
สวัสดีครับผมเต้วันนี้ผมอยากมาแชร์อะไรหน่อยเกียวกับโลกของComputer Visionช่วงนี้ฝึกงานที่Dynamic Intelligence Asia(DIA)เลยได้Researchเรื่องComputer Visionเยอะมากและผมได้ไปResearchเรื่อง变压器กับ计算机视觉แล้วรู้สึกอินมากๆกับความพ่อทุกสบานบันของ变压器จึงมาแชร์ว่า变压器ที่อยู่ใน计算机视觉มันดีกว่า卷积神经网络(Cnn)ยังไงแล้วมันมาแทนcnnเลยรึปร่าวโดยเนื้อหาทั้งหมดจะมาจากPaper“一幅图像价值16×16字:按比例进行图像识别的变压器”หรือที่เรียกกันว่า视觉转换器(VIT)“AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE”
โดยประเด่นที่ผมอยากมาเหล่าให้ฟังมีดังนี้
- 什么是视觉变形金刚?
- 视觉变形金刚是如何工作的?
- 为什么计算机视觉中的变形金刚比CNN好?
- “变形金刚”能取代CNN吗?
- 结论
什么是视觉变形金刚?
ก่อนแรกเรามารู้จักTransformerกันแบบคร่าวๆว่ามันคืออะไรเดิมที่Transformerนั้นเริ่มมาจากวงการของnlpโดยมาจากPaperที่ชื่อว่า《注意就是您所需要的全部》ซึ่งเรียกได้ว่าDL型พวกLSTMหลายตัวๆถึงกับตกกระป๋องไปเลยเพราะด้วยนำเสนอสถาปัตยกรรม变压器ที่ใช้Self-AttendantมาดึงFeatureทำให้ได้Accuracyที่ดีขึ้นมากบวกกับResourceในการComputationก็ต่ำลงไปด้วยจึงทำให้变压器นิยมมากขึ้นจนเกิด型号nlpดังๆอย่าง伯特ที่ถ้าใครอยู่ในวงการnlpก็อ๋อกันทุกคนแล้ว变压器มันมาอยู่ใน计算机视觉ได้ยังไงละ?“Attention Is All You Need”
ในปี2019年脸书ได้发表论文นึงชื่อว่า《使用变压器进行端到端目标检测》ที่เป็นการทำcnnมาใช้กับTransformerโดยใช้cnnในการExtract Featureแล้วค่อยFeed Feedให้Transformerต่อเพื่อทำObject Detectionโดยอ้างอิงจากFigure 1ซึ่งถือเป็นก้าวหนึ่งที่ดีของการนำ变压器มาใช้ในการ计算机视觉“End-to-End Object Detection with Transformers”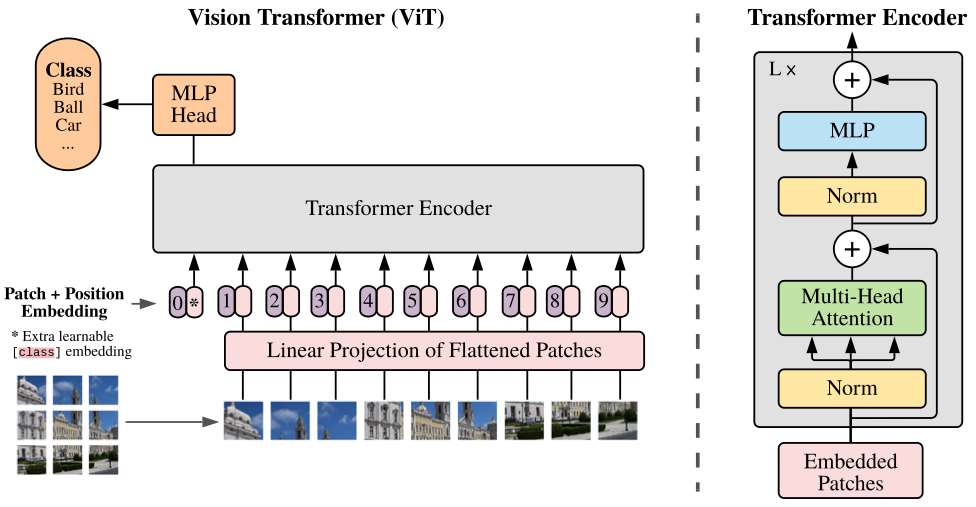
ซึ่งมาในปี2020年谷歌ได้แสดงพลังแห่ง变形金刚อีกครั้งโดยการปล่อย论文《一幅图像价值16×16字:用于图像识别的大规模变形金刚》โดยได้เสอน架构ชื่อ视觉变形金刚ในการแก้ไขปัญหา图像分类ที่อยู่ใน计算机视觉โดยไม่มีการใช้卷积神经网络(Cnn)แม้แต่กระบวนการเดียวถื่อเป็น端到端变压器เลยซึ่งหลังจากปล่อย纸张นี้ออกมาได้กลายเป็น最新技术(SOTA)ทันทีในหมวด图像分类(ไม่แน่ใจตอนนี้โดนPaperอะไรมาแทนยังเพราะPaperนี้Publishมาหลายเดือนแล้ว)โดยVitได้เลือกใช้变压器编码器ในการ提取特征ออกมาเพียงอย่างเดียวซึ่งสำหรับผมถือว่าว้าวมากๆเพราะการใช้cnnในComputer Visionถือเป็นเรื่องที่ตายตัวมากแต่Paperได้ทำให้โลกComputer Visionแปลกใหม่มาทันที“AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE”
视觉变形金刚是如何工作的?
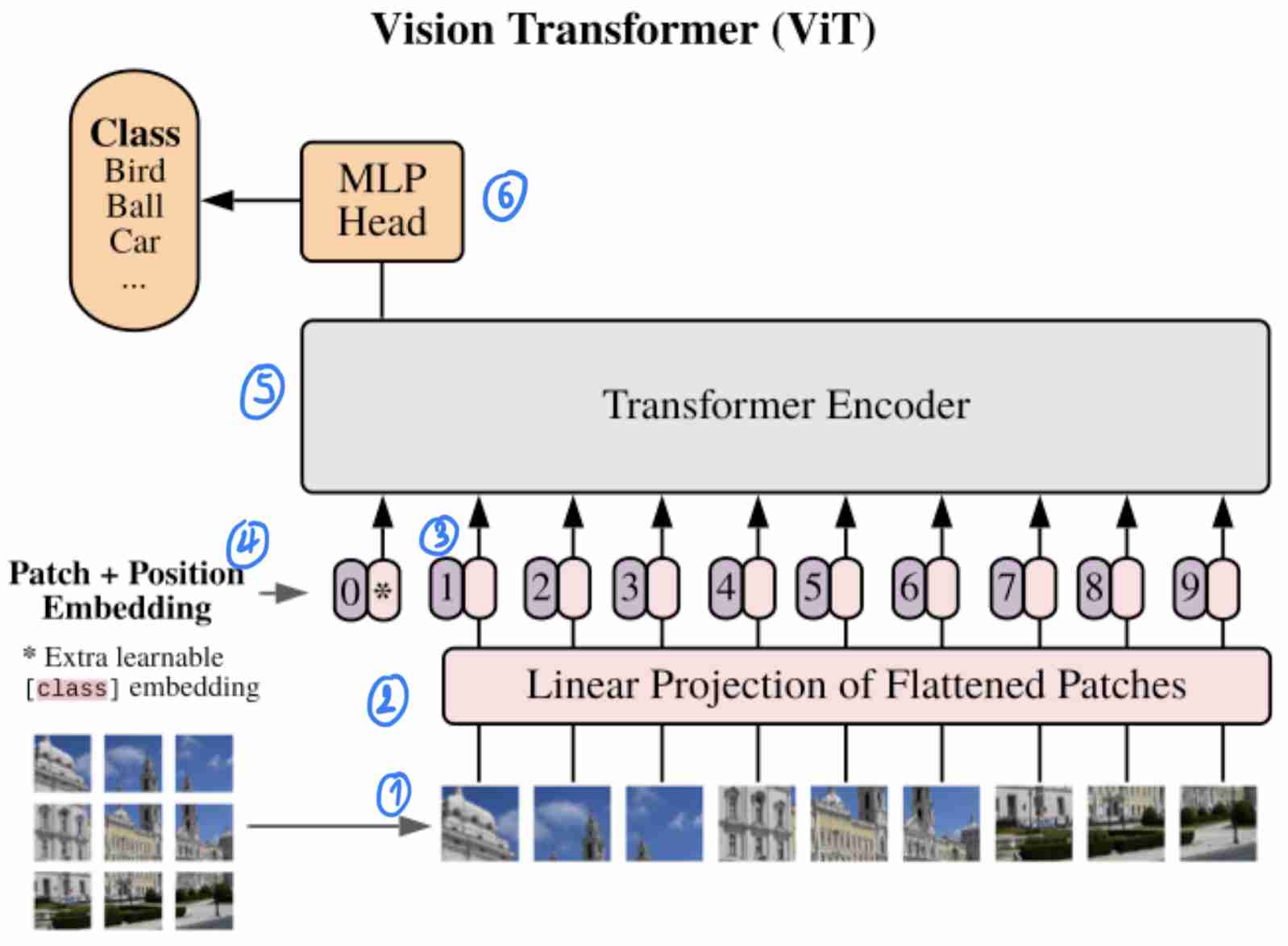
แล้วVITนี้มันทำงานยังไงละโดยผมจะอิงจาก图3ที่มีLabelบอกStepการทำงานอยู่
1)将图片拆分成补丁
โดยในขั้นแรกต้องเริ่มจากการแบ่งภาพทีใส่เข้ามาออกเป็นPatcheก่อนโดยสาเหตุที่ต้องแบ่งรูปภาพออกมาเป็นPatcheเพราะPaperมีหลักการออกแบบมาจาก型号อย่างBERTจึงจะใช้Conceptที่นำWordแต่ละWordเข้าไปใน转换器ดังนั้น架构VITจะทำการเปลี่ยนรูปภาพใหญ่ให้เป็น补丁ย่อยๆเหมือนกับWordคำเป็นแบบ序列令牌แล้วค่อย馈送เข้า转换器ต่อไป
โดยถ้าเราลองนำรูปขนาด224×224แล้วแบ่งให้ได้ขนาด补丁14 x 14เราจะได้รูปที่แบ่งออกมาเป็นPatchingย่อยๆ16 x 16ตาม图4ก็จะเป็นที่มาของชื่อ纸张นี้และจะเห็นได้ว่ามันไม่เหมือนกับ图3เพราะPaperแค่ยกตัวอย่างเฉยๆและขนาดของPatcheสามารถปรับเปลี่ยนได้โดยถ้าอ้างอิงจากPaperยิ่งขนาดPatcheเล็กลงก็ต้องใช้资源ที่培训มากขึ้นและให้ง่ายต่อการนำเสอนผมจะขอ拆分补丁ให้เป็นแบบ3 x 3ก็จะได้ตาม图5
2)平整补丁,并将平整的补丁嵌入到较低的维度
หลักจากที่ทำการแบ่งรูปภาพของเป็นPatcheย่อยๆแล้วเราต้องทำการเปลี่ยนจาก张量ขนาดd x d x 3ให้กลายเป็น矢量ขนาดd*d*3 x 1โดยที่dคือขนาดของPatcheและต้องทำการ嵌入矢量เพื่อให้ขนาดของ矢量เหมาะสมสำหรับ馈送เข้า转换器ได้โดนทั่วไปการ嵌入矢量เราก็จะใช้密集层เพื่อให้ได้矢量ที่เราต้องการก็จะทำให้ได้ผลลัพธ์เหมือน图6
3)添加位置嵌入
หลักจากที่มีการEmbedded Vectorแล้วเพื่อให้สามารถFeedเข้าTransfmerได้ก่อนหน้านั้นก็ต้องมีการทำPosition Embeddingก่อนแล้วมันคืออะไรละเนื่องจากตัวTransformerที่จะใช้ใน纸张Vitเป็น变压器编码器ซึ่งภายในนั้นจะมี多头自关注ที่เป็น关注ที่สามารถ共享参数กันได้ในแต่ละ令牌ที่馈送เข้าไปในกรณีนี้คือ补丁ที่มาจากการแบ่งของรูปใหญ่เพื่อป้องกันใม่ให้ภาพมันสลับต่ำแหน่งกันมั่วชั่วเหมือนในNLPลำดับของคำนั้นก็มีความหมายเลยต้องมีการทำ位置嵌入
ถ้าบางคนยังไม่เห็นภาพให้ดู图7ลองดูภาพซ้ายกับขวาเทียบกันสำหรับคนและ变压器นั้น2ภาพนี้แตกต่างกันสินเชิงแทบจะไม่รู้เลยว่ามันคือแมว
ให้ดูที่เลขที่อยู่บนรูปภาพจะเป็นตัวบอกตำแหน่งของรูปภาพแต่เอามาใหม่ถ้าเราทำการPositional EmbeddingเหมือนกับการLabelแต่ละPatcheควรอยู่ตำแหน่งPositional Embeddingโดยไล่จากซ้ายไปขวาบนลงล่าง(1-9)สำหรับคนก็อาจจะไม่รู้เรื่องเหมือนเดิม5555แต่变压器นั้นสองภาพนี้คือภาพเดียวกัน
ซึ่งในPaperนี้ก็มีการทำPositional Embeddingหลากหลายรูปแบบแต่เอาง่ายๆสุดก็คือเหมือนมี查找表และก็ยิบLabelมาบวกกับPatcheเลยแต่ที่น่าสนใจคือผลลัพธ์ที่ได้จาใช้วิธีในก็ตามก็ไม่ได้ผลลัพธ์ที่แตกต่างกันมากซึ่งน่าสนใจมากๆกการทดลองนี้คือPositional Embeddingจะมีหรือไม่มีหรือใช้วิธีในก็ตามก็ไม่ได้ผลลัพธ์ที่แตกต่างกันมากซึ่งน่าสนใจมากๆไม่ได้สนใจควา变压器位置嵌入มสัมพันธ์ของลำดับของPACT他的แต่จะไปสนใจว่าแต่ละPACT他的มีความเชื่มโยงกันได้อย่างไร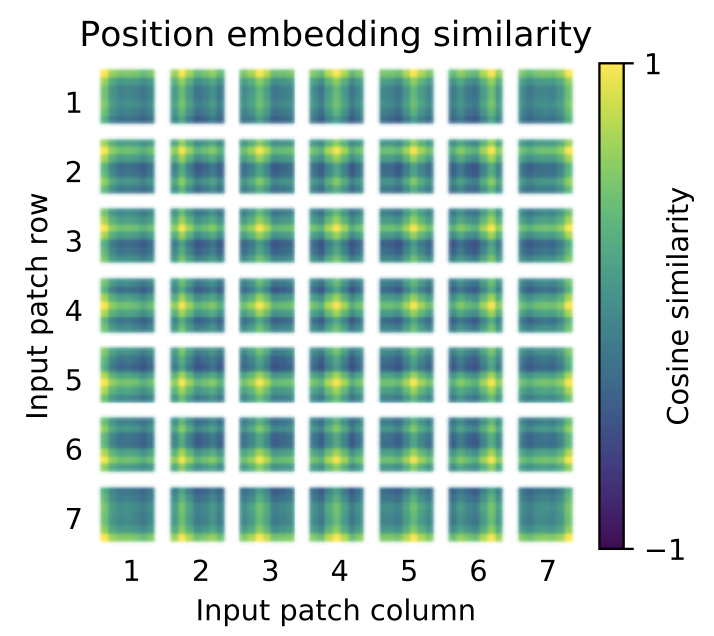
ซึ่งในPaperนี้ก็ได้มีการใช้Positional Embeddingที่สามารถTrainได้ซึ่งก็เจ็งดีที่ได้เห็นว่าPositional Embeddingสามารถ表示ตำแหน่งของตัวเองได้ดีมากจาก图10
4)添加分类类令牌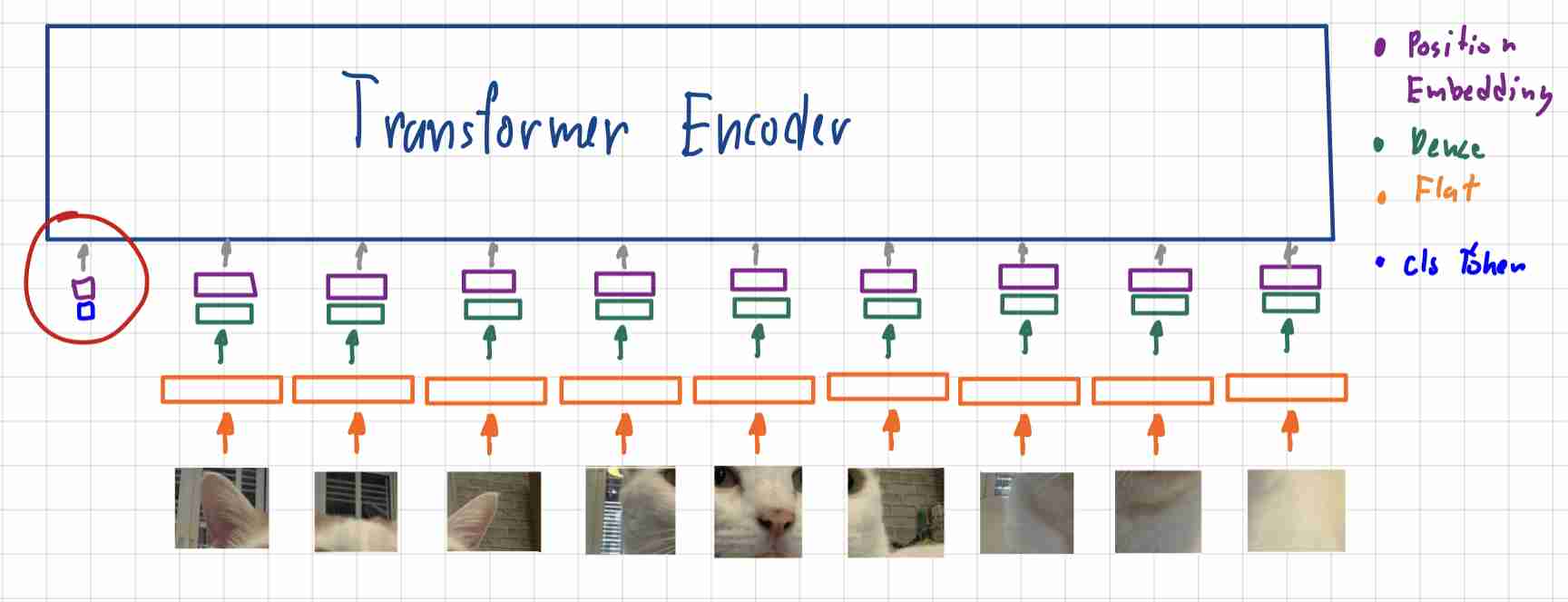
เพื่อที่จะสามารถ预测类ออกมาได้ต้องมีการใส่类令牌หรือCLS令牌มันคือ矢量ที่เท่ากับจำนวนของ类ที่เราต้องการ预测ว่ามันคืออะไรโดยก็ทำการเอากับบวกกับPositional Embeddingแล้วเอาไปใส่ในTransformerพร้อมกับPatcheของรูปภาพ
5)将序列作为输入馈送到标准变压器编码器
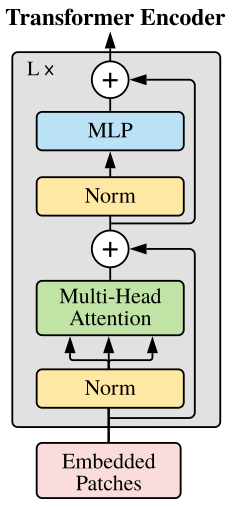
ในขั้นตอนต่อมาเป็นการนำPatcheและCLSไป馈电เข้า变压器编码器ตามปกติเลยโดยผมไม่อยากลงรายละเอียดของ变压器มากเพราะเนื่อหาค่อนข้างเยอะสามารถเขียนเป็น博客ใหม่ได้เลยแต่ถ้าใครสนใจก็สามารถลองอ่านได้จาก“关注就是你所需要的”ได้เลยแต่ให้สรุปง่ายๆในขั้นตอนนี้ก็คือเอาทุกอยากที่เราเตียมมาเอาไป级联กันแล้ว馈电เข้า变压器编码器แค่นั้นเพราะจากท่ีกล่าวไปข้างใน变压器编码器จะมี多头注意ที่จะ共享参数กันจะทำให้变压器เห็นทุก补丁“Attention Is All You Need”
6)分类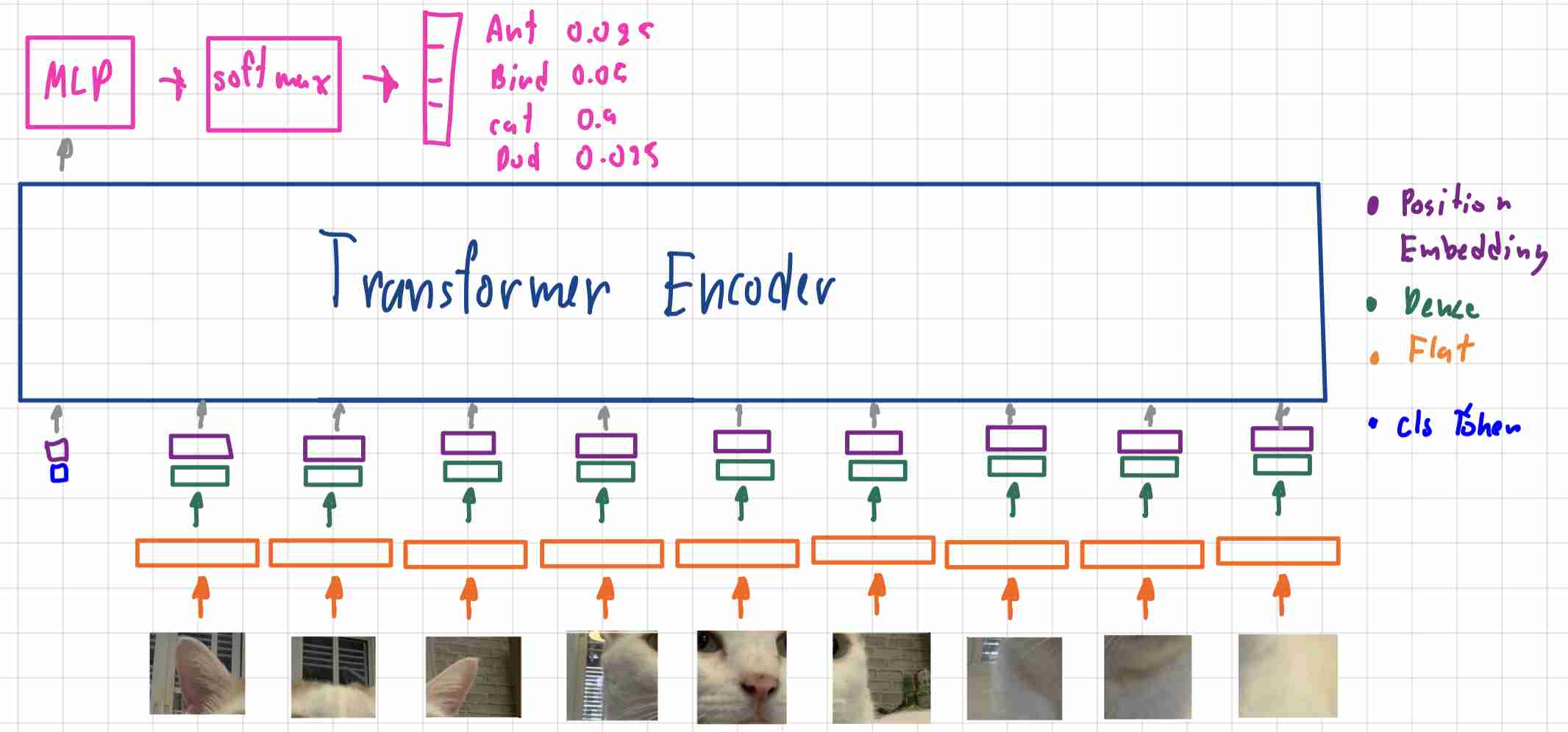
หลังจาก馈送เข้า转换器编码器แล้วก็ทำการดึงไปเข้าพวกmlp网络จะทำ密集层กี่ชั้นก็ว่าแล้วก็จบด้วย软件最大แต่จะเห็นได้ว่าเราไม่จำเป็นต้องดึงทุก令牌(补丁程序+cls令牌)ออกมาเพื่อทำการ预测เพราะข้างใน变压器编码器จะมี多头注意ที่จะ共享参数กันเพียงแค่ดึง令牌แรกที่เป็นCLS令牌มาใช้ก็พอแล้ว
สุดท้ายนี้เราก็จะสามารถทำ图像分类แบบใช้转换器แบบ端到端ได้แล้วโดยผมก็ได้มีรูปสรุปเป็นGifเพื่อ可视化ให้เข้าใจมากขึ้นด้วยดัง图14

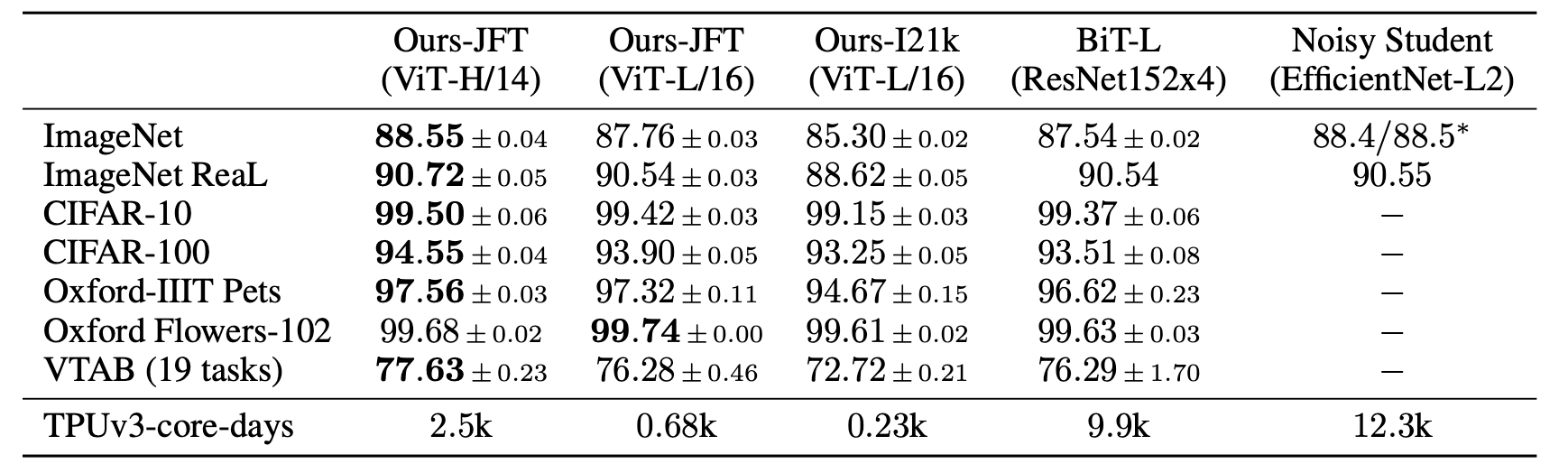
โดยสรุปแล้วการอธิบายของผมนั้นเป็นการยกตัวอย่างของหลักการทำงานของVitแต่ผมยังไม่ได้พูดพึงสมมการข้างในเช่นสมการของ多头自关注ที่เป็นส่วนสำคัญในPaperนี้มากและยังร่วมไปถึงรายละเอียดของPositional Embeddingซึ่งถ้ามีโอกาศผมจะมาเขียนให้อ่านกันอีกทั่งพวกเลขที่ผมยกตัวอย่างจะไม่ใช้官方จาก纸张ผมแค่ยกตัวอย่างเพื่อความง่ายในการนำเสอนแต่ตัว官方นั้นจะสามารถดูได้จาก图15และ图16ที่มีทั้ง类型ของ架构และขนาดของPatcheที่แตกต่างกัน
图17จะแสดงให้เห็นว่าAttributeในTransformerมีการสั่งเกตุภาพนั้นได้อย่างไรบางซึ่งบางคนก็อาจคุ้นเคยกันดีในcnnถ้าPlotออกมาเป็นGradientแบบ热图ก็จะได้ภาพประมาณนี้ก็จะเห็นได้ว่าTransformerพยามจะไม่สนใจBackgroundแต่จะไปFocusที่รูปที่ต้องการ分类ซึ่งถือว่าทำได้ดีมาก
为什么计算机视觉中的变形金刚比CNN好?
ตอนนี้ทุกคนอ้างสงสัยแล้วว่า变形金刚มันดีกว่า有线电视新闻网ยังไง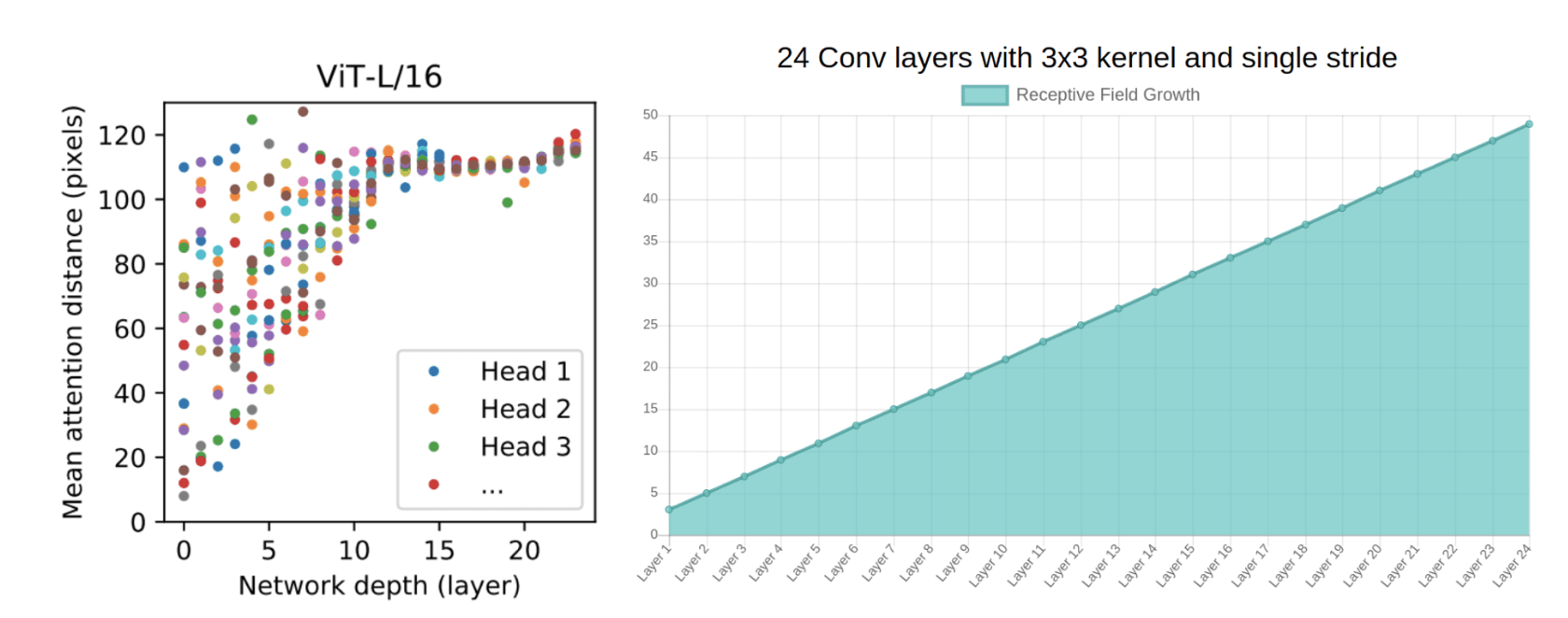
ในข้อที่โดดเด่นชัดเจนเลยของการนำ变形金刚มาแทนcnnคือจาก图18สองกราฟนี้ได้แสดงความสามารถในการ了解非本地交互像素ของ变形金刚และcnnจากรูปซ้ายจะสามารถสังเกตุได้ว่าแค่เพียงLayerแรกจะมีบาง磁头ที่อยู่ใน变压器(注意磁头)สามารถเรียนรู้像素ที่ห่างออกไปได้แล้วโดยไม่ต้องโดนLimitที่局部像素หรือก็คือสามารถมองภาพได้กว้างมากขึ้นไม่เหมือนกับ有线电视新闻网ที่ต้องทำให้Layer Complexมากขึ้นเรื่อยๆจึงสามารถมองภาพได้กว้างมากขึ้นดังรูปขวาถ้าลองดูเทียบกันแล้วนี้คือหมากสำคัญที่ทำให้Transformerเหนือกว่าโดนไม่มีข้อกังขาถ้าเทียบกันแบบง่ายๆความสามารถในการเรียนของTransformerโตแบบEXPO(ซึ่งก็อาจไม่จำเป็นเพ)ราะแค่Layerแรก็เรียนได้แล้ว)แต่有线电视新闻网จะค่อยๆโตแบบ线性ซึ่งจะเป็นสาเหตุว่าทำมัย变压器จึงใช้资源น้อยกว่าอ้างอิงจาก图16ที่จะใช้TPU核心น้อยกว่าประมาณ3เท่าเหมือนเทียบกับ变压器ตัวที่ใหญ่ที่ในกราฟกับ有线电视新闻网(VIT-H/14和BIT-L)(เอาเขาจริงๆมันก็มุกตลกร้ายนะเล่นใช้TPUที่จริงๆตอนนี้มีแค่谷歌ที่มีอยู่คนเดียวบนโลกนี้5555แทบDataSetนี้ก็ไม่ธรรมดาjft Datasetที่เป็นPrivateของgoogleเพียงคนเดียว)
计算机视觉网络ที่ดีควรมี内核ที่平滑ที่สามาแยกแยะความแตกต่างของ像素ได้ดีจะเห็นว่า变压器ในVITแค่层แรกๆก็มี内核ที่平滑แล้ว
“变形金刚”能取代CNN吗?
พูดมาซะขนาดนี้变形金刚จะมาแทน有线电视新闻网เลยหรอคำตอบคือไม่ครับแต่อนาคตไม่แน่แล้วเพราะอะไรละ因子นึงที่ผมอยากมองคือการนำมาขึ้น制作มากกว่าที่จะเป็นSOTAถึงแม้变压器จะได้เป็นSOTAแต่ถ้าเทียบกันที่ตัวAccuracyแล้วมันคือระดับ1-3%ซึ่งถ้ามาเทียบกับที่ระดับProductionใหญ่ๆแล้วแทบจะไม่เห็นข้อแตกกต่างการที่ผมมาฝึกงานที่DIAทำให้ผมรู้อย่างนึงก็คือถ้า型号มันจะดีขนาดไหน,SOTA,ใหม่ล่ำยุคและสามารถImplementateได้จริงแต่เอามาทำProductionไม่ได้ก็จบเท่านั้น
ก็จริงที่变压器นั้นมีการกิน资源ที่น้อยลงแต่…อย่าลืมนะครับ纸质นี้ใช้TPU!!ซึ่งราคาต่างกันลิบลับกับGPU T4ในCoLabที่เราใช้กันเลยในความจริงนั้นเราต้องการ型号ที่推断速度ค่อนข้างสูงและAccuracyพอใช้ได้และยิ่งถ้า产品ตัวนั้นต้องเจอLoadสูงๆทำให้เป็นเรื่องที่สำคัญมากดังนั้นการ优化模型ก็เป็นอีกเรื่องที่ควรคำนึงถ้าต้องการเอาซึ่งถ้าเอาTPUมา推理成本คงบานปลายมหาศาลซึ่งถ้าในอนาคตมี变压器แบบใหม่ที่อยู่ใน计算机视觉และสามารถทำ推理速度ได้ดีนี้ถือเป็นจุดพลิกของ变压器เลยที่จะก้าวข้ามcnn
โดยตัวผมนั้นก็ได้ทำพวก项目ที่ต้องใช้Object Detectก็ได้ไปเจออีกPaperนึ่งชื่อ《Swin Transformer:Hierarchical Vision Transformer Using Shift Window》ที่พึงออกต้นปี2021年ซึ่งเป็นการนำTransformerมาทำObject Detectโดยใช้Shift Windowมาช่วยซึ่งก็เจ้งมากๆสำหรับผม“Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”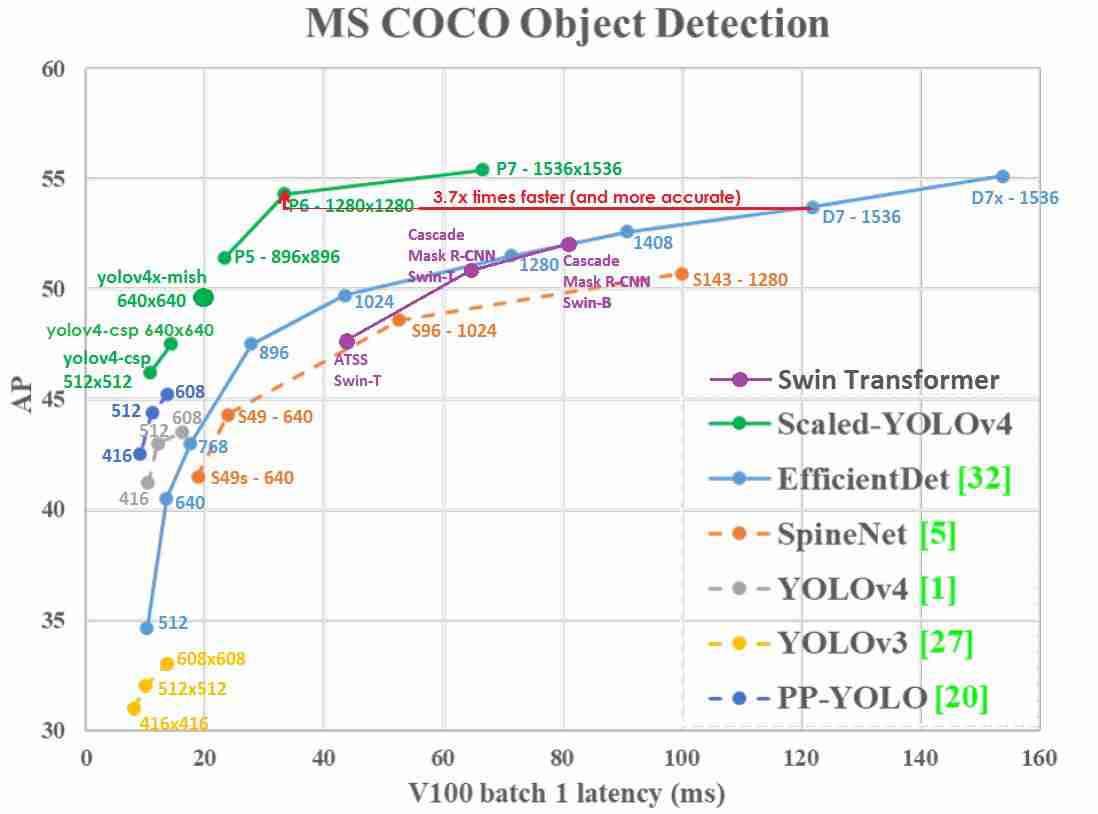
แต่ก็ไม่นานคนที่เขียนScaled-YOLOv4ได้Publish Paperห่างกันไม่กี่เดือนชื่อ《您只了解一种表示方式:多任务统一网络(YOLOR)》ได้ตบSwintออกจากบันลังSOTAทั้งในแง่ของAPกับ推理速度อย่างรวดเร็วจาก图20ก็จะเห็นว่า变压器อาจจะยังไม่เห็น最佳选择ในการขึ้น生产(ตอนนี้ได้ข่าวว่าคนเขียนYOLORกำลังทำYOLO V.Transformerอยู่ก็ลุ้นอยู่ว่าจะเป็นยังไง)“You Only Learn One Representation: Unified Network for Multiple Tasks (YOLOR)” 
ซึ่งตัวผมนั้นปกติก็ไม่เอา型号จากTF,Pytorchไปขึ้นProductionหรอกแต่มีการConvertให้กลายเป็นTensorRTก่อนจึงนำไปเขียนLogicต่อไปในกรณีของYolorก็ไม่มีปัญหาสามารถเพิ่ม推理速度ได้ถึง4เท่าทำให้图形处理器ราคา5000บาทสามารถวิ่งได้ที่15-18fpsแต่สำหรับพวก变压器นี้ยังไม่ง่ายเลยผมลองเอาVitแปลงเป็นONNXแต่กับได้推理速度ที่น้อยลงอาจจะมาจากโครงสร้างของ变压器ที่ซับซ้อนมากกว่า有线电视新闻网จึงยากที่จะแปลงให้เป็น图表ซึ่งก็ต้องรอทางTensorRTกับONNX更新เกี่ยวกับเรื่องนี้ไม่ก็ผมก็ต้องหาวิธีอื่น
นี้ก็เป็นอีกสาเหตุที่Transformerยังไม่สามารแทนCNNได้(เดียววันหลังถ้ามีโอกาศผมจะมาสอนการขึ้นProductionกับComputer Visionให้นะครับร่วมไปถึงการConvertเป็นTensorRT)
仅供参考。แต่จริงๆผมก็เจอ变压器ที่ทำ对象检测ได้推理速度น่าพอใจแต่APค่อนข้างต่ำซึ่งคนเขียนยังเครมเองว่า纸张นี้ไม่ใช้高性能对象检测แต่纸张น่าสนใจดีเพื่อใครสนใจอ่าน《你只看一个序列:通过物体检测重新思考视觉中的变形金刚》“You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection”
结论
ในปีนี้สำหรับการได้มาฝึกงานถือว่าได้เรียนอะไรเยอะมากทั้งเรื่องของLogic Bussnessการเอางานไปขึ้นProductionและResearch Model Computer VisionแบบFull-Time(全职计算机视觉研究模型)ึ่งการที่ผมได้อ่านเรื่องTransformerถือว่าเปิดโลกComputer VisionของผมมากจากPaperนี้
Transformได้มาเขย่าวงการComputer Visionให้เราได้เห็นว่าเขาไม่ได้มีดีแค่nlpแต่จริงๆเขาเป็นพ่อทุกสถาบันถึงแม้ตอนนี้จะยังไม่สามารถไปแทนcnnได้ซึ่งVitสำหรับผมถือเป็นตัวอย่างที่ดีมากของการนำTransformerในงานComputer Visionทำให้เราเห็นในสิ่งที่ไม่เคยมาก่อนเช่นถ้าพูดComputer Visionก็ต้องcnnแต่ก็ไม่แน่ในอนาคตเราอาจจะเห็น变形金刚มาแทนcnnเหมือนlstmในnlpเลยก็ได้ใครจะไปรู้เมื่อ20ปีที่พวก经典计算机视觉เช่นSIFT和冲浪,Hog,BlobจะโดนCNNแทนในอีก10ปีต่อมาในตอนนี้ก็อาจมาถึงเวลาของCNNบางแล้วละที่จะโดนTransformerแทนที่
อย่างไรก็ตามผมก็หวังว่าจะได้เห็นTransformerออกมามากขึ้นในงานComputer Visionและถ้ามีโอกาศก็อยากร่วมResearchงานที่ใช้TransformerในComputer Visionด้วยขอบคุณครับ
仅供参考。แมวในรูปชื่อ家庭ไม่ขายแต่ให้ฟรีเลยหยอกๆๆ55555
参考文献
你只需要关注就行了:https://arxiv.org/pdf/1706.03762.pdfhttps://arxiv.org/pdf/1706.03762.pdf
一张图片价值16×16字:按比例进行图像识别的变形金刚:https://arxiv.org/pdf/2010.11929.pdfhttps://arxiv.org/pdf/2010.11929.pdf
使用变形金刚进行端到端目标检测:https://arxiv.org/pdf/2005.12872.pdfhttps://arxiv.org/pdf/2005.12872.pdf
你只需要关注,Yannic Kilcher:https://www.youtube.com/watch?v=iDulhoQ2prohttps://www.youtube.com/watch?v=iDulhoQ2pro
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/28/%e4%bd%a0%e5%a5%bd%ef%bc%8c%e5%8f%98%e5%bd%a2%e9%87%91%e5%88%9a%e5%92%8ccnn%e5%86%8d%e8%a7%81%ef%bc%9f/
