
人工智能

想象你在另一个国家度假,在那里你不会说当地的语言。你想尝尝当地的餐厅,但他们的菜单上有你不会说的语言–™。我认为这不会太难想象,因为我们大多数人都已经遇到过这种情况,无论你看到菜单项或说明,你都无法理解™™写的是什么。嗯,在2020年,你会拿出手机,谷歌翻译你看到的东西。到了2021年,你甚至不再需要打开谷歌翻译(™),试着把你看到的逐个写出来进行翻译。取而代之的是,你可以简单地使用Facebook AI的这个新模型,将图像中的每个文本都翻译成你自己的语言!这甚至不是这项技术的主要应用,但即使这样也很酷。更酷的是,他们的翻译工具竟然使用了与深度假货类似的技术,按照与原文相同的风格更改图像中的单词!
以一个单词为例,它可以从任何图片中复制文本的样式!就像这样?欧元?
这对于增强现实中的照片真实感语言翻译来说是令人惊叹的。这是™为这项任务发布的第一篇关于这样一个模型的论文,它基于他们发布的新数据集,而且已经相当令人印象深刻了!这对于视频游戏或电影来说可能是令人惊叹的,因为你将能够超级容易地翻译出现在建筑物、海报、标志等上的文本,使得基于所选语言的沉浸对每个人来说更加个性化和令人信服,而不必手动PS每一帧或完全重新制作场景。如您所见,它也适用于使用单个单词的手写。它能够从一个单词例子中概括出来,并复制它的风格,这就是这个新的人工智能模型给人留下如此深刻印象的原因。事实上,它不仅能理解文本的排版和书法,而且还能理解它出现的场景,无论是出现在曲线海报上的还是来自不同背景的™。
典型的文本传输模型以一种特定的风格以有监督的方式进行训练,并使用带有文本分割的图像。这意味着您需要知道图片中的每个像素是什么,无论它是不是文本,这是非常昂贵和复杂的。取而代之的是,他们使用一个自我监督的训练过程,在这种过程中,文本的样式和分割不会在训练期间给予模型™。只给出了实际的单词内容。我说他们发布了这个模型的数据集,它只需要一个词就能做到这一点。这是因为在训练过程中,模型首先通过许多示例学习在这个新数据集上完成任务的一般方法。该数据集包含大约9000个文本图像,这些图像位于不同的表面,其中只有单词注释。
然后,它使用输入图像中的新词来学习它的风格,我们称之为“EUROUREœOne-Shot-Transfer”EUROURE�方式。这意味着,仅从一个包含要更改的单词的图像示例中,它将自动调整模型以适合任何其他单词的确切样式。正如您所知道的,这里的目标是将出现在图像上的文本的内容解开,然后在新文本上使用这个文本-欧元™的样式,并将其放回图像上。这个将文本从实际图像中分离出来的过程是以自我监督的方式学习的,我们稍后将会看到。简而言之,我们将图像作为输入,并创建一个仅包含翻译后的文本的新图像。
™给人的感觉是不是就像给你的脸拍张照片,只是改变它的特定特征来匹配另一种风格,就像我上周发表的那篇关于发型的文章一样?如果你还记得的话,我说过这和深伪的工作原理非常相似。这意味着,还有什么比StyleGan2更好的做法呢?StyleGan2是从另一个图像生成图像的最佳模型。the article I published last week on hairstyles
现在,让我们来看看™是如何实现这一目标的,也就是培训过程。他们使用预先训练的字体分类网络和文本识别网络来训练该模型以测量其在这些未标记图像上的性能。这就是为什么它是以自我监督的方式学习的,因为它不能直接获得关于输入图像的标签或基本事实。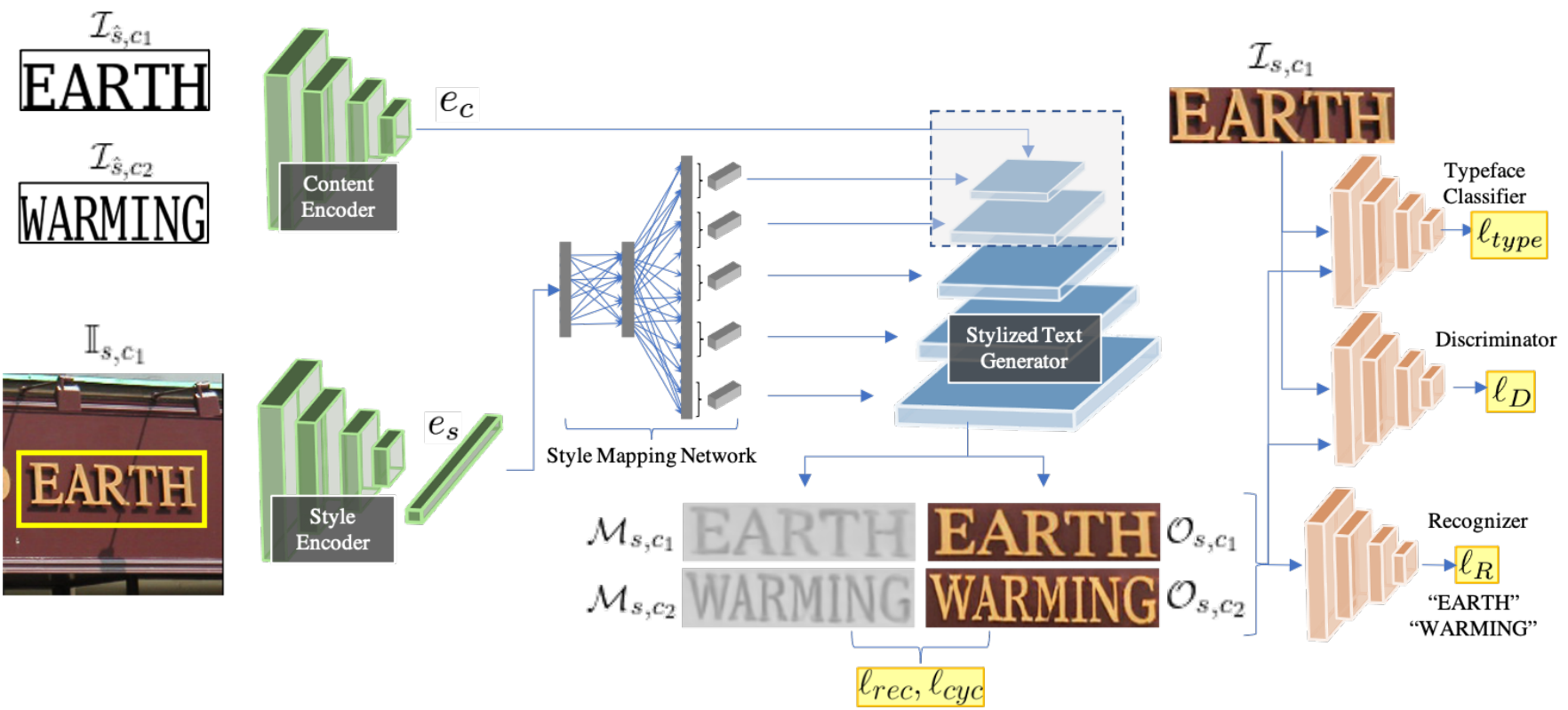
这一点,再加上对生成的图像与新文本与输入图像进行比较时计算的真实感度量,允许在没有监督的情况下训练模型,其中我们准确地告诉它图像中有什么,旨在获得照片级的逼真和准确的文本结果。这两个网络都将通过首先检测图像中的文本(这将是我们的基本事实),然后将新文本与我们想要写的内容及其字体与原始图像(Eurouro™的文本字体)进行比较,来判断生成的文本与其假设的距离有多近。使用这两个已经训练好的网络允许基于StyleGan的图像生成器在没有任何先前标签的图像上进行训练。然后,该模型可以在推理时使用,或者换句话说,在现实世界中,在没有我们讨论的另外两个网络的情况下,只通过训练的基于StyleGAN的网络发送图像,该网络生成具有修改后的文本的新图像。它将通过对文本风格和内容的单独理解来实现翻译。其中样式来自实际图像,内容是标识的字符串和要生成的字符串。在这里,我刚才提到的“EUROUREœUnderming”EUROURE�过程是每个过程的编码器,这里用绿色表示,将信息压缩成应该准确地表示我们从该输入中真正想要的信息的一般信息。然后,根据需要的细节,在基于图像StyleGAN的生成器(以蓝色显示)中,以不同的步骤发送这两个编码的一般信息。这意味着内容和样式是首先发送的,因为它需要翻译。然后,我们将使用在训练过程中学习到的最佳比例,以多个步骤将样式迭代地馈送到网络中,从而强制生成图像中的样式。这允许生成器控制文本外观的低分辨率到高分辨率的细节,而不是如果我们像通常那样仅将此样式信息作为输入发送,则仅限于低分辨率的细节。当然,为了适应一切并使其工作,还有更多的技术细节,但如果你想了解更多关于他们是如何在更多的技术方面实现这一点的信息,我会让你阅读下面参考文献中链接的他们的伟大论文。
我还想提一提,他们公开分享了一些复杂场景的问题,在这些场景中,照明或颜色变化会导致问题,损害真实感,就像我之前介绍的其他基于GAN的应用程序一样,将你的脸转换为卡通或改变图像的背景。看到这些限制是至关重要的,也是非常有趣的,因为它们将有助于加速研究。™说,“这是非常重要的,也是非常有趣的。”
以更积极的方式结束,这只是第一篇用这种程度的概括来攻击这项复杂任务的论文,它已经给人留下了极其深刻的印象。我等不及要看下一个版本了!
一如既往地,感谢您的阅读,我将在下一期节目中见到您!
观看视频
来我们的不和谐社区和我们聊天吧:一起学习人工智能,分享你的项目,论文,最好的课程,寻找Kaggle队友,等等!Discord community: Learn AI Together
如果你喜欢我的工作,想要了解最新的AI,你绝对应该在我的其他社交媒体账号(LinkedIn,Twitter)上关注我,订阅我的每周AI时事通讯!LinkedIn Twitter newsletter
来支持我:
- 支持我的最好方式是成为这个网站的成员,或者如果你喜欢我在YouTube上的频道,就订阅它。
- 在财务上支持我在Patreon上的工作
- 请在Medium上跟我来这里
参考文献
- Praveen Krishnan,Rama Kovvuri,Guan Pang,Boris Vassilev,和Tal Hassner,facebook AI,(2021年),âuro�TextStyleBrush:来自单一示例的文本美学的转移-Euro�,TextStyleBrush
- 脸书AI制造的数据集:https://github.com/facebookresearch/IMGUR5K-Handwriting-Dataset?fbclid=IwAR0pRAxhf8Vg-5H3fA0BEaRrMeD21HfoCJ-so8V0qmWK7Ub21dvy_jqgiVo
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/25/%e4%bb%8e%e6%a8%a1%e4%bb%bf%e6%a0%b7%e5%bc%8f%e7%9a%84%e5%9b%be%e5%83%8f%e7%bf%bb%e8%af%91%e6%96%87%e6%9c%ac%ef%bc%9atextstylebrush/
