
物体检测在计算机视觉中仍然是一个流行和具有挑战性的领域,而且有很好的理由:它可以应用于各种现实世界的场景,从自动驾驶过程中识别路标到在制造生产线结束时检测缺陷-甚至从医疗扫描中识别感兴趣的区域。因此,我们可以预期这一领域的兴趣将继续增长。
虽然有越来越多的物体检测模型可供选择,但许多应用程序的热门选择是由Google Brain团队于2020年7月发布的EfficientDet。在出版时,最大的型号(EfficientDet-D7)展示了最先进的结果,近一年后,它仍然是一个受欢迎的选择,在最近的卡格尔比赛中表现得很有竞争力,如全球小麦检测和NFL First和Future-Impact Detection。released by the Google Brain team in July 2020 Global Wheat Detection NFL 1st and Future — Impact Detection
尽管如此,当最近作为Microsoft商业软件工程(CSE)的一部分从事对象检测项目时,我很难找到一个可以快速轻松地适应我的问题的EfficientDet的PyTorch实现;我遇到的实现要么在培训期间耦合到特定的数据集,要么缺少多GPU培训等功能,或者与它们所基于的底层包的最新版本不兼容。
在这里,我的目标是为希望试验EfficientDet的任何人提供一个干净而清晰的起点,方法是提供一个基本的实现,使用PyTorch-Lightning,它可以很容易地适应新的问题。我纯粹关注实现,而不是EfficientDet是如何工作的,因为在这一领域已经有很多优秀的博客文章。另外,由于EfficientNetv2最近发布了,我认为展示如何用它代替EfficientNetv1作为EfficientDet的主干会很有趣。PyTorch-Lightning excellent blog posts in this area already recently been released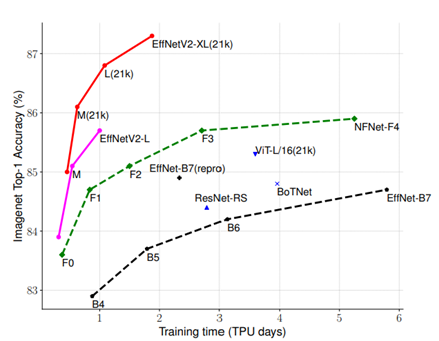
为了使代码尽可能清晰和最小,我选择不包括除培训和验证损失之外的任何度量,因为这些可以稍后根据您的具体问题轻松添加;稍后我将简要讨论如何做到这一点。对于一般的对象检测指标,我推荐我的同事最近创建的repo,它为pycotools包提供了一个干净的接口。a repo recently created by my colleague
使用的软件包包括:
确认
- 对于模型实现和预先训练的权重,这项工作大量使用Ross Wightman令人惊叹的EfficientDet-Pytorch(Effdet)和pytorch-image-model(TIM)软件包。罗斯致力于为整个数据科学界提供最先进的计算机视觉模型的实现,这是首屈一指的。如果你还没有,那就去添加星星吧!
- Alex Shonenkov有一个清晰而简明的Kaggle内核,它演示了使用EfficientDet-PyTorch对EfficientDet进行微调以检测小麦穗;它似乎是我遇到的大多数类似Kaggle解决方案的起点。尽管它与当前版本的EfficientDet-PyTorch已经过时,但它仍然是这项工作的有价值的基础。
- 此实现的大多数强大的开箱即用功能都是使用PyTorch-Lightning的直接结果。由于有很多博客文章概述了使用Lightning的功能和优势,我不在这里介绍它,但是对于那些不熟悉的人来说,Lightning本质上提供了一个干净的界面,您可以使用它来组织您的普通PyTorch代码,这样就可以实现渐变累积和分布式训练等功能,而不需要进一步更改代码-棒极了,不是吗?!
选择数据集
作为示例,我使用了Kaggle Cars对象检测数据集;但是,由于我的目标是演示如何将EfficientDet应用于任何问题,因此这确实是本工作中最不重要的部分。Kaggle cars object detection dataset
由于这个数据集相当小,并且指定的测试集没有标记,为了简单起见,我将重点放在训练集上训练和评估模型。虽然这从来不是作为评估模型性能的方法在实践中应该做的事情,但测试模型是否能够学习任务是一个有用的技巧;如果模型不能在训练集上过度拟合,它显然没有学习任务的能力,并且当模型在新数据上使用时,我们可以预期性能会很差。
此数据集的批注采用.csv文件的形式,该文件将图像名称与相应的批注相关联,我们可以通过将其加载到Pandas DataFrame中来查看其格式。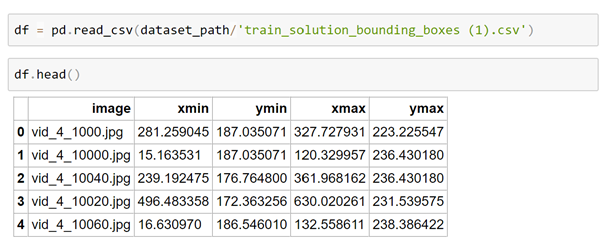
在这里,我们可以看到每一行都将图像文件名与Pascal VOC格式的边界框相关联。
创建数据集适配器
通常,在这一点上,我们会创建一个PyTorch数据集,将此数据提供给训练循环。但是,其中一些代码(如规格化图像和将标签转换为所需格式)并非特定于此问题,无论使用的是哪个数据集,都需要应用这些代码。因此,现在让我们重点创建一个CarsDatasetAdaptor类,它将特定的原始数据集格式转换为图像和相应的注释。这方面的实施如下所示:
由此可以看出,我们实现的主要功能是get_image_and_labels_by_idx方法,它返回一个包含以下内容的元组:
- 图像:PIL图像
- pascal_bbox:形状为[N,4]的数字数组,其中包含Pascal VOC格式的基本事实边界框
- class_labels:包含基本真值类标签的形状N的数字数组
- image_id:可用于标识镜像和__len__方法的唯一标识符
在本例中,此类仅包装随DataSet提供的DataFrame。由于此数据集仅包含单个类,因此始终返回标签1。对于EfficientDet,类应该从1开始,-1用于“后台”类。the classes should start at 1, with -1 being used for the “background” class
此外,由于image_id可以是与图像相关联的任何唯一标识符,因此我们在这里只使用了数据集中图像的索引。为方便起见,我们还实现了show_image方法。调用以显示图像的函数在相应的笔记本中定义。
现在,我们可以创建该类的一个实例,以提供一个干净的界面来查看培训数据,其中的一部分如下所示: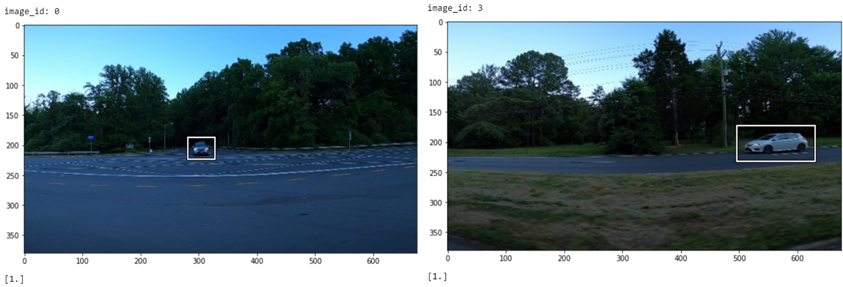
更一般地,我们可以将数据集适配器视为具有以下接口的抽象类:
由于我们使用的是Python,并且拥有“鸭子类型”,因此实际上定义这个基类和子类化似乎有点过分,但希望它能帮助说明所需的接口!duck typing
当使用不同的数据集时,这是更改的部分!
创建模型
现在,让我们看看如何创建EfficientDet模型。多亏了Ross Wightman的effdet和TIMM库,我们在这里有了很多选择。Effdet软件包包括可使用的不同EfficientDet配置的选择。我们可以在下面查看其中的精选内容。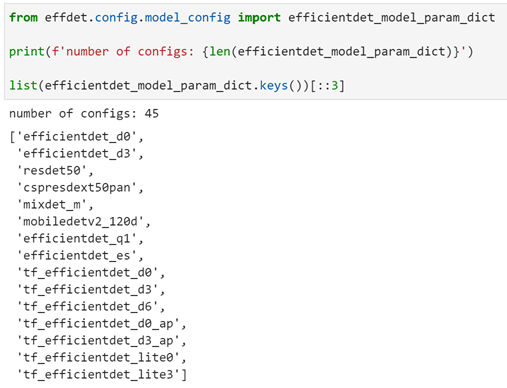
其中一些实现(例如,Efficientdet_d5)已经由Ross在PyTorch中训练过,而任何以“tf_”为前缀的实现都使用官方预先训练的权重。由于初始模型是在TensorFlow中训练的,为了在PyTorch中使用这些权重,已进行了某些修改(例如实现“相同”填充),这意味着这些模型在训练和推理过程中可能会较慢。
除了提供的配置之外,我们还可以使用TIMM的任何型号作为我们的EfficientDet主干。在这里,让我们尝试使用一种新的EfficientNetv2型号作为主干。与前面类似,我们可以使用TIMM列出这些型号: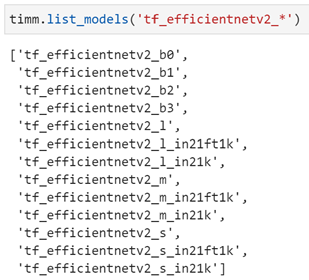
要使用这些模型之一,我们必须首先将其注册为EfficientDet配置,方法是将字典添加到“Efficientdet_model_param_dict”。让我们创建一个为我们完成此任务的函数,然后使用effdet中的机器创建EfficientDet模型:
在这里,一旦创建了EfficientDet模型,我们就会根据当前任务的类数修改分类头。我们已将默认图像大小设置为512,如本文中所用。由于EfficientDet的架构,输入图像大小必须可以被128整除。这里,我们使用默认大小512。现在我们可以使用它来创建PyTorch EfficientDet模型。input image size must be divisible by 128
创建EfficientDet数据集和DataModule
现在,让我们继续加载可以输入到我们的模型中的数据。让我们从定义一些转换开始,在将图像和标签传递到模型之前需要应用这些转换。为此,我们可以使用优秀的Alumentations库,它包含了各种各样的数据增强方法。Albumentations library
在这里,为了简单起见,我们在验证过程中只保留了必要的预处理-因为主干是预先训练的,所以我们需要使用ImageNet数据集的平均值和标准差对图像进行归一化,并调整图像大小并将其转换为张量-并在训练时添加水平翻转。我们可以看到,我们必须将边界框传递给这些转换,因为Alumentations也会将任何转换应用于标签!
正如我们所看到的,添加额外的增强将是一项简单的任务!
既然我们已经定义了我们的转换,我们可以继续定义一个数据集来包装我们的数据集适配器并应用转换。唯一需要注意的是,EfficientDet需要YXYX格式的边界框。我们可以看到这一点的实施情况如下:
虽然我们现在可以使用该数据集来创建标准的PyTorch DataLoader,但是PyTorch-Lightning提供了一个DataModule类,我们可以使用它对所有与数据相关的组件进行分组。界面相当直观,我们可以实现如下方式:
正如我们稍后看到的,除了帮助保持代码的整洁之外,我们还可以在培训期间直接使用它,而不必手动创建DataSet和DataLoader组件。
定义培训循环
好的,还在听吗?我们快到了!在PyTorch-Lightning中,我们将模型、训练循环和优化器捆绑在一个LightningModule中。因此,我们可以执行以下操作,而不必定义自己的循环来迭代每个DataLoader:
训练循环的重要部分在“Training_step”和“Validation_step”方法中捕获。稍后,我们将向该类添加几个额外的方法来处理推理,但是现在,我们已经具备了开始培训所需的全部内容!
训练模型
好的,让我们来训练一下模特吧!因为我们已经将PyTorch-Lightning用于我们的训练循环和数据加载器,所以这一部分非常简单!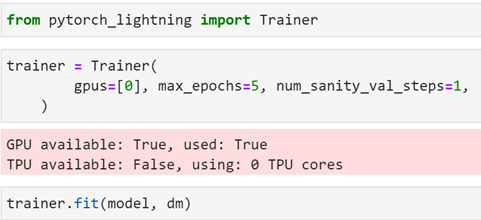
更好的是,尽管我们在这个示例中只使用了一个GPU,但是我们可以在多个GPU上轻松地训练这个模型-甚至跨多个节点-除了更改训练器参数之外,不需要额外的代码更改!
推理
太好了,我们已经训练好模特了!现在让我们看看如何使用它来进行一些预测。让我们首先向前面定义的Lightning模块添加一个预测函数。在这里,我使用了来自FastCore的TypeDispatch修饰符,根据输入类型重载了预测方法。typedispatch decorator from fastcore
正如我们所看到的,在委托给内部“Run_Inference”方法之前,这两种方法基本上都将输入数据转换为所需的格式。让我们深入研究一下这种方法,看看是怎么回事。
从实现中我们可以看到,其中涉及到几个步骤:
- effdet有两个类包装了EfficientDet模型:DetBenchTrain和DetBenchPredict。由于DetBench训练旨在用于训练,因此当将图像传递给模型时,它还需要一组目标,而DetBenchPredict则不需要。然而,这些类的实现非常相似,为了避免在使用模型进行推理之前必须在训练后拆分模型,我认为围绕我们用来训练的同一个类构建推理功能会更简单。为此,我们首先创建一组要传递给模型的虚拟目标,以满足DetBenchTrain类。由于我们对推理过程中的损失不感兴趣,所以这些值是任意的。
- 该模型返回一个向量,其中包含每个图像的边界框、置信度分数和类。我们使用几种方便的方法将其解包,并且只返回得分高于定义阈值的预测。我们还将加权盒子融合应用到预测中,从而将重叠的盒子组合在一起。
- 由于图像在馈送到模型之前调整了大小,因此返回的边界框相对于调整后的图像。要对原始图像使用预测框,我们需要在返回边界框之前调整它们的大小。
现在,我们可以使用预测功能来查看模型的执行情况:
绘制预测框,我们可以将这些与实际情况进行比较: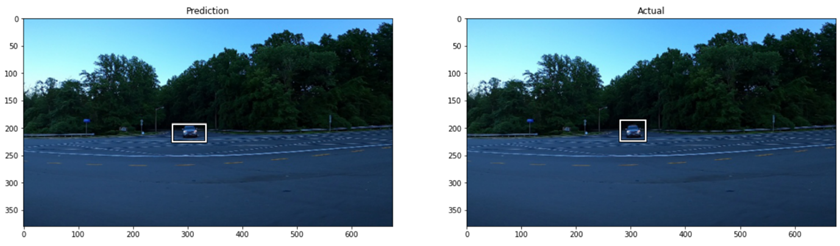
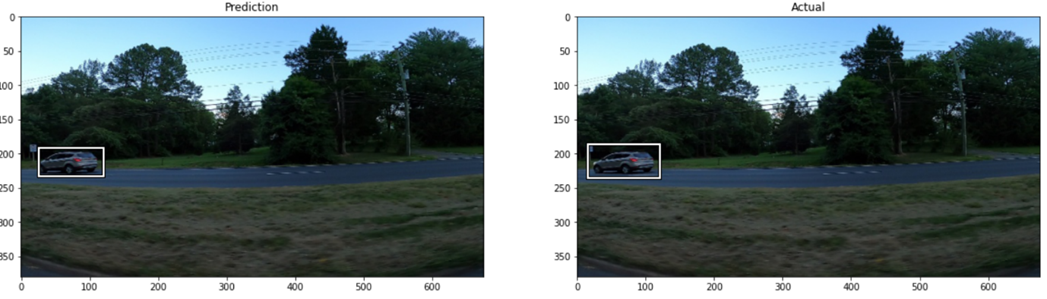
历经五个时代,我们可以清楚地看到,模型已经学会了任务!
使用模型挂钩进行手动调试
验证步骤输出和添加COCO指标
PyTorch Lightning的一个特点是它使用方法或“挂钩”来表示训练过程的每个部分。虽然在使用训练器时我们看不到训练循环的一些可见性,但是我们可以使用这些钩子轻松地调试每个步骤。
例如,我们可以使用DataModule上定义的钩子来获取验证期间使用的DataLoader,并使用它来获取批处理。
我们可以使用此批来精确查看模型在验证期间计算的内容。使用模型的钩子,我们可以看到在每个验证步骤中为每个批次计算的内容。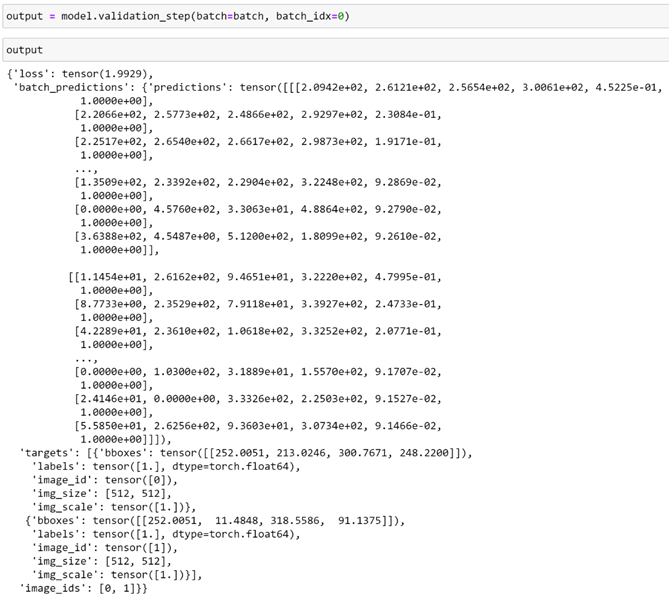
在这里,我们可以看到该批次的损失以及预测和目标。要计算纪元的指标,我们需要获得对应于每个批次的预测。由于将为每个批调用“VERIFIATION_STEP”方法,因此让我们定义一个函数来聚合输出。
在这里,为简单起见,我们使用来自FastCore的便利修饰器将此函数修补到EfficientDet类-我们为Python是一种动态语言付出了很高的性能代价,所以我们不妨充分利用它!convenience decorator from fastcore
从Pych-Lightning文档中可以看到,我们可以添加一个额外的挂钩“VALIDATION_EPOCH_END”,该挂钩在所有批处理完成后调用;在每个时期结束时,步骤输出列表将传递给该挂钩。我们可以这样定义这一点:PyTorch-lightning docs
让我们使用这个钩子来计算总体验证损失,以及使用“objDetecteval”包计算COCO指标。为了说明这是如何工作的,我们可以使用在评估单个验证批次时刚刚计算出的输出,但此方法还将扩展到使用Lightning进行培训期间的验证循环评估。objdetecteval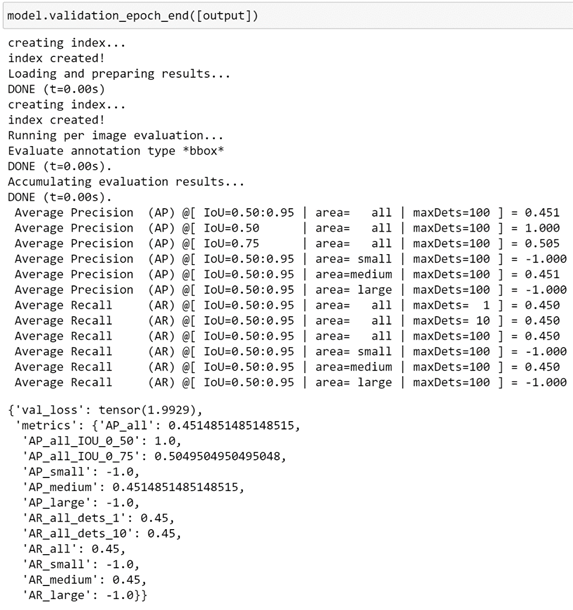
在这里,我们可以看到,除了所有批次(在本例中只有一个批次)的平均验证损失之外,还返回了COCO指标。
使用钩子进行推理
我们还可以直接对从数据加载器返回的已处理图像使用预测函数。现在让我们解开批次以获得图像,因为我们不需要标签来进行推断。
多亏了“类型调度”修饰符,我们可以在这些张量上使用相同的预测函数签名。
在这一点上需要注意的是,DataLoader给出的图像已经被转换并缩放到512大小。因此,对于512的图像,预测的边界框是相对的。因此,要在原始图像上可视化这些预测,我们必须调整它的大小。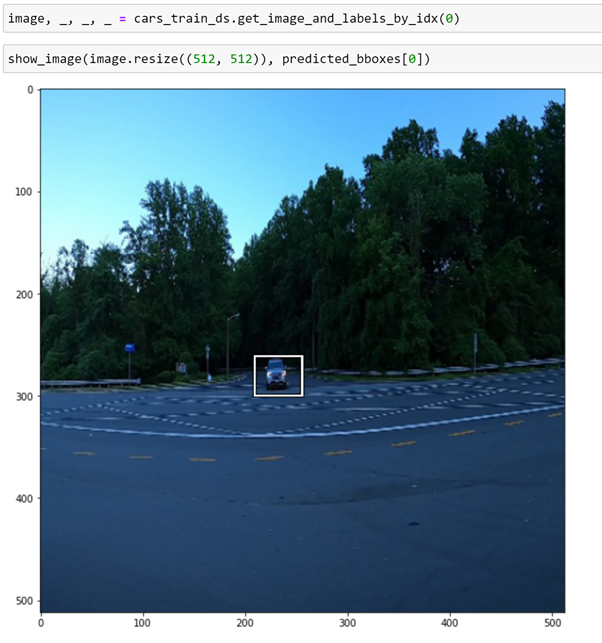
正如我们所看到的,调整大小后,边界框处于正确的位置!
结论
我希望您会发现这篇文章很有用,并且它可以作为您在PyTorch中试验EfficientDet的起点!
复制这篇文章所需的所有代码都可以在这里作为GitHub的要点获得。虽然在本文中使用ASTER作为代码片段,但这主要是出于美学原因,如果直接复制这些代码片段可能无法按预期工作。对于工作实现,请遵循该要点。here
克里斯·休斯在LinkedIn上。LinkedIn
参考文献
- [1911.09070]EfficientDet:可伸缩且高效的对象检测(arxiv.org)
- EfficientNetV2:更小的模型和更快的培训(arxiv.org)
- PyTorch Lightning文档-PyTorch Lightning 1.4.0dev文档(pytorch-lightning.readthedocs.io)
- EfficientDet-可扩展且高效的对象检测|致力于更美好的未来(amaarora.github.io)
- rwightman/Efficientdet-pytorch:忠实于原始Google Implementw/Ported Weight(github.com)的PyTorch EfficientDet Impll of EfficientDet
- rwightman/pytorch-image-model:PyTorch图像模型、脚本、预先训练的权重-ResNet、ResNeXT、EfficientNet、EfficientNetV2、NFNet、Vision Transformer、MixNet、MobileNet-V3/V2、RegNet、DPN、CSPNet等(github.com)
- [培训]EfficientDet|Kaggle
- 从PyTorch到PyTorch Lightning–威廉·法尔孔|对数据科学的温和介绍
- alexhock/对象检测指标:用于分析对象检测指标的Python代码(github.com)
- https://medium.com/@nainaakash012/efficientdet-scalable-and-efficient-object-detection-ea05ccd28427
- https://realpython.com/lessons/duck-typing/
- [1910.13302]加权盒子融合:整合来自不同目标检测模型的盒子(arxiv.org)
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/28/%e4%bd%bf%e7%94%a8pytorch-lightning%e5%9f%b9%e8%ae%adefficientdet%e8%87%aa%e5%ae%9a%e4%b9%89%e6%95%b0%e6%8d%ae%e4%bd%bf%e7%94%a8efficientnetv2%e4%b8%bb%e5%b9%b2/
