
使用Keras进行深度学习:(二)CNN讲解及实践
本文是全系列中第9 / 9篇:Keras 从入门到精通
笔者:Ray
现今最主流的处理图像数据的技术当属深度神经网络了,尤其是卷积神经网络CNN尤为出名。本文将通过讲解CNN的介绍以及使用keras搭建CNN常用模型LeNet-5实现对MNist数据集分类,从而使得读者更好的理解CNN。
1.CNN的介绍
CNN是一种自动化提取特征的机器学习模型。首先我们介绍CNN所用到一些基本结构单元:
1.1卷积层:在卷积层中,有一个重要的概念:权值共享。我们通过卷积核与输入进行卷积运算。通过下图可以理解如何进行卷积运算。卷积核从左到右对输入进行扫描,每次滑动1格(步长为1),下图为滑动一次后,卷积核每个元素和输入中绿色框相应位置的元素相乘后累加,得到输出中绿色框中的0。一般会使用多个卷积核对输入数据进行卷积,得到多个特征图。
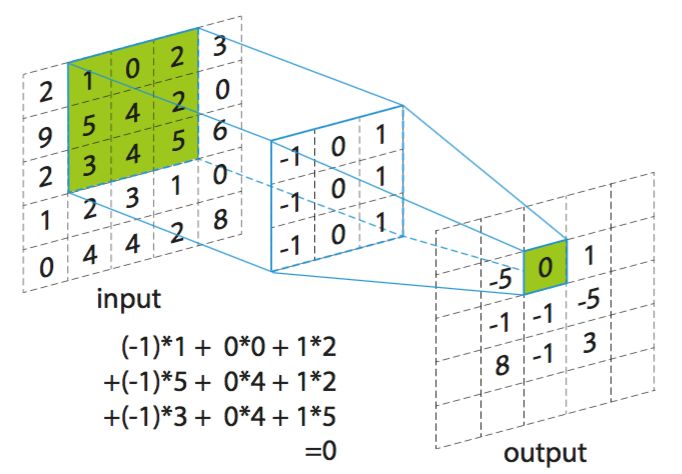
图1:卷积运算
1.2激活层:对卷积层的输出进行一个非线性映射,因为卷积计算是一种线性计算。常见的激活函数有relu、tanh、sigmoid等,一般使用relu。
1.2.1引入非线性激活函数的原因:
如果不引入非线性映射的话,无论有多少层神经网络,输出都是输入的线性组合,这与一层隐藏层的效果相当。
1.2.2一般使用relu的原因:
在反向传播计算梯度中,使用relu求导明显会比tanh和sigmoid简单,可以减少计算量。
同时,使用tanh和sigmoid,当层数较多时容易导致梯度消失,因为tanh和sigmoid的导数均小于1(可参考激活函数的导数公式),当我们神经网络有多层的时候,每层都要乘以这个小于1的导数,就有可能接近于0,这就是所谓的梯度消失。而使用relu求导,若输出不为0时,导数均为1,可以有效避免梯度消失问题。
另外,relu还会将小于0的映射为0,使得网络较为稀疏,减少神经元之间的依赖,避免过拟合。
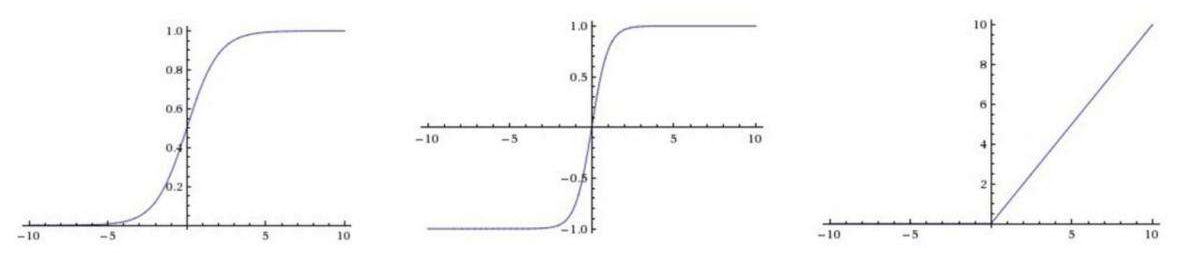
图2:从左到右依次为sigmoid、tanh、relu激活函数
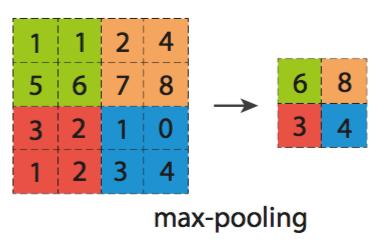
池化层:池化的目的就是减少特征图的维度,减少数据的运算量。池化层是在卷积层之后,对卷积的输出,进行池化运算。池化运算,一般有两种MaxPooling和MeanPooling。选取一个池化窗口(一般为2*2),然后从左往右进行扫描,步长一般为2。如下图MaxPooling操作,选取池化窗口中最大值作为该位置的输出。如:左边绿色方框中四个特征值中,选取最大的6作为输出相应位置的特征值。而MeanPooling则是对于池化窗口中的特征值求平均。
全连接层:主要是对特征进行重新的拟合,减少特征信息的丢失。通过卷积池化操作后得到的是多个特征矩阵,而全连接层的输入为向量,所以在进行全连接层之前,要将多个特征矩阵“压平”为一个向量。
对于CNN的卷积、池化操作,其实很多文章都会详细的介绍,但卷积和池化的意义是什么,很多文章都没有明确给出解释。可能会有人认为卷积和池化可以很大程度的减少权重参数,但只是因为这个原因吗?显然不是的,接下来将讲解CNN是如何实现有效的分类从而理解卷积和池化的意义。
用深度学习解决图像识别问题,从直观上讲是一个从细节到抽象的过程。所谓细节,就是指输入图像的每个像素点,甚至像素点构成的边也可以理解为是细节。假设我们大脑接收到一张动物图,大脑最先反应的是该图的点和边。然后由点和边抽象成各种形状,比如三角形或者圆形等,然后再抽象成耳朵和脸等特征。最后由这些特征决定该图属于哪种动物。深度学习识别图像也是同样的道理。这里关键的就是抽象。何为抽象呢?抽象就是把图像中的各种零散的特征通过某种方式汇总起来,形成新的特征。而利用这些新的特征可更好区分图像类别。如刚才这个例子,点和边就是零散的特征,通过将边进行汇总我们就得到了三角形或圆形等新的特征,同理,将三角形这个特征和一些其他零散的特征汇总成耳朵这个新特征。显而易见,耳朵这个新特征会比三角形特征更利于识别图像。
深度学习正是通过卷积操作实现从细节到抽象的过程。因为卷积的目的就是为了从输入图像中提取特征,并保留像素间的空间关系。何以理解这句话?我们输入的图像其实就是一些纹理,此时,可以将卷积核的参数也理解为纹理,我们目的是使得卷积核的纹理和图像相应位置的纹理尽可能一致。当把图像数据和卷积核的数值放在高维空间中,纹理等价于向量,卷积操作等价于向量的相乘,相乘的结果越大,说明两个向量方向越近,也即卷积核的纹理就更贴近于图像的纹理。因此,卷积后的新图像在具有卷积核纹理的区域信号会更强,其他区域则会较弱。这样,就可以实现从细节(像素点)抽象成更好区分的新特征(纹理)。每一层的卷积都会得到比上一次卷积更易区分的新特征。
而池化目的主要就是为了减少权重参数,但为什么可以以Maxpooling或者MeanPooling代表这个区域的特征呢?这样不会有可能损失了一些重要特征吗?这是因为图像数据在连续区域具有相关性,一般局部区域的像素值差别不大。比如眼睛的局部区域的像素点的值差别并不大,故我们使用Maxpooling或者MeanPooling并不会损失很多特征。
2项目实例
2.1模型介绍
有了上文对CNN的讲解后,读者对CNN应该有了一定的理解,接下来我们将基于此搭建CNN常见模型LeNet-5模型,并对Mnist数据集进行预测。
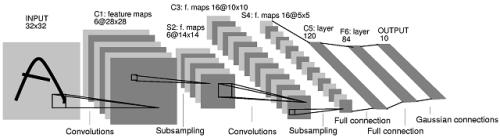
图3:LeNet-5模型
从上图LeNet-5模型中,可以了解到该模型由以下结构组成:
第一层:卷积层
这一层的输入的原始的图像像素,该模型接受的图像为32321,6个5*5卷积核,步长为1,不使用全0填充。所以这层输出的尺寸为32-5+1=28,深度为6。
第二层:池化层
该层的输入为第一层的输出,是一个28286的节点矩阵。本层采用的过滤器大小为22,长和宽的步长均为2,所以本层的输出矩阵大小为1414*6。
第三层:卷积层
本层的输入矩阵大小为14146,16个55卷积核,同样不使用全0填充,步长为1,则本层的输出为1010*16。
第四层:池化层
该层使用22的过滤器,步长为2,故本层的输出矩阵为55*16。
第五层:全连接层
如上文所说,在全连接层之前,需要将5516的矩阵“压扁”为一个向量。本层的输出节点个数为120。
第六层:全连接层
该层输出节点个数为84。
第七层:全连接层
最后一层,输出节点个数为10,样本的标签个数。
2.2代码实现
2.2.1数据导入及处理
Mnist数据集为手写字体,训练集有60000张图片,测试集中有10000张图片,标签为0-9。由于Mnist数据集为IDX文件格式,是一种用来存储向量与多维度矩阵的文件格式,不能直接读取。有两种方式可以进行读取。第一种是Keras.datasets库中有mnist数据集,直接调用即可,但是由于需要Keras指定地址下载数据集,速度较慢,最好先下载;第二种是使用struct库函数解析数据集,比较麻烦,但是也可以试试。

图4:导入Mnist数据集
对于mnist数据集只是做了一些简单的预处理,将输入数据的数据类型转换为float32,并进行归一化。对标签进行独热编码,因为最后输出节点个数为10,而标签只有1维。
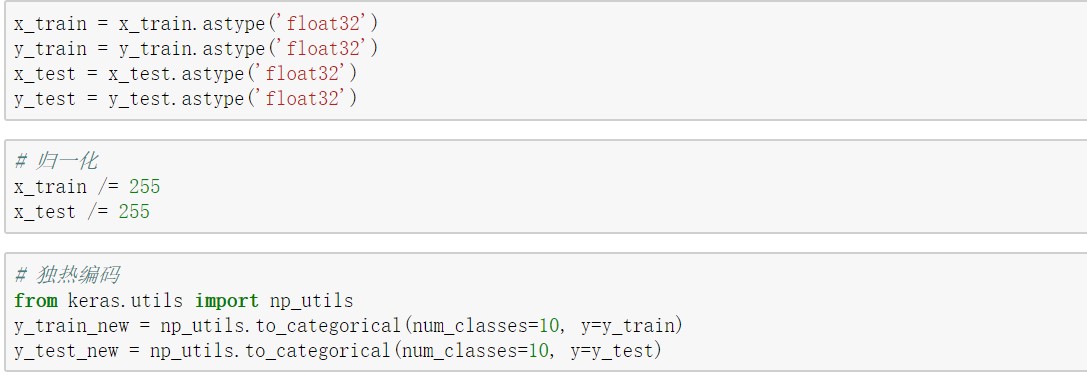
图5:数据预处理
2.2.2LeNet-5模型的搭建

图6: Keras搭建LeNet-5模型
2.2.3训练模型

图7:训练模型
2.2.4 评估模型

图8:评估模型
最终在测试集的准确率可以达到99.7%。
通过一个简单项目的实现,既可以帮助我们进一步了解CNN,又可以熟悉Keras应用。最终模型还可以保存到本地,便于下次使用。

图9:保存和读取模型
3.迁移学习
迁移学习就是把已训练好的模型参数迁移到新模型来帮助新模型训练。考虑到大部分数据或任务存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数通过某种方式来分享给模型从而加快训练模型。
keras.applications库中有许多已经训练好的模型,我们可以对已有的模型进行一些修改得到我们想要的模型,从而提高模型搭建和训练的效率。另外,当我们的数据不足的时候,使用迁移学习思想也是一个很好的想法。在下图,将简单的通过迁移学习实现VGG16。但是由于VGG16模型要求输入为RGB图像,所以需要使用opencv模块对图像进行处理。
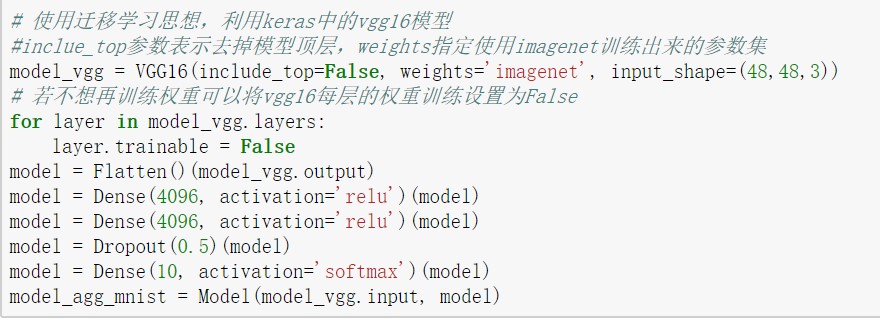
图10:通过迁移学习高效搭建vgg16模型
通过上图,可以看出通过迁移学习我们可以省去搭建多个卷积和池化层,并且可以省去训练参数的时间,vgg16有3364万个网络权重,如果全部重新训练将需要一段较长的时间。是否重新训练网络权重参数,要取决于我们要所用的数据集的分布与原模型所使用的数据集的分布是否具有相关性。因为模型训练是让模型学习数据的分布,如果不具有相关性,已有的网络权重并不适合于我们的数据集。
欢迎关注我们的网站:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!
原创文章,作者:Ray,如若转载,请注明出处:https://panchuang.net/2018/03/22/cnn/
