
第二部分通过语义切分来检测项目缺陷。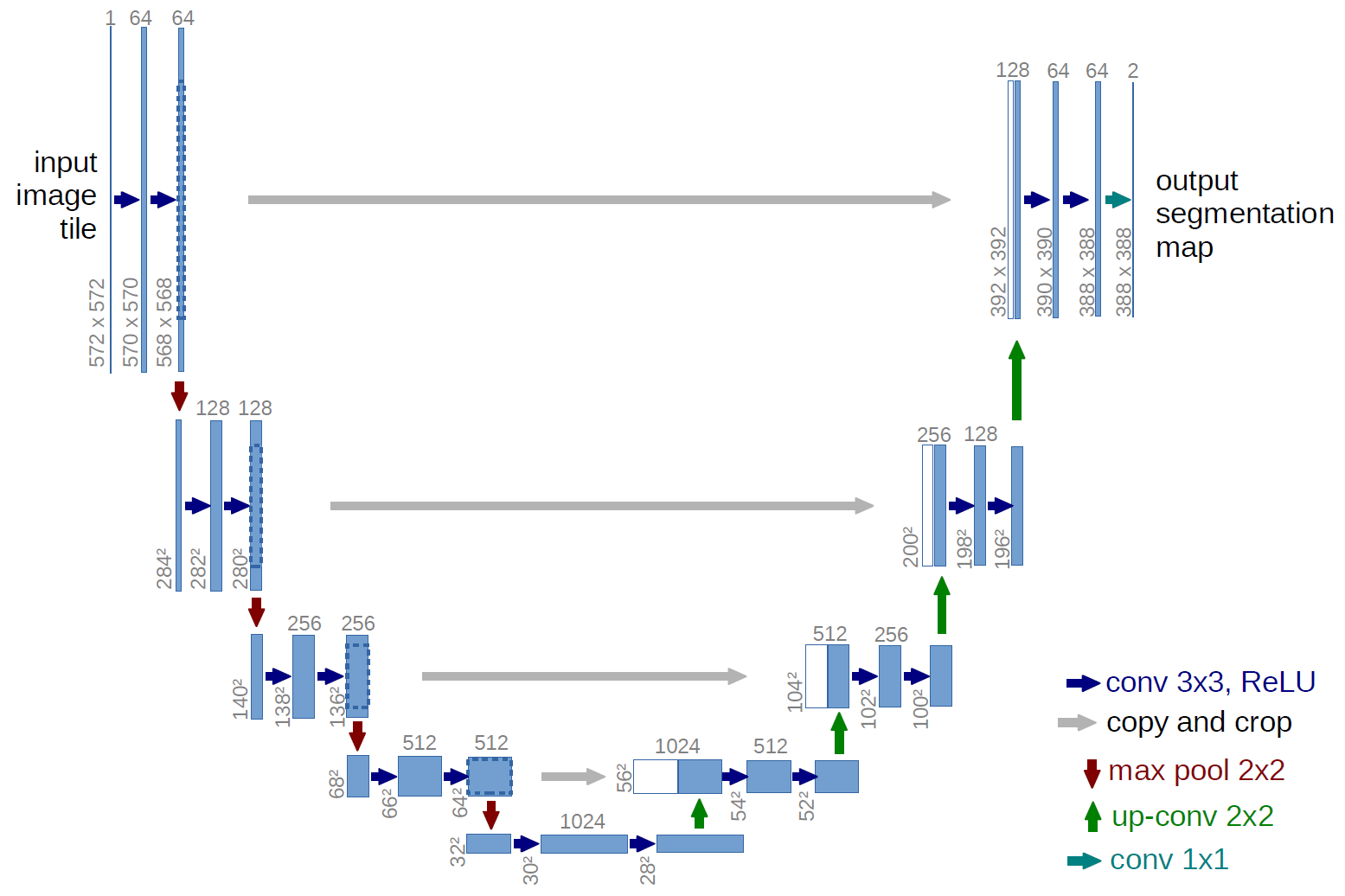
简化的UNET架构:
让我们从实施组成UNET的各个模块开始:
Python实现:
def conv_block(input, num_filters):模型架构:
- 五个编码器步骤系统地将输入尺寸减半,同时使通道加倍。
- 然后是没有下采样的卷积挡路。
- 接着是五个上采样步骤,最终得到与输入图像相同但具有32个通道的尺寸。
- 最后与1个过滤进行1×1卷积,构建输入图像。
- 最后一层将具有sigmod激活,以便输出每个像素有缺陷的概率,而不是输出像素本身。
Python实现:
def uNetModel(input_shape):数据准备
我使用的数据集是MVTEC数据集的子集。
文件夹结构如下所示:
- mvtec
- images
- bent
- color
- flip
- scratch
- good请注意,我们没有“好”图像的注释-因为没有像素是有缺陷的,我们可以使用与图像相同的维数“零”数组自己构建掩模。
我们将首先创建一个函数来读取路径、读取该路径上的二进制数据、将二进制数据解码为图像、执行大小调整和标准化:
from random import shuffle
import tensorflow as tf
from pathlib import Path
import numpy as np
import sys这里有一种简单的方法,可以在指向文件夹时构建其内容的路径对象数组-
from pathlib import Path我们需要这个列表是路径字符串-
goodImgs = list(map(lambda x: str(x), goodImgs))TensorFlow“DataSet”具有映射功能,当我们需要对每条记录系统地执行某些操作时,该功能可以有效地利用并行化。所以,
import tensorflow as tf为了使我们正在准备的数据具有可重用性,在我们调优模型时,让我们将数据集转换为数字数组,这样我们就可以保存到文件中
dsImgs1 = np.array(list(dsImgs1))如前所述,我们将创建数字“零”数组的掩码:
dsMsks1 = np.zeros([dsImgs.shape[0], 224, 224, 1])对其他文件夹中的缺陷图像重复上述步骤:
需要注意的一个重要区别是,在我们将每个文件夹项目添加到主路径列表之前,对它们的路径列表进行了“排序”操作。为什么是必需的?
因为,我们希望两个列表中的图像和蒙版按索引位置相互对应。
imgPaths = []
mskPaths = []现在我们已经有了好的和坏的项目的图像和掩码,我们可以将它们堆叠在一起成为单个数据集。
dsImgs = np.vstack((dsImgs1, dsImgs2))
dsMsks = np.vstack((dsMsks1, dsMsks2))增强
在执行增强之前,因为我们将数据保持在排序的顺序中,所以我们需要混洗。然而,有一个挑战-即使在洗牌之后,图像和面具也应该按索引匹配。因此,让我们编写几个函数:
请注意,它不是训练、测试和验证集的长度,而是要拆分的索引位置。
from random import shuffle2.给定置乱索引和分割索引以及原始数据集,以下函数返回实际分割的数据集
def splitData(idxList, images, masks):
splitDS = list()
for i in range(len(idxList)):
splitDS.append(images[idxList[i]])
splitDS.append(masks[idxList[i]])
return splitDS执行拆分-
trnIdx, valIdx, tstIdx = getIdxs(len(dsImgs), [60, 85])
trImgs, trMsks, vlImgs, vlMsks, tsImgs, tsMsks = splitData([trnIdx, valIdx, tstIdx], dsImgs, dsMsks)现在我们准备好增强列车图像和面具。Tensorflow的ImageDataGenerator是一种简单的方法。
from tensorflow.keras.preprocessing.image import ImageDataGenerator我们用来增加图像和蒙版的TensorFlow图像生成器对象随机执行此操作,因此我们将相同的“种子”值传递给图像增强器和蒙版增强器。因此,每当图像以某种方式增加时,蒙版也会以完全相同的方式增加。
损失函数和度量
对于损失函数,我们有多种选择–二进制交叉点损失、焦损和骰子损失,仅举几例。
我们将使用修改的骰子损失,当二进制掩模中的掩模区域与整个图像的比例明显较小时,这种方法效果特别好。
def custom_loss(y_true, y_pred):与损失函数类似,我们有多个度量可供选择。
在这种情况下,准确性是一个糟糕的指标。因为-
- 我们正在对每个像素进行二进制预测。
- 所有图像中只有一部分是有缺陷的。
- 即使在那些有缺陷的图像中,有缺陷的像素数也是整个图像的一部分。
- 所有这一切都转化为正确识别所有图像的所有像素数总和的10%的问题陈述。
- 因此,即使我们采用的模型对于每个像素只输出‘0’,我们仍然有一个90%的精确模型。
PRAUC、Recall和Precision是我们将使用的。
metrics=[ tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall'),
tf.keras.metrics.AUC(name='prc', curve='PR')]模范训练
编译模型
model = uNetModel()
model.compile(optimizer=tf.keras.optimizers.Adam(),loss=custom_loss,
metrics=metrics)训练模型
BATCH_SIZE = 16
STEPS_PER_EPOCH = len(trImgs) // BATCH_SIZE
VAL_BAT_SIZE = len(vlImgs) // STEPS_PER_EPOCH
模型评估
可视化培训指标并验证模型性能:
import matplotlib.pyplot as plt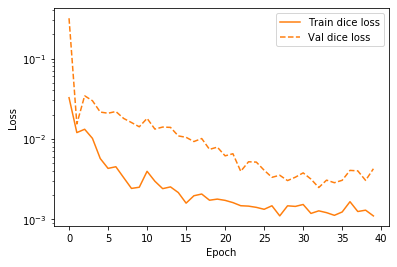
测试模型
from random import sample

原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/19/%e7%a7%91%e6%8b%89%e6%96%af%e7%9a%84unet%e3%80%82/
