
摘要:什么是深度学习?计算机视觉?物体检测?
深度学习是机器学习的一个子领域,它关注的是受大脑结构和性能启发的复杂算法,称为人工神经网络。
为了解决我们的问题,我们使用DL模型,特别是包含在计算机视觉(CV)领域内的目标检测模型。目标检测的目标是复制人类在识别不同目标时的表现。
识别图像中的对象的任务包括输出单个对象的边界框和标签。在我们的例子中,我们的数据集有两类,有丝分裂和不有丝分裂(背景),其中边界框只包含有丝分裂细胞边界。
简单地说,我们的目标检测神经网络由目标区域选择器(例如滑动窗口)、特征提取器(卷积神经网络(CNN)的级联)和两个输出算法组成,分类算法推导检测对象的类别,回归模型生成包围检测细胞的矩形的最佳尺寸。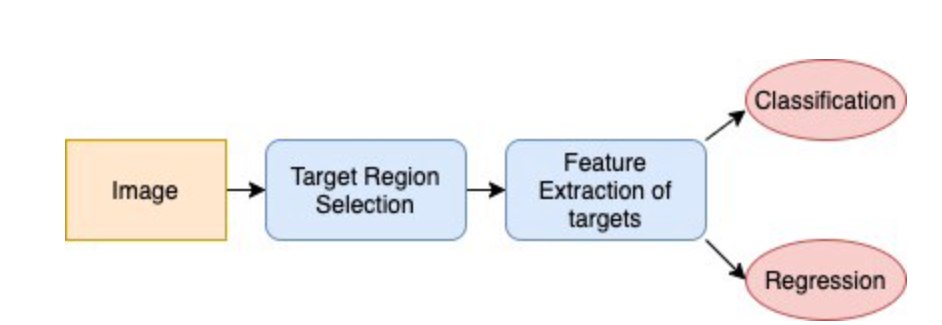
正如在第1部分中提到的,我们筛选了Mitos数据集,只保留那些包含有丝分裂细胞的注释,置信度大于或等于0.65。Part1
值得一提的是,有丝分裂细胞在帧中并不常见,因为在x40倍率下,每帧最多有三个有丝分裂细胞。这假设了对我们的模型训练的限制,因为只考虑原始帧(所有的x40放大倍率),我们将无法正确地训练算法,因为它将没有足够的信息来提取有丝分裂细胞的质量。
为此,我们解决了在通过随机瓦片生成使用图像增强创建更大的数据集时的训练问题。为此,我们创建了一个名为TileGenerator的类,它为每帧中的每个记录生成包含有丝分裂细胞的N个瓦片和不包含有丝分裂细胞的N个瓦片(通过记录每个帧的有丝分裂细胞注释来理解)。为此,每个映像的主要步骤为:
(1)创建一个Frame实例,其属性包含图像的主要信息(图像本身、高度、宽度和深度、每个记录要生成的瓦片数量和有丝分裂细胞的位置(称为记录))
(2)调用Frame类的三个主要方法:
(2.1)Get_Record:将所有记录作为每个帧的属性追加,其中记录属于收集置信度和绝对位置(x和y坐标)信息的类记录
(2.2)GET_MASK:生成一个二进制掩码,该掩码等于记录位置中的1加上128个像素的填充。此掩码用于确定创建的未有丝分裂瓷砖是否包含有丝分裂细胞,并丢弃确实包含有丝分裂细胞的瓷砖。
(2.3)GET_ALL_TILES:它从TileGenerator类和两个主要方法为每个记录创建一个Tile实例来辅助自身:
- Generate_Positive_Patches:创建包含有丝分裂细胞的N个平铺。为此,围绕框架的特定记录随机选择坐标,然后检查记录是否包含在平铺中,最后我们检查框架的任何其他记录是否包含在平铺中。最后,此单元格在平铺中位置的相对信息作为记录存储在框架的平铺属性内。

- Generate_Negative_Patches:创建不包含有丝分裂细胞的N个平铺。提出并检查随机坐标对以查看二进制掩模中的坐标是否等于0,这意味着中心点和周围的128个像素不包含有丝分裂的细胞。
正是从这个包含有丝分裂相对位置的平铺信息中,为后继训练步骤创建Pascal VOC格式的CVS注释,特别是用于创建tfRecords,tfRecords是将您的数据存储为二进制字符串序列的文件,并且对于训练大型、重型数据集很有用。
这些Pascal VOC注释的一个示例是:
#第二步:模特培训
为了训练模型,我们使用了Google Colab和Tensorflow2对象检测API。
必须相应地为所需的依赖项设置环境,然后我们必须下载并安装TensorFlow对象检测API,并通过挂载Google Drive的内容来检索我们的数据集。我们还提供了一个YAML文件,其中包含在本地运行模型所需的所有库和版本。
2.生成TfRecords
培训之前的tfRecords的生成是使用Google提供的脚本的修改版本来完成的,该脚本用于将Pascal VOC格式注释转换为可以直接输入到模型中的tfRecords。
3.下载模型并进行迁移学习。
在这一部分的第一步之后,我们在我们的系统中保存了适用于不同计算机视觉任务的多个预先训练的模型。然而,并不是所有的Tensorflow2都能正常工作,Tensorflow2后来在推理过程中出现了问题。最后,我们选择使用SSD Mobilenet V2fpnlite 320×320作为基本型号。
如前所述,基本模型的权重(特征提取器)被冻结,因此在训练期间只更新分类和回归模型上的权重。这个过程被称为模型的微调,它允许像我们这样资源有限的小团队使用在庞大的数据集上预先训练的最先进的模型,否则这些模型是无法访问的。
4.对模型进行训练并导出以供推理。
最后一个阶段是训练模型本身,这是通过一个稍加修改的.config文件创建的,该文件允许模型访问我们在Google Drive中的输入文件并输出已经训练好的模型。训练完成后,导出新的推理图,以便可以用于推理。
#第三步:模型推理
对于模型推理,我们的模型的权重经过微调以满足我们的任务,首先从驱动器中恢复,然后与模型从未见过的新图像一起使用。在这个阶段不涉及任何培训。
在获得新图像作为输入之后,我们在一个函数中运行模型,该函数将收集我们实现目标所需的数据。
Run_Inference_for_Single_Image()。该函数扫描整个图像,并输出关于在图像上发现了多少有丝分裂细胞的注释,以及模型对每个预测的置信度。这可以作为第一个过滤来对属于癌症风险高或低的个人的任何给定图像进行分类。这可以帮助早期诊断,加快检查病理图像的整个过程,并有助于提高不同国家卫生系统的效率。
最后,应该建立一个完整的管道,让整个过程对最终用户来说容易和直接,这样这种模式才能真正被医生使用。
未来的步骤
该项目只是将AI工具纳入医学领域的一小步。我们的主要目的是让人们意识到AI/DL工具的存在和潜力,并消除对这些方法的所有恐惧和不确定性。值得一提的是,这些工具本身并不起作用,总是需要从人的角度来理解它们。
话虽如此,这种工具产生影响的可能性是无穷无尽的。特别是在这个领域,研究一下会很有趣:
- 使用生成对抗性网络(GAN‘s)(其中两个神经网络相互竞争以提高其预测的准确性的机器学习(ML)模型)的强度归一化技术来帮助解决处理具有不同颜色染色的组织病理图像的问题。
- 预测癌症的整体情况,而不仅仅是乳房组织。
- 预测其他癌症体征,如核异型性,作为确认癌症存在的补充
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/18/paithology%ef%bc%9a%e6%97%a9%e6%9c%9f%e4%b9%b3%e8%85%ba%e7%99%8c%e8%af%8a%e6%96%ad%e7%9a%84%e4%ba%ba%e5%b7%a5%e6%99%ba%e8%83%bd%e5%b7%a5%e5%85%b7%e7%ac%ac2%e9%83%a8%e5%88%86%ef%bc%9a%e7%9c%9f/
