
作者|Moez Ali
编译|VK
来源|Towards Data Science
你可能会想知道,GitHub是从什么时候开始涉足自动机器学习业务的。好吧,它其实没有,但你可以像有一样的使用它。在本教程中,我们将向你展示如何构建个性化的AutoML软件,并将其托管在GitHub上,以便其他人可以免费使用或付费订阅。

我们将使用pycaret2.0,一个开源的、少代码行数的Python机器学习库来开发一个简单的AutoML解决方案,并使用GitHub Action将其部署为Docker容器。
如果你以前没有听说过PyCaret,可以在这里阅读pycaret2.0的官方声明:https://towardsdatascience.com/announcing-pycaret-2-0-39c11014540e,或者查看这里的详细发行说明:https://github.com/pycaret/pycaret/releases/tag/2.0。
本教程的学习目标
-
了解什么是AutoML,以及如何使用pycaret2.0构建一个简单的AutoML软件。
-
了解什么是容器以及如何将AutoML解决方案部署为Docker容器。
-
什么是GitHub Action以及如何使用它们来托管AutoML软件。
什么是AutoML?
AutoML是一个将耗时、迭代的机器学习任务自动化的过程。它允许数据科学家和分析员在保持模型质量的同时高效地构建机器学习模型。任何AutoML软件的最终目标都是根据某些性能标准最终确定最佳模型。
传统的机器学习模型开发过程是资源密集型的,需要大量的领域知识和时间来生成和比较几十个模型。通过自动化机器学习,你将加快开发生产ML模型所需的时间,并且实现非常容易和高效。
有很多AutoML软件,付费的和开源的。几乎所有的算法都使用相同的变换和基算法集合。因此,在软件下训练的模型的质量和性能基本相同。
付费的AutoML软件作为一种服务是非常昂贵的。如果你的口袋里如果没有很多钱,至少在财务上是不可行的。托管机器学习作为一种服务平台相对来说成本较低,但它们通常很难使用,并且需要特定平台的知识。
在许多其他开放源码的AutoML库中,PyCaret是一个相对较新的库,并且具有独特的机器学习方法接口。PyCaret的设计和功能简单、人性化、直观。在很短的时间内,PyCaret被全球超过10万名数据科学家采用,我们是一个不断增长的开发者社区。
PyCaret是如何工作的
PyCaret是一个用于有监督和无监督机器学习的工作流自动化工具。它被组织成六个模块,每个模块都有一组可用于执行某些特定操作的函数。每个函数接受一个输入并返回一个输出。从第二个版本开始提供的模块包括:
- Classification:https://www.pycaret.org/classification
- Regression:https://www.pycaret.org/regression
- Clustering:https://www.pycaret.org/clustering
- Anomaly Detection:https://www.pycaret.org/anomaly-detection
- Natural Language Processing:https://www.pycaret.org/nlp
- Association Rule Mining:https://www.pycaret.org/association-rules
PyCaret中的所有模块都支持数据预处理(超过25种以上的基本预处理技术,提供大量未经训练的模型和支持自定义模型、自动超参数调优、模型分析和可解释性、自动模型选择、实验日志记录和简单的云部署选项)。

要了解更多关于PyCaret的信息,请单击此处阅读我们的官方发布公告:https://towardsdatascience.com/announcing-pycaret-2-0-39c11014540e
如果你想开始使用Python,请单击此处查看要入门的示例Notebook的库:https://github.com/pycaret/pycaret/tree/master/examples
在我们开始之前
在开始构建AutoML软件之前,让我们先了解以下术语。在这一点上,你所需要的是一些我们在本教程中使用的工具/术语的基本理论知识。如果你想了解更多详细信息,本教程末尾有一些链接供你稍后探索。
容器
容器(Containers)提供了一个可移植和一致的环境,可以在不同的环境中快速部署,以最大限度地提高机器学习应用程序的准确性、性能和效率。环境包含运行时语言(例如Python)、所有库和应用程序的依赖项。
Docker
Docker是一家提供软件(也称为Docker)的公司,它允许用户构建、运行和管理容器。虽然Docker的容器是最常见的,但也有其他不太著名的替代品,如LXD和LXC,也提供了容器解决方案。
github
GitHub是一个基于云的服务,用于托管、管理和控制代码。假设你正在一个大型团队中工作,其中多人(有时数百人)在同一个代码库上进行更改。PyCaret本身就是一个开源项目的例子,在这个项目中,数百名社区开发人员在不断地为源代码做贡献。如果你以前没有使用过GitHub,你可以注册一个免费帐户。
GitHub Action
GitHub操作(Action)可帮助你在存储代码和协作处理。实现自动化软件开发工作流。你可以编写单个任务,并将它们组合起来以创建自定义工作流。
工作流是自定义的自动化流程,你可以在存储库中设置这些流程,以便在GitHub上构建、测试、打包、发布或部署任何代码项目。
目的
训练和选择基于数据集中的其他变量(即年龄、性别、bmi、儿童、吸烟者和地区)预测患者费用的最佳回归模型。
步骤1-开发app.py
这是AutoML的主文件,也是Dockerfile的入口点(请参见下面的步骤2)。如果你以前使用过PyCaret,那么这个代码你可以自行解释。
import os, ast
import pandas as pd
dataset = os.environ["INPUT_DATASET"]
target = os.environ["INPUT_TARGET"]
usecase = os.environ["INPUT_USECASE"]
dataset_path = "https://raw.githubusercontent.com/" + os.environ["GITHUB_REPOSITORY"] + "/master/" + os.environ["INPUT_DATASET"] + '.csv'
data = pd.read_csv(dataset_path)
data.head()
if usecase == 'regression':
from pycaret.regression import *
elif usecase == 'classification':
from pycaret.classification import *
exp1 = setup(data, target = target, session_id=123, silent=True, html=False, log_experiment=True, experiment_name='exp_github')
best = compare_models()
best_model = finalize_model(best)
save_model(best_model, 'model')
logs_exp_github = get_logs(save=True)https://github.com/pycaret/pycaret-git-actions/blob/master/app.py
前五行是关于从环境中导入库和变量。接下来的三行用于将数据作为pandas数据帧读取。第12行到第15行是根据环境变量导入相关模块,第17行之后是PyCaret初始化环境、比较基本模型和在设备上保存性能最好的模型的函数。最后一行将实验日志作为csv文件下载。
步骤2-创建Dockerfile
Dockerfile只是一个包含几行指令的文件,它们保存在项目的文件夹中,名为“Dockerfile”(区分大小写,没有扩展名)。
另一种思考Docker文件的方法是,它就像是你在自己的厨房里发明的食谱。当你和其他人分享这样的菜谱时,如果他们按照食谱中完全相同的说明来做,他们将能够以同样的质量重现同一道菜。
类似地,你可以与其他人共享你的docker文件,然后其他人可以基于该docker文件创建镜像并运行容器。
这个项目的Docker文件很简单,只包含6行。见下文:
FROM python:3.7-slim
WORKDIR /app
ADD . /app
RUN apt-get update && apt-get install -y libgomp1
RUN pip install --trusted-host pypi.python.org -r requirements.txt
ENTRYPOINT ["python"]
CMD ["/app/app.py"]https://github.com/pycaret/pycaret-git-actions/blob/master/Dockerfile
Dockerfile中的第一行导入python:3.7-slim。接下来的四行代码创建一个app文件夹,更新libgomp1库,并从requirements.txt在本例中只需要pycaret的文件。最后,最后两行定义应用程序的入口点;这意味着当容器启动时,它将执行我们前面在步骤1中看到的app.py文件。
步骤3-创建action.yml
Docker操作需要元数据文件。元数据文件名必须是action.yml或者action.yaml. 元数据文件中的数据定义操作的输入、输出和主入口点。操作文件使用YAML语法。
name: "PyCaret AutoML Git Action"
description: "A simple example of AutoML created using PyCaret 2.0"
author: "Moez Ali"
inputs:
DATASET:
description: "Dataset for Training"
required: true
default: "juice"
TARGET:
description: "Name of Target variable"
required: true
default: "Purchase"
USECASE:
description: "Use-case Classification or Regression"
required: true
default: "classification"
outputs:
myOutput:
description: "Output from the action"
runs:
using: "docker"
image: "Dockerfile"
branding:
icon: 'box'
color: 'blue'https://github.com/pycaret/pycaret-git-actions/blob/master/action.yml
环境变量dataset、target和usecase分别在第6、9和14行声明。参见第4-6行。
步骤4-在GitHub上发布
此时,项目文件夹应如下所示:
点击“Releases”:
起草新版本:

填写详细信息(标签、发布标题和说明),然后单击“Publish release”:
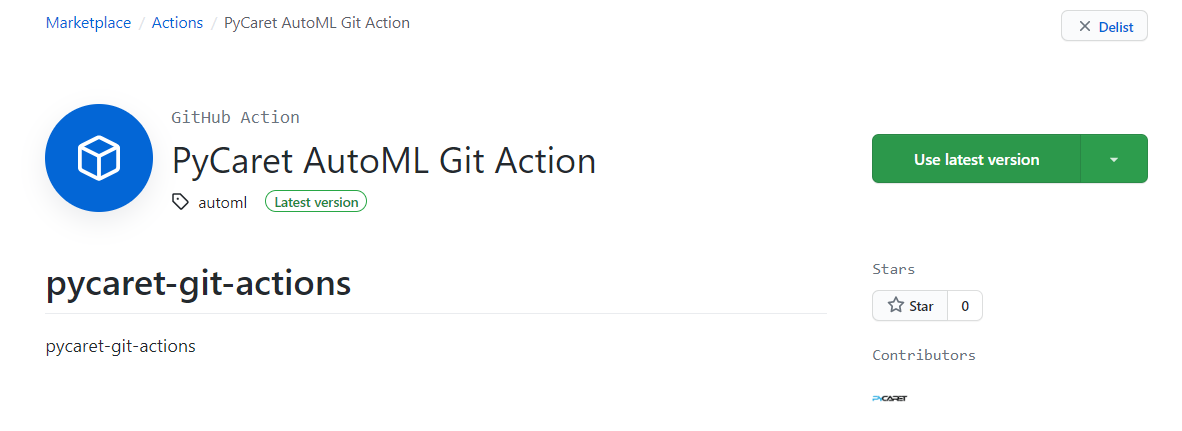
发布后,单击“release”,然后单击“Marketplace”:
单击“Use latest version”:
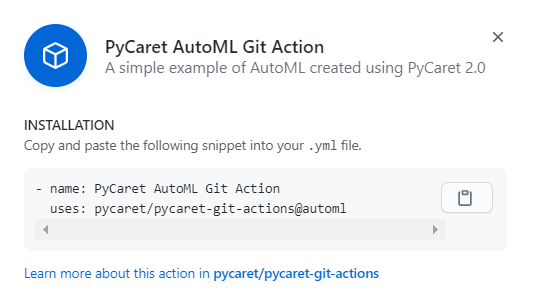
保存此信息,这是软件的安装详细信息。在任何公共GitHub存储库上安装此软件时,你需要这样做:
步骤5-在GitHub存储库上安装软件
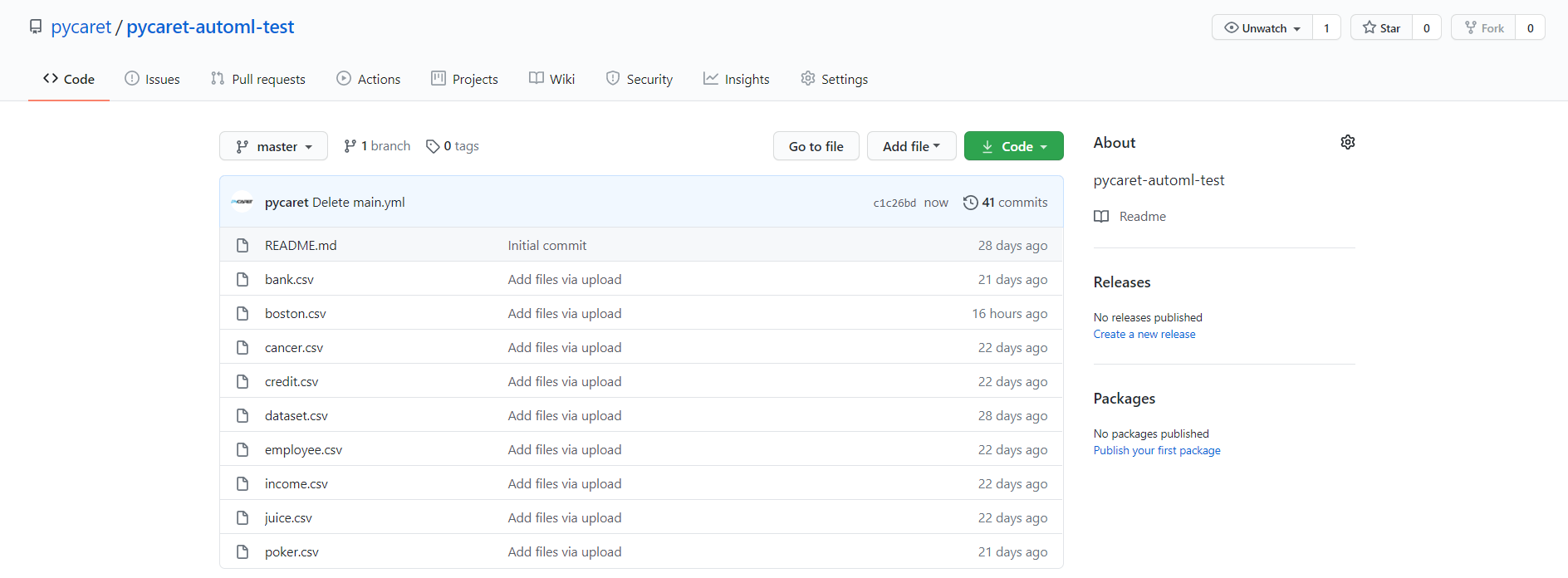
为了安装和测试我们刚刚创建的软件,我们创建了一个新的存储库pycaret-automl-test:https://github.com/pycaret/pycaret-automl-test,并上传了一些用于分类和回归的示例数据集。
要安装我们在上一步中发布的软件,请单击“Actions”:
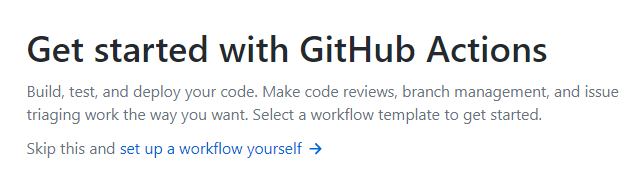
单击“set up a workflow yourself”并将你的脚本复制到编辑器中,然后单击“Start commit”。
开始提交后,单击“actions”:
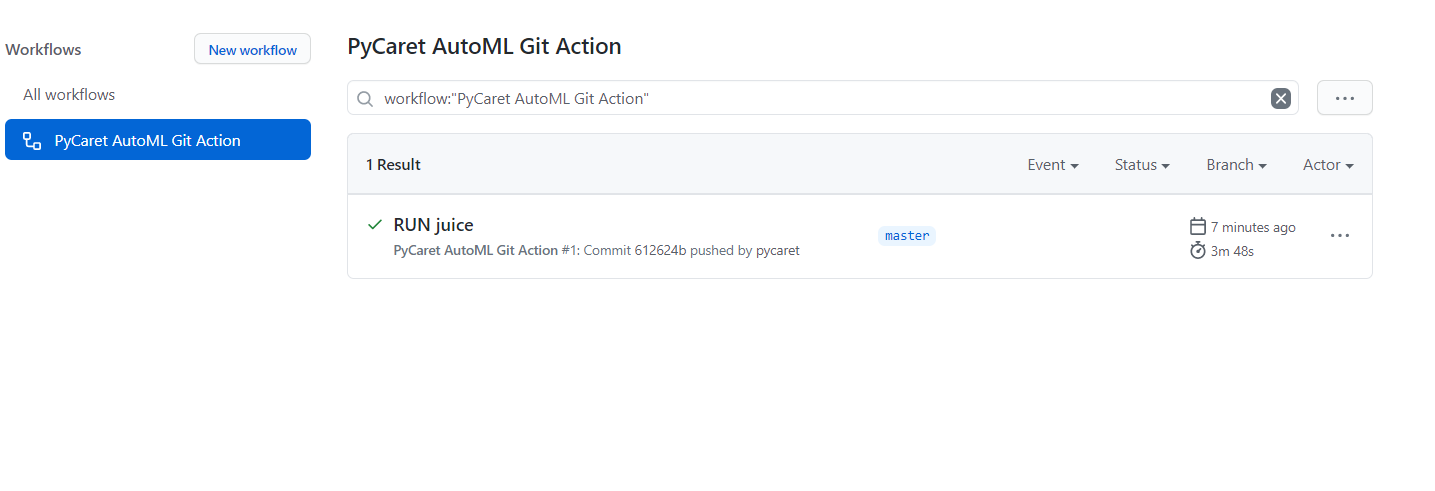
在这里,你可以在生成时监视生成的日志,并且一旦工作流完成,你也可以从此位置收集文件。
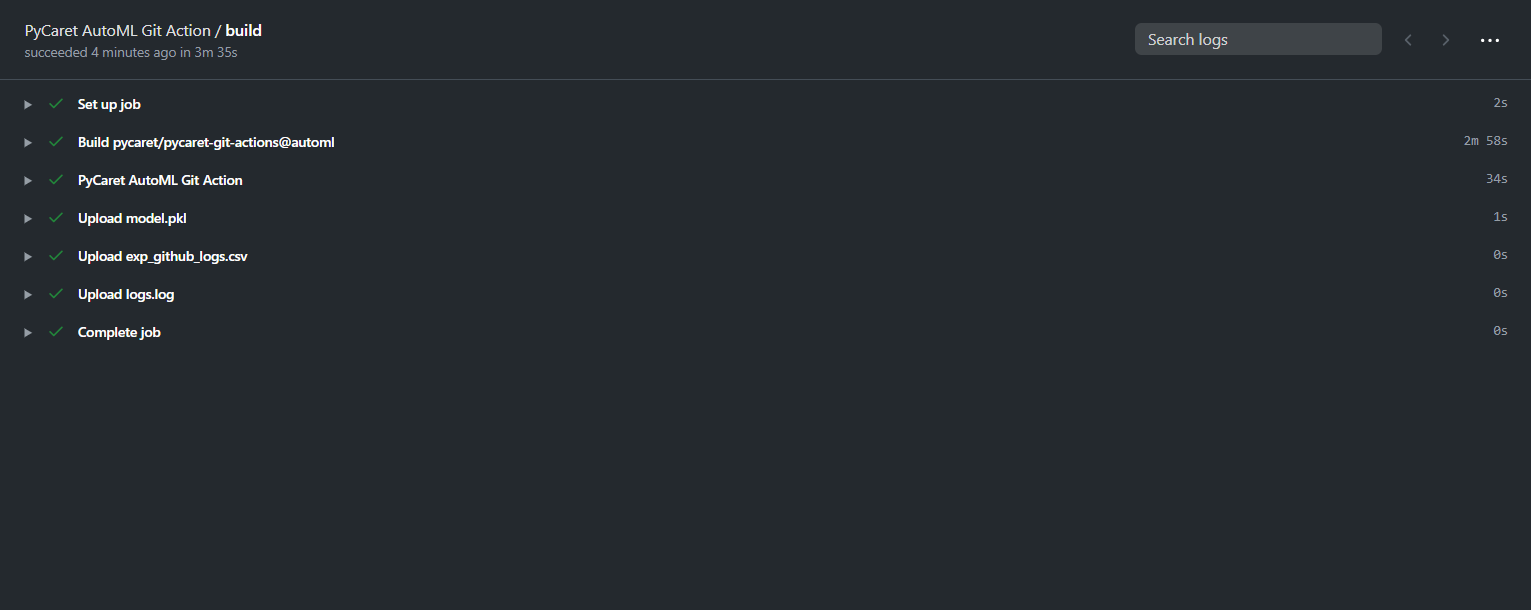
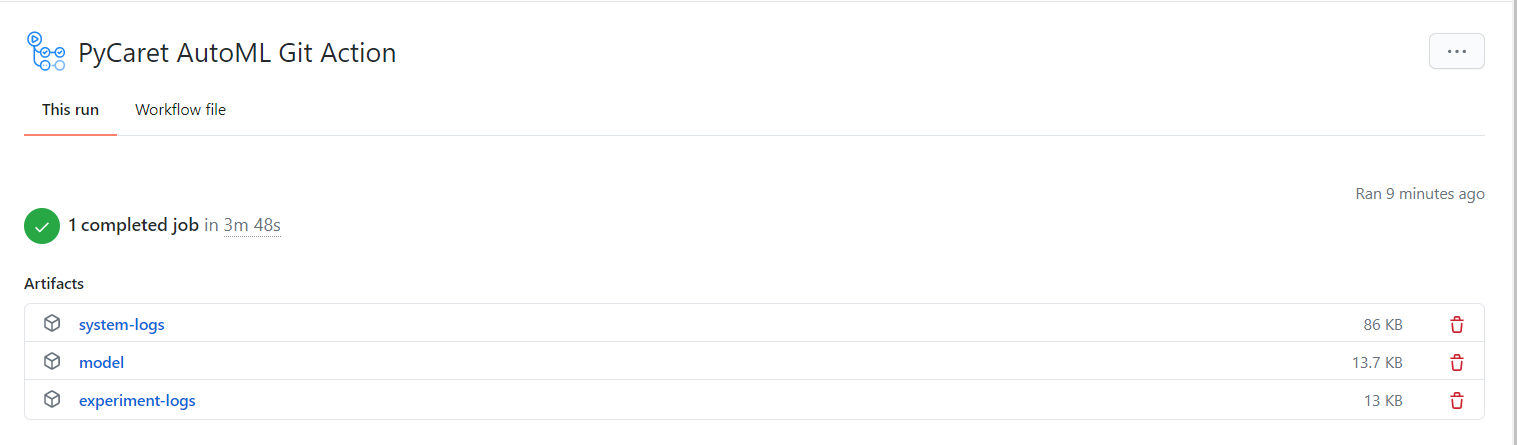
你可以下载这些文件并将其解压缩到你的设备上。
文件:model
这是最终模型的.pkl文件以及整个转换管道。你可以使用此文件使用predict_model函数在新数据集上生成预测。要了解更多信息,请单击此处:https://www.pycaret.org/predict-model
文件:experiment-logs
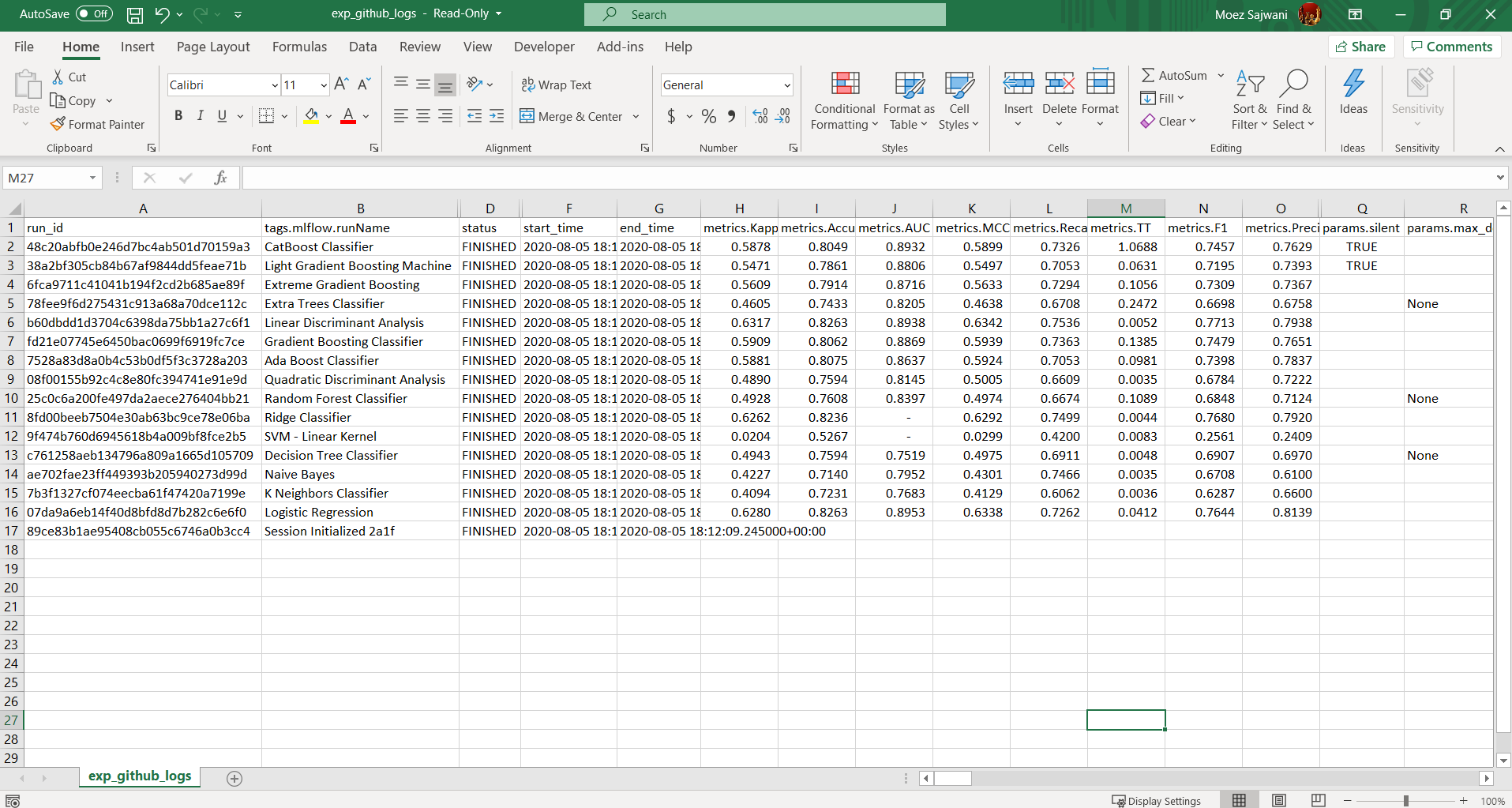
这是一个.csv文件,其中包含了模型所需的所有详细信息。它包含了在app.py中所有接受过训练的模型,它们的性能指标,超参数和其他重要的元数据。
文件:system-logs
这是PyCaret生成的系统日志文件。这可用于审核流程。它包含重要的元数据信息,对于解决软件中的错误非常有用。
本教程中使用的存储库:
https://github.com/pycaret/pycaret-git-actions
https://github.com/pycaret/pycaret-automl-test
在Python中使用这个轻量级的工作流自动化库可以实现的目标没有限制。如果你觉得这个有用,请别忘了给我们我们的github项目star⭐️。
想了解更多关于PyCaret的信息,请访问LinkedIn和Youtube。
LinkedIn:https://www.linkedin.com/company/pycaret/
Youtube:https://www.youtube.com/channel/UCxA1YTYJ9BEeo50lxyI_B3g
如果你想了解更多关于PyCaret 2.0的信息,请阅读本公告。如果你以前使用过PyCaret,那么你可能会对当前版本的发行说明感兴趣。
想了解特定模块吗
单击下面的链接查看文档和工作示例。
- Classification:https://www.pycaret.org/classification
- Regression:https://www.pycaret.org/regression
- Clustering:https://www.pycaret.org/clustering
- Anomaly Detection:https://www.pycaret.org/anomaly-detection
- Natural Language Processing:https://www.pycaret.org/nlp
- Association Rule Mining:https://www.pycaret.org/association-rules
原文链接:https://towardsdatascience.com/github-is-the-best-automl-you-will-ever-need-5331f671f105
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/09/01/github%e4%b8%8a%e7%9a%84automl/
