
พอดีช่วงนี้ผมได้ศึกษาและลองเล่นเทคโนโลยีเกี่ยวกับการตรวจจับวัตถุโดยใช้รูปภาพสวัสดีทุกท่านครับเลยอยากจะมาแชร์ถึงขั้นตอนเผื่อคนที่อยากไปใช้ต่อสามารถนำไปประยุกต์ใช้ได้ครับวิธีการและอธิบายเท่าที่จะทำได้
โดยในบทความซีรีย์นี้จะมีทั้งหมด5ขั้นตอนด้วยกัน(จะทยอยเขียนเพิ่มขึ้นมาเรื่อยๆครับ)ได้แก่
สำหรับบทความนี้จะเป็นเรื่อง简介ของการทำงานเกี่ยวกับ图像检测และyoloถ้าใครอยากไปถึงขั้นตอนอื่นๆสามารถคลิกลิงค์ในแต่ละขั้นด้านบนได้เลยครับ
ปกติแล้วงานสำหรับรูปภาพนั้นจะมีอยู่หลายประเภทขึ้นอยู่กับเป้าหมายว่าเราต้องการอะไรเช่นถ้าUse Caseคลาสสิกเลยคือ图像分类โดยงานนี้เราต้องการให้AIมันบอกเราว่ารูปที่มีมันคือรูปของอะไรเช่นรูปตัวอย่างดังต่อไปนี้
แน่นอนว่าทุกคนรู้ว่ามันคือแมวแต่สำหรับAIนั้นเราต้องส่งรูปเข้าไปพร้อมกับผลลัพธ์ว่านี่คือรูปแมวนะเพื่อให้มันเรียนรู้เรื่อยๆและนี่คืองานหลักของสิ่งที่เรียกว่า图像分类
ต่อมาถ้าเราต้องการรู้เพิ่มเติมว่าแล้วแมวมันอยู่ตรงไหนของรูปหล่ะ?ถ้าได้โจทย์มาเป็นแบบนี้จะเป็นโจทย์อีกแนวที่เรียกว่า图像检测โดยมันจะบอกถึงตำแหน่งของรูปด้วยเช่น
จากรูปเราจะทราบเลยว่าน้องหมาอยู่ตรงไหนของรูปรวมถึงน้องแมวและน้องเป็ดทำให้เราได้Insightเพิ่มเติมจากผลลัพธ์(ซึ่งจะเป็นงานหลักของเราในบทความซีรีย์นี้)จากงานแนวนี้นั้นจะเพิ่มเติมจาก图像分类นิดหน่อยตรงที่เราต้องบอกAIไปด้วยว่าแมวอยู่พิกัดตรงนี้ในรูปนะ(ซึ่งก็คือ边界框โดยในบทความที่3จะอธิบายตรงนี้เพิ่มเติมครับ)
ในบางครั้งเราอยากจะแค่เอาเฉพาะส่วนของรูปที่สำคัญและอีกโจทย์คือในโจทย์นี้จะเป็น图像分割ดังรูปด้านล่างครับ
และภาพรวมความแตกต่างของโจทย์หลักๆคือ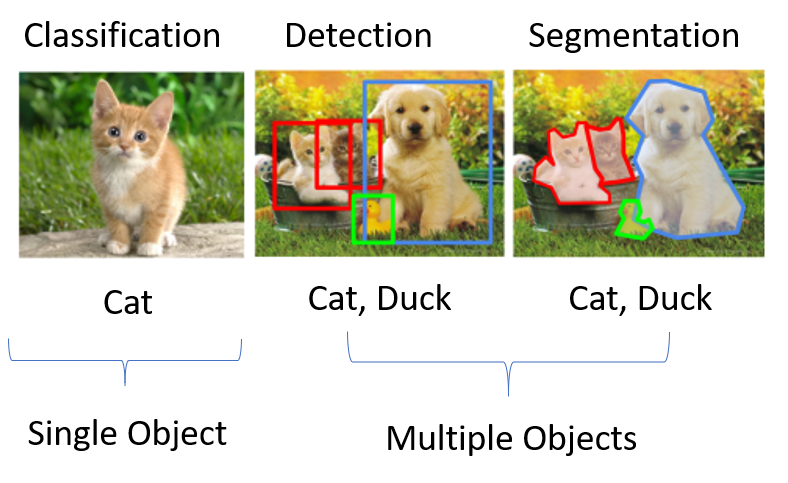
เพื่อที่จะดูว่าตำแหน่งของรูปนั้นอยู่ตรงไหนครับสำหรับบทความนี้เราจะโฟกัสไปที่图像检测(ภาพกลาง)
จริงๆการใช้งานจะขึ้นอยู่กับโจทย์(范围)เลยครับตัวอย่างเช่น
2.ก็จะมีกล้องที่คอยเช็คความเร็วหรืออาจจะตรวจสอบว่ารถติดไหมอีกตัวอย่างเวลาที่เราขับรถบนท้องถนนเราสามารถนำAIนี้ไปช่วยไ交通部ด้ว่ามีรถบนถนนเยอะหรือไม่แล้วไปเชื่อมกับระบบอื่นครับ(รวมไปถึงรถกำลังจะเข้าเส้นทึบไหม)
แล้วYOLOv5คืออะไรหล่ะ?
หลังจากที่เกริ่นมาเนิ่นนานเราจะมาเข้าหัวข้อหลักของเราคือYOLOv5และแน่นอนว่าYOLOในที่นี้ไม่ได้แปลว่า‘你只活一次’แต่มันคือ‘你只看一次’ซึ่งจะเป็นหลักการทำงานของมันและในปัจจุบันมีถึงVersion 5แล้วโดยตัวYOLOนี้มันคือสถาปัตยกรรมที่ทางUltralyticsได้ออกแบบไว้เพื่อทำ图像检测ได้อย่างรวดเร็วและมีประสิทธิภาพultralytics 
แน่นอนว่าการทำ图像检测นั้นมีหลายวิธีไม่น่าจะเป็นR-cnn,更快的R-cnn,高效Detแต่ข้อดีของYOLOคือจะมีจุดเด่นที่ความไวในการวิเคราะห์ข้อมูลทำให้เราเลือกใช้ตัวYOLOนี้และมีDocumentที่พร้อมรวมถึงCustomizeให้เข้าได้ข้อมูลและเป้าหมายของเราได้
โดยซีรีย์นี้ผมจะยกตัวอย่างการทำ徽标检测จากในรูปครับเช่นเวลาเราเดินห้างถ้าในอนาคต(อีกหลายๆปีเลย)มีแว่นARแล้วใส่เดินห้างแล้วเดินผ่านร้านค้าหรือร้านอาหารมันบอกได้เลยว่าร้านนี้มีโปรโมชั่นอะไรบ้างรูดผ่านบัตรเครดิตนี้ส่วนลดเยอะสุดน่าจะเป็นที่สนใจแต่แน่นอนต้องใช้เรื่องของ图像检测มาดูว่าโลโก้นี้คือร้านอะไรเราจึงมาใช้yoloช่วยครับ
(หลายคนอาจจะสงสัยว่า徽标检测ก็มีวิธีคลาสสิกเช่น关键点检测器ได้แต่พวกวิธีSIFTมันจะมีประเด็นเรื่องของความเร็วครับ)
สำหรับรายละเอียดการเตรียมข้อมูลสำหรับYoloจะอยู่ในบทความถัดไปครับรอติดตามได้เลยถ้ามีส่วนไหนผมเขียนหรืออธิบายผิดสามารถCommentมาบอกกันได้ครับขอบคุณครับ
สำหรับYOLOนี้ข้อดีคือมันเร็วอย่างที่บอกไปเนื่องจากมันจะวิเคราะห์จากรูปครั้งเดียวแล้วทำLabelให้ครอบคลุมทั้งรูป
หลักการทำงานของมันคือจากรูป1รูปเต็มๆมันจะทำการแบ่ง栅格单元格ออกมาเป็นn x n栅格(จากรูปน้องหมาแบ่งไป13栅格ยิ่งแบ่งมากก็จะละเอียด折衷กับการคำนวณ)
แล้วในแต่ละ格网(เช่นบนซ้ายสุด)เราก็ต้องใส่Labelให้มัน(ถ้ามี)เช่น
[pc、bx、by、bh、bw、c1、c2、…,CN]
โดยที่PcคือProbabilityที่มีวัตถุอยู่ใน网格นั้นๆถ้าไม่มีคือ0ถ้ามีคือ1
BX,作者:คือตำแหน่งตรงกลางของObjectว่าอยู่พิกัดไหน
BH、BWคือขนาดความสูงและกว้างของObjectว่าสูง,กว้างขนาดไหน
และc1,c2,..,cnคือผลลัพธ์ว่าเป็น类อะไรถ้าโจทย์เรามีแค่检测น้องหมาก็จะมี类เดียวและ网格นั้นมีค่าเป็น1แต่ถ้ามีหลาย对象ก็จะมีเลขต่อๆไป
(เช่น栅格ตรงกลางของน้องหมาจะมีC1=1โดย栅格อื่นC1=0)
จากLabelด้านบนมันจะรับได้เฉพาะ1 GRIDคือ1 Objectแต่กรณีถ้ามีหลายObjectเราจะใช้หลักการที่เรียกว่า锚盒โดยเราสามารถกำหนดจำนวน盒นี้ได้(เช่น2)ก็จะมีLabelแบบด้านบน2อันใน1网格ได้(เราสามารถกำหนดเลขนี้ได้)และตัวyoloก็จะคำนวณให้ว่ารูปนั้นมันใกล้锚ไหนสุดจากค่า借条ก็จะถูกกำหนดไปที่锚นั้น
แต่สำหรับคนที่เริ่มyoloนั้นอาจจะไม่ต้องสนใจส่วนนี้ก็ได้ตัวyoloมันจะคำนวณมาให้เลยเราสามารถทำแค่บอกว่ามีตำแหน่งObjectอะไรในรูปพอครับ
借条จะมามีส่วนหลักๆหลายส่วนในYOLOเช่นเวลาโมเดลทำนายออกมามันอาจจะทำนายรูปรถเดียวกันแต่หลายกล่องได้เช่น
เราจึงต้องใช้指标借条ในเลือกกล่องเดียวเป็นตัวแทนของ对象นั้นๆครับจากวิธีการ网管โดยหลักการคำนวณคือหาส่วนที่交集หารส่วนที่联合กันถ้ากล่องใดมีค่านี้สูง(เกินThresholdที่กำหนด)แสดงว่ามันคือObjectเดียวกันครับ
และสุดท้ายแล้วผลลัพธ์ของYOLOมันก็จะบอกได้ว่าObjectในรูปมีอะไรบ้างเพื่อนำไปใช้งานต่อไปครับ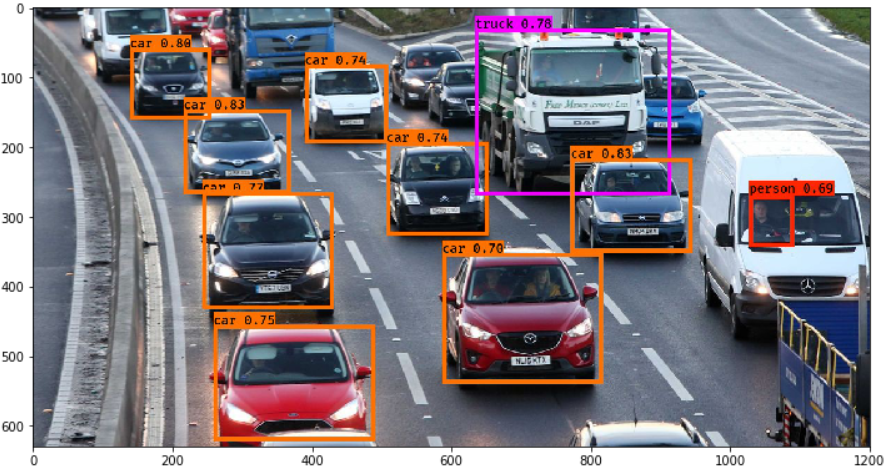
สำหรับDetailหรือคำอธิบายที่ละเอียดกว่านี้สามารถดูได้ผ่านลิงค์นี้ได้เลยครับขอบคุณครับลิงค์นี้
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/28/%e5%9b%be%e5%83%8f%e6%a3%80%e6%b5%8b%e0%b9%82%e0%b8%94%e0%b8%a2%e0%b9%83%e0%b8%8a%e0%b9%89yolov5%e0%b8%88%e0%b8%b2%e0%b8%81%e0%b8%95%e0%b9%89%e0%b8%99%e0%b8%88%e0%b8%99%e0%b8%88%e0%b8%9a%e0%b8%95/
