
注:本博客试图解释描述深度学习模型Social-LSTM的研究论文。论文可以在这里找到。here
为什么选择社交LSTM
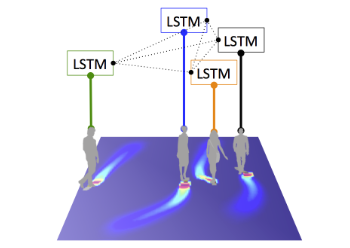
社会LSTM是一个模型,它预测行人的未来轨迹(我们可以为其他类型的对象的轨迹定制),给出他们过去的轨迹数据。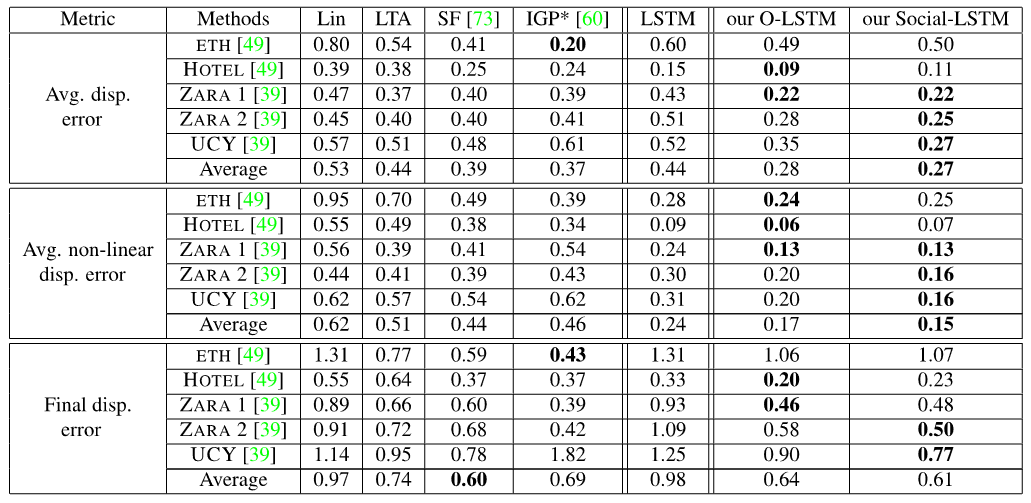
大多数早期的工作都受到以下两个假设的限制。
i)他们使用手工制作的函数来建模特定设置的“交互”,而不是以数据驱动的方式进行推断。这导致倾向于捕捉简单交互(例如,排斥/吸引)的模型,并且可能无法对更复杂、拥挤的设置进行泛化。
ii)他们专注于对彼此接近的人之间的互动进行建模(以避免立即发生碰撞)。然而,他们并没有预料到在更遥远的未来可能会发生的互动。
这就是Social LSTM填补空白的地方。
多么
该模型通过一种新颖的体系结构来模拟这一问题,该体系结构将对应于邻近序列的LSTM连接起来。特别是,它引入了一个“社会”池层,允许空间邻近序列的LSTM彼此共享它们的隐藏状态。该体系结构可以自动学习在时间上重合的轨迹之间发生的典型交互。该模型利用现有的人体轨迹数据集,无需任何额外的注释即可了解人类在社交空间中遵守的常识规则和惯例
什么
模型假设首先对每个场景(来自俯视静电摄影机的帧序列)进行预处理,以获得所有人在不同时刻的空间坐标。在任何时刻,场景中的iₜₕ人都由他/她的xy坐标(xᶦₜ,yᶦₜ)表示。我们观察所有人从时间1到Tₒ₆ₛ(输入序列)的位置,并预测他们在时间时刻Tₒ₆ₛ+1到Tₚᵣₑₔ(未来预测序列)的位置。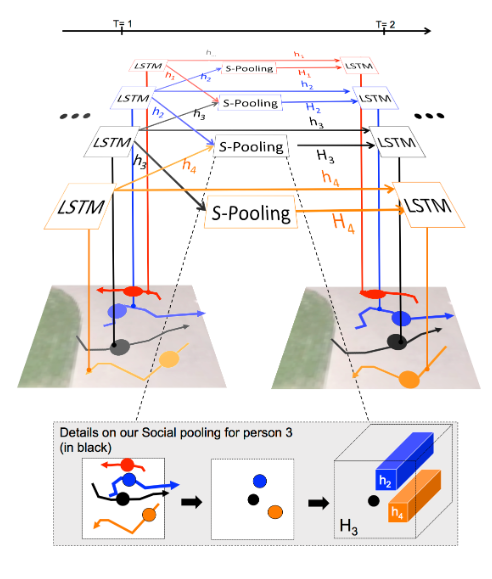
LSTM权重在所有序列之间共享。
隐藏状态的社会汇集
个体通过对周围人的运动进行隐含的推理来调整自己的路径。这些邻居反过来会受到周围其他人的影响,随着时间的推移可能会改变他们的行为。该模型期望LSTM的隐藏状态能够捕获这些时变的运动属性。为了跨多个人进行联合推理,该模型引入了如图2所示的“社会”汇聚层。在每个时间步,LSTM小区从邻居的LSTM小区接收汇聚的隐藏状态信息。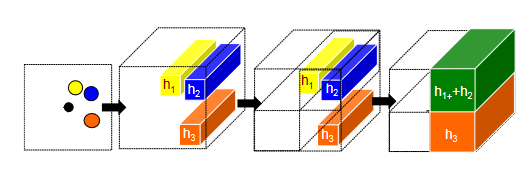
时间‘t’处的隐藏状态用于预测下一个时间步‘t+1’处的轨迹位置(x‘,y’)ᶦₜ₊₁的分布。
结果
在测试期间,作者使用经过训练的社会-LSTM(及其修正)模型来预测i-ᶦₜ人的未来位置(x‘ᶦₜ,y’ₜₕ)。从时间Tₒ₆ₛ₊₁到Tₚᵣₑₔ,它们使用来自前一个社会-LSTM单元格的预测位置(x‘ᶦₜ,y’ᶦₜ)代替真实坐标(xᶦₜ,yᶦₜ)。
模型比较
- 线性模型(LIN):作者使用现成的卡尔曼过滤在假设线性加速度的情况下外推轨迹。
- 碰撞避免(LTA):作者报告了一个简化版本的社会力模型的结果,该模型只使用碰撞避免能量,通常称为线性轨迹避免。
- 社交力(SF):作者使用了社交力模型的实现,在该模型中对群体亲和力和预测的目的地等几个因素进行了建模。
- 迭代高斯过程(IGP):作者使用IGP的实现。与其他基线不同,IGP还使用有关人员最终目的地的附加信息。
- 作者香草LSTM(LSTM)。这是Social-LSTM模型的简化设置,其中作者删除了“Social”汇合层,并将所有轨迹视为彼此独立。
- 具有占用图的作者的LSTM(O-LSTM)。作者展示了简化版本的社会-LSTM模型的性能。需要提醒的是,该模型在每个时间实例仅汇集邻居的坐标
使用的测试指标:
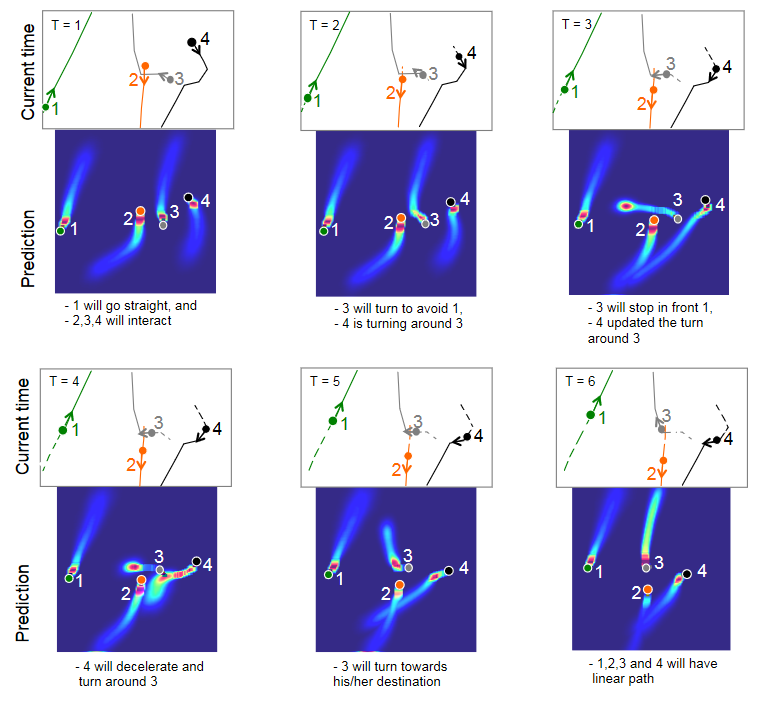
真实场景中的额外结果

原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/27/%e7%a4%be%e4%ba%a4lstm%ef%bc%9a%e4%b8%80%e7%a7%8d%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e6%a8%a1%e5%9e%8b%ef%bc%8c%e5%ae%83%e5%8f%af%e4%bb%a5%e9%a2%84%e6%b5%8b%e6%82%a8%e7%9a%84%e8%b7%af%e5%be%84/
