
前言
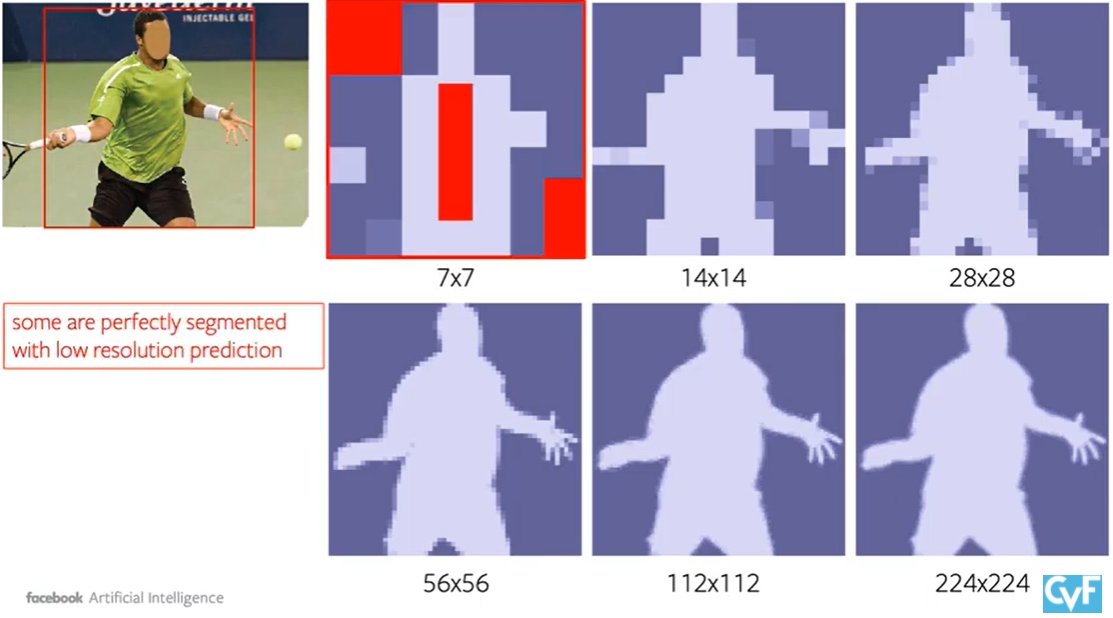
- 透過選定區塊的方式解決有线电视新闻网網路在高解析度分割需要龐大計算量和記憶體的問題,像下面紅色區塊就只需要粗分辨率即可,且任何像素级的任務都可以用類似的概念去實作。
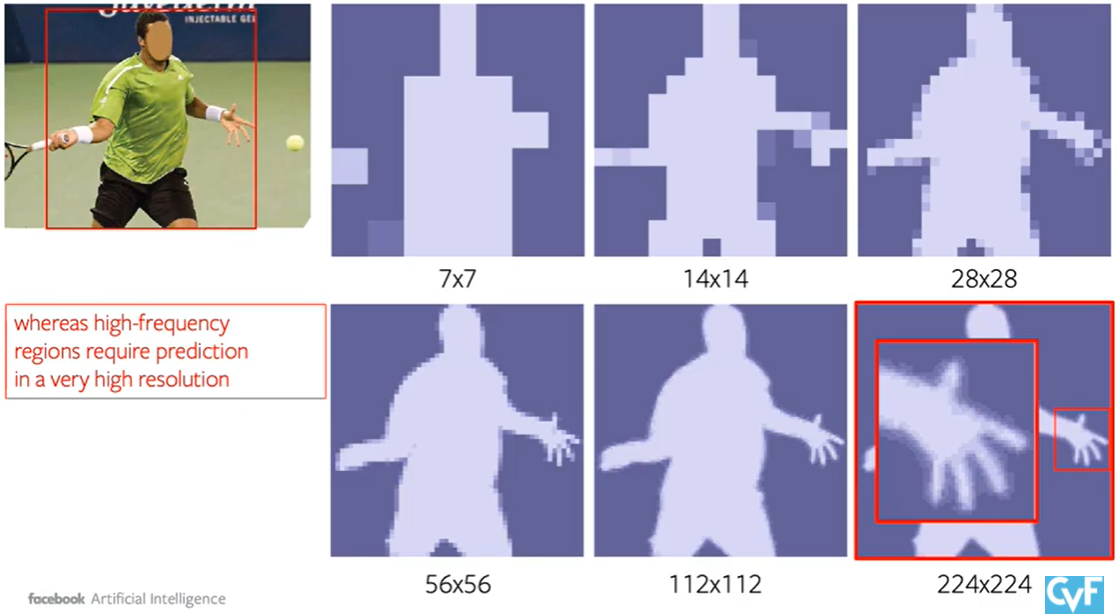
- 像是這種高频区就無法從低分辨率的输出得到,因此需要更高分辨率的输出。
方法
- 重點大概就如下面紅色標駐所說,會透過高分辨率的输出去補強原始的低分辨率输出。

- 作法如下,將原本的邊緣UpSample後取一些邊緣點去恢复,反覆直到指定的分辨率。
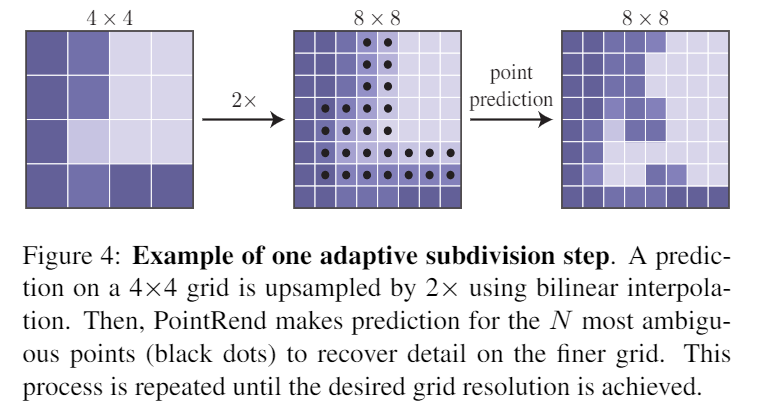
- 過程就很類似下面這張圖.
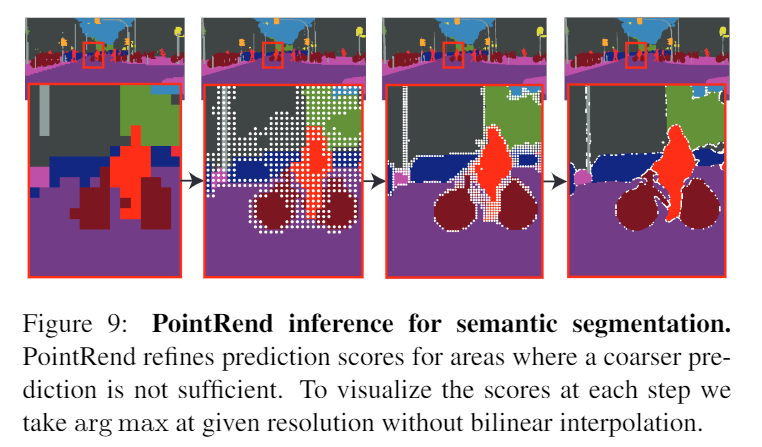
- 其架構及步驟如下
- (I)点选择策略选择少量的实值点进行预测,避免对高分辨率输出网格中的所有像素进行过多的计算。
- (Ii)对于每个选定的点,提取逐点的特征表示。实值点的要素是通过禁用双线性插值,使用规则栅格上的4个最近相邻点来计算的。结果,能够利用在通道维度OFF中编码的子像素信息来预测具有比f更高分辨率的分割。
- (Iii)点头:被训练成独立于每个点从该逐点特征表示预测标签的小神经网络。
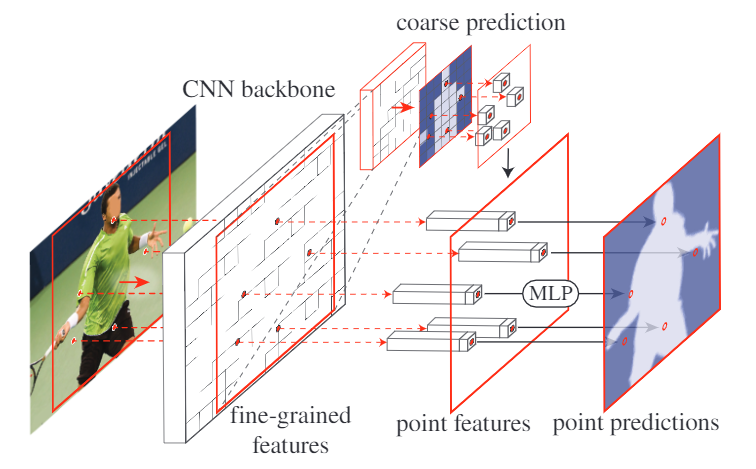
用于推理和训练的选点
- 計算高機率是邊緣地方的Location,也就是跟附近Pixel的值相差很多的地方,至於其他地方就直接Interpolating即可。
- 基于當透過cnn的的分割模型輸出一個低解析度的掩码,對其做双线性插值的上采样之後取N個最不确定的点(例如,对于二进制掩码,具有最接近0.5的概率的那些)

逐点表示和点头
- 细粒度:不同Channel的位置,因此需要粗略预测的Global Context和Label,不然不知道物件重疊區域是屬於誰的,不能有效判斷誰前誰後。
- 粗略预测:K通道的实例标签。
- 点头:MLP在所有点之间共享权重由于MLP预测每个点的分割标签,因此它可以通过标准的特定于任务的分割损失进行训练。
实验
- 数据集:Coco和Cityscape
实例分割
- 架构:用ResNet-50+FPN主干屏蔽R-CNN。
- 可以看到在AP*和Citycapes這種有比較高解析度的Mask Ground Truth的資料集上表現更好.
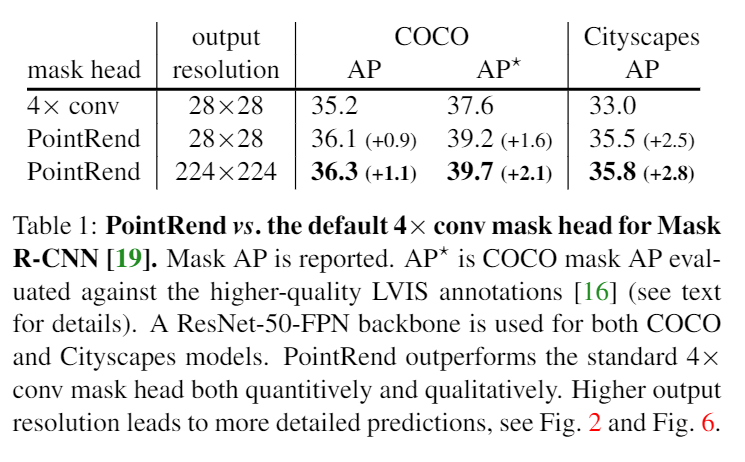
- 但其實AP是在算IOU所以這個指标不能很好的詮釋在邊緣上面的處理,可以看到下圖的表現其實差了不少。

- 此外在高解析度上效能也會有明顯提升.

语义切分
- 架构:采用RENET-103型、的DeepLab3,采用RENET-101时的SemantiFPN


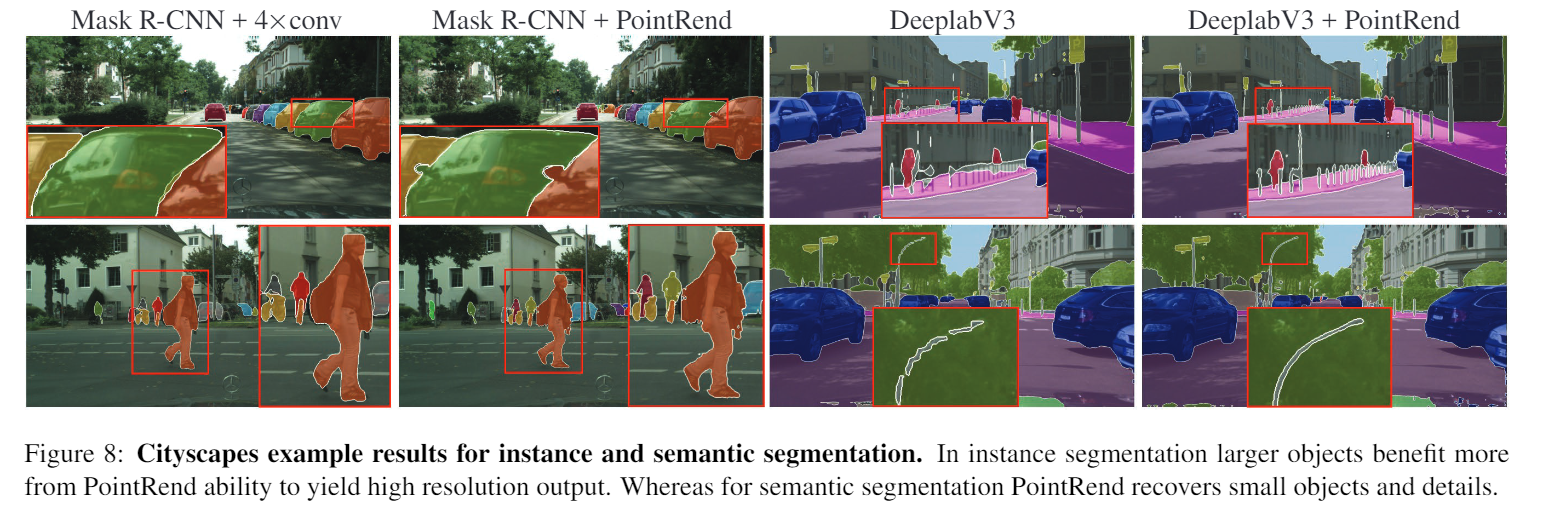
- 這張圖是表示在实例分割的部分越大的物件效果越好,而在语义分割的部分点渲染恢复小物件和详细信息的部分做得很好。
消融研究
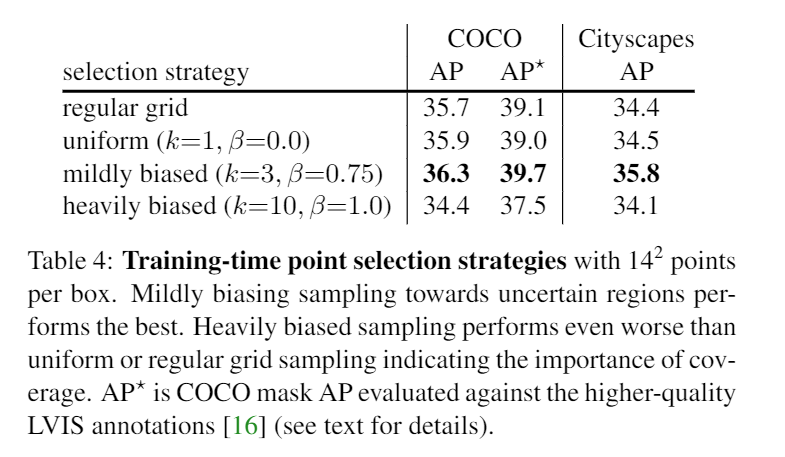
- 針對不同的细分步骤做比較,飽和的很快,或許要比較複雜的邊界才會有比較明顯的變化,且以這種小範圍的邊緣反鋸齒的修正來講,AP本身就不算是很好的一個衡量依據。

- 比較不同的數量和比例對訓練結果的影響,取的點為k*N且值>=β,而值在2

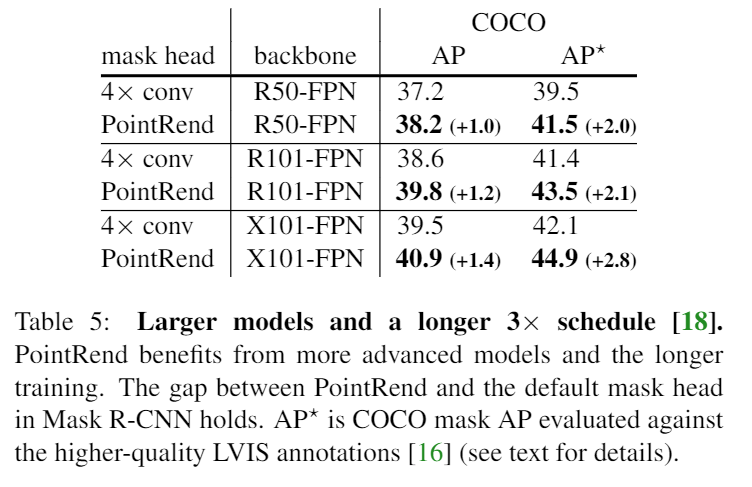
- 用比較大的型号和比較長的時間去訓練也可以讓結果變好
參考連結
[arxiv][arxiv]
[影片][影片]
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/04/pointrend%ef%bc%9a%e6%b8%b2%e6%9f%93%e6%97%b6%e5%9b%be%e5%83%8f%e5%88%86%e5%89%b2cvpr-2020/
