盔显示器。我的任务是研究并制作一个软件流水线的原型,该流水线具有以下功能-
所以我们走吧。这是我的第一个自由职业项目。现在让我们来看看我是如何研究和开发这个项目的原型的。
这篇文章分为以下几个部分-
初步研究–经典计算机视觉
我们知道我们知道!深度学习被认为是分割问题的一站式解决方案,因为在这一点上,它可以比人类更好地设计特征空间。只要输入数据就行了,瞧!但与我的合作者一起,我们想首先探索经典的计算机视觉方法,看看是否能得到一些有趣的东西。这是一种好奇心驱使的行为。
我们开始时非常简单-处理和操纵RGB颜色空间进行分割。我们总是建议创建一个简单的场景来测试基本算法。所以我用了4张图片来测试这些算法。
本节介绍了多种简单的分割技术(在Python中)-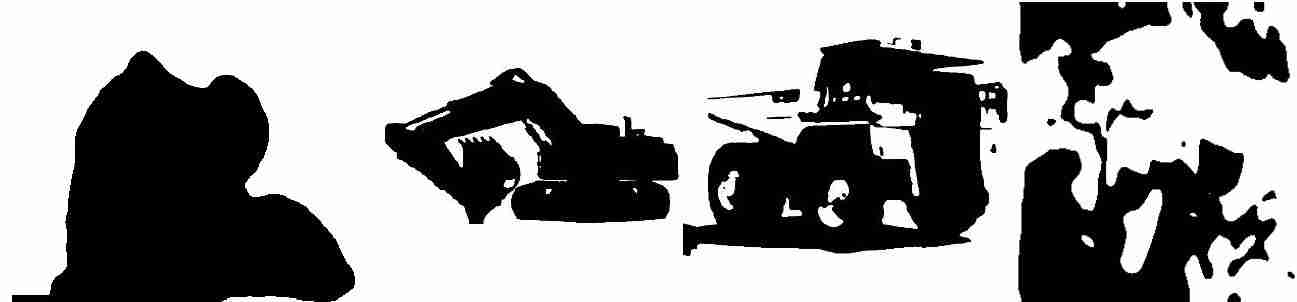
就像在大多数实际应用中一样,经验阈值比最大类间方差(Otsu)表现得更好。阈值处理的工作原理是根据强度分离像素。由于我们的目标图像(图4)在车辆和背景之间没有显著差异,简单的cv技术(如阈值)无法产生任何类型的结果。
2.基于RGB的K均值聚类
K(经验发现)均值聚类用于在图像中寻找聚类,使得车辆的所有部分落入同一聚类(k表示聚类->选择一个具有最大车辆面积的聚类->形态学技术来填充空洞)。
这里,群集又是按强度工作的。因此,它不能给出令人满意的结果。
3.GrabCut
GrabCut算法是本文提出的一种基于混合模型的算法,Python OpenCV对此有一个实现。它在目标映像上的性能也不够好(图4)this
4.实验室颜色空间+阈值由于RGB颜色空间表现不佳,我们尝试了其他颜色空间。其中一个是实验室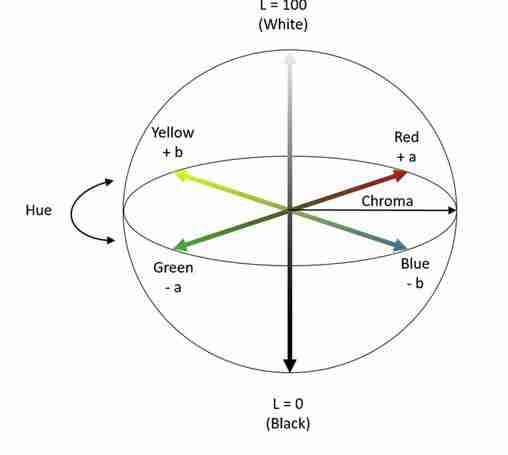
LAB颜色空间的通道“b”对于更接近黄色的像素具有较高的值。由于车辆主要是黄色的,我将RGB图像转换为LAB并隔离此通道。在经验阈值的基础上,对四幅车辆图像进行了实验,结果如下:
虽然LAB的性能比RGB颜色空间好得多,但它只能在最小杂乱的情况下迎合高分辨率图像。
5.实验室+光流在这一点上,我们想要探索时间信息对此分割任务的重要性。简而言之,车辆的运动矢量(除非静止不动)会与周围环境不同。因此,如果我们在实验室中创建“b”通道的特征空间,并从视频中创建光流矢量(x,y),则可以使用k-均值聚类来处理该特征空间。该算法直观地结合了车辆的黄色和运动两个信息。
为了简化我们的输入数据,我们在实验室录制了一段视频,视频中这辆车的一个玩具模型在不同的障碍物周围移动。利用Python OpenCV实现了该算法,并对视频进行了处理。以下是一个示例结果-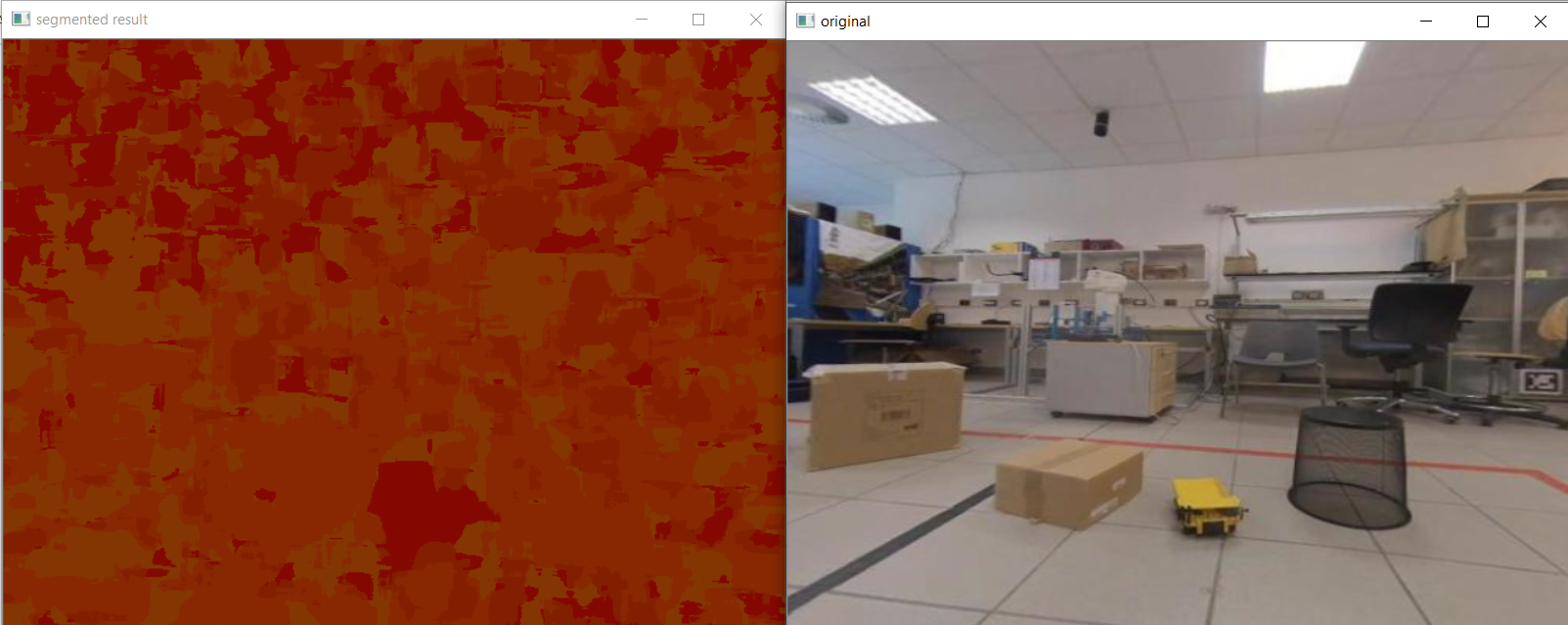
由于相似的光流矢量,结果很差。在这段重新制作的视频中,颜色也是相似的。因此,LAB的表现也很差。
在这一点上,是深入学习的时候了!你在等这件事,不是吗?;)
初步研究-深度学习
我们重点研究了两种深度学习方法??自监督分割和监督分割。
a.自我监督分割Facebook最近开源的Dino模型在使用注意力进行图像/帧分割方面非常强大。我们使用了Facebook在Github上提供的预先训练的模型来制作我们来自真实矿井的目标视频,结果是-DINO Facebook on Github
虽然恐龙非常强大,但结果并不干净。此外,显示的结果使用了一段等长方形框架。但最优模型会考虑整个等长方形框架并产生输出。因此,我们继续进行监督学习。
b.监督细分本节标志着最关键的研究和原型阶段的开始。我们探索了各种实例和语义分割模型,如Mask-RCNN和UNET。由于我们的目标是语义分割,并且每帧中都会有一个车辆实例,所以我们选择UNET作为首选的分割模型。
下一步将是收集数据,对其进行注释以获得分段掩码,并对UNET进行培训。但这里有几个问题-
首先,让我们谈谈第一点,我们通过使用开源的预先训练的UNET模型(训练有素的编码器)解决了这个问题。此方法允许我们注释和使用大小为400的数据集,而不是数千个图像。
继续到点2,我们希望首先将感兴趣的区域(车辆)从巨型框架中分离出来。所以我们先用YOLO物体探测器来检测车辆。YOLO给了我们一个边框,我们扩大了一个小百分比(安全边际),并裁剪了这一部分。接下来,我们使用这张新图像作为UNET的输入,它给我们提供了分割输出。因为我们从YOLO中知道了裁剪图像在实际等长方形框架中的绝对位置,所以我们可以将UNET输出掩模放置在正确的位置,并为该帧构建分割掩模。
那么我们的最后一条管道呢?
YOLOV3→UNET
原型制作-YOLOV3+UNET
1.YOLOV3-这是我们从等长方形框架中检测和裁剪车辆的流水线的前半部分。
培训-我们从视频中提取了200个等长方形的帧(如本文的第一张图片所示),并使用lablimg(YOLO Config)对其进行了注释。这为我们提供了用于培训的自定义数据集。
为了训练YOLOV3,我们使用了DarkNet,这是一个开源框架,您可以使用它来轻松地训练YOLO并从中推断。
推理-经过训练后,我们将获得的权重保存起来,并将它们加载到CV2的深度神经网络模块(Python中)。利用这一点进行推断,以下是示例结果-
我们保存了框架的边界框的尺寸和位置,并将此裁剪的部分传递给UNET,它有望分割车辆。但它会吗?等一等;)
2.UNET-这是我们流水线的后半部分,理想情况下,它将获取裁剪后的图像,并产生如下所示的分段输出-
培训-我们准备了模型并创建了用于培训UNET的数据集。
首先,创建用于分段的数据集是一项艰巨的任务。因此,我们求助于使用预先训练的UNET模型,并用我们的自定义数据集训练其解码器。通过一些研究,我们找到了这个针对UNET的开源预训模型。该模型运行良好,并且有大量文档可供深入研究。this
第二,我们开始为UNET制作数据集。为此,我们取了YOLO提供的400张裁剪后的图像,并手动为它们制作了分割掩模图像。
第三,我们用我们新创建的自定义数据集对上面提到的开源UNET模型进行了大约6小时的培训。以下是结果-
由于训练时间较短和数据集较小,预测不如地面事实准确。在最后的训练中,训练时间增加了几个小时,以产生更好的效果。
推论-
根据推论,我们得出以下结果:
3.建设管道(YOLOV3+UNET)-在这一点上,YOLOV3和UNET模式都有效。因此,我们创建了以下将它们组合在一起的管道。
- YOLOV3从测试视频(等长方形)中提取每一帧,并为车辆生成一个边界框
- 边框略微放大,图像被裁剪。边界框的尺寸和位置也被存储(以便稍后将来自UNET的分割图像放置在正确的位置)
- 裁剪后的图像被提供给UNET,它会生成相同大小的二进制蒙版
- 将创建与输入等长方形图像尺寸相同的黑色蒙版,并将UNET的二进制蒙版放置在正确位置(基于保存的边界框位置)
- 最终蒙版图像将保存为帧的最终输出
- 对测试视频中的每一帧重复上述步骤,从而为我们提供视频中所有帧的输出。
- 所有的输出帧被组合在一起,以产生我们的最终输出视频。
以下是一帧的示例结果-

看哪!这是这个项目的最终结果-
性能和进一步的注意事项-
YOLO对象检测和UNET语义分割相结合的管道给了我们很好的定性结果,如视频所示。但这里有一些考虑因素-
- UNET的预测没有给出清晰的分段掩码。这主要是因为我们应该用更长的时间和更多的数据对其进行培训
- 这条管道通过类似天气条件的视频进行培训和测试。我们还应该用带雨的框架/不同的照明条件,不同数量的灰尘等来训练它。这将有助于管道更好地推广。我们仍然要执行这项任务。但目前,由于人力和资源的限制,收集数据并对其进行注释是一个问题。
总体而言,该解决方案表明,使用所选择的深度学习管道,问题陈述是可解的。下一步将是使其健壮,从而推广其性能。下一步还应对管道的性能进行定量测量。
总体而言,这个项目是计算机视觉在研发原型方面的一次有趣的探索。
我很想知道你的想法!
干杯!沙拉德
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/08/04/%e8%87%aa%e7%94%b1%e8%81%8c%e4%b8%9a%e9%a1%b9%e7%9b%ae-%e5%9f%ba%e4%ba%8exr%e7%9a%84%e7%9f%bf%e4%b8%9a%e6%95%99%e8%82%b2%e7%9a%84%e8%a7%86%e8%a7%89%e5%88%86%e5%89%b2%e5%bc%80%e6%ba%90/
