
原論文標題為跟踪对象作为点,把物件視為一個點來追蹤,屬於无锚点的方法,用CenterNet改進的方式,預測物件的位移來做物件追蹤
CVPR 2020
引言
作者利用中心、把每個物件都視為一個點,透過與前一幀圖片热图的关联、得到兩張圖片同物件上有著高度關聯
另一點比較特別的是中心跟踪訓練時用大量的增强,讓模型足以在靜態的圖片上學習跟蹤目標,而不用輸入真正的影片
相关工作
很多追蹤模型都是靠先檢測出物件,然後再去把物件在每一幀的關連做出來,缺點是要靠兩個模型,速度慢,運算成本也高
然後本篇論文的模型有個特別之處,就是物件的關聯是跟著物件檢測一起學習出來的,關聯學習幾乎不耗費任何運算,並且輸入時除了當前幀之外還會把前一幀一同輸入,從這個線索中找尋被遮擋或是消失的對象
因為Tracking-by-Detect存在上述缺點,近年來越來越多追蹤器結合這兩項任務,並且套用掩模R-cnn框架來實現,掩模R-cnn的方法很仰賴同一個物件在兩幀之中位置不會相差太多,這樣裡頭的区域建议才能從鄰近區域抓到物件,但如果在低幀率的影片中,同一個物件在兩幀的位置就會差很多,導致掩模R-cnn不管用
而本篇論文的方法,將動作預測和热图都輸入到網路中,即使兩個物件在兩幀上離很遠也抓得出來
约翰·卡尔曼过滤(運動預測在追蹤器中扮演重要腳色,以往的論文使用Kalman Weibo),來預估物件下一幀的位置大概會坐落在哪裡,而本篇論文的運動預測包含在網路中和檢測一同學習,不需要特別監督
生成热图不只用當前的帧、也會參考前一個帧、因為前一幀的資訊已經算好了,參考他的結果並不會減慢速度,在尋找被遮擋的物件時,更可以保留先前的資訊
物件檢測可用3D物件偵測來取代
预赛
CenterNet原理大概是,每個物件都有自己專屬的熱圖(热图)、物件的中心點就是熱圖的中心點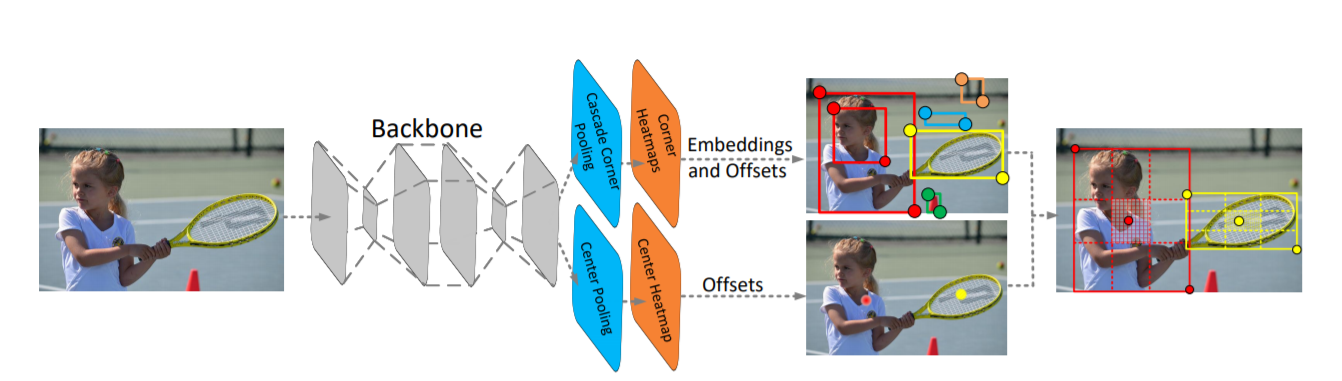
将对象作为点进行詳情請參考Objects as Points
将对象作为点进行跟踪
當物件被遮擋時,幾幀後再次出現,就會被賦予新的ID、這是追蹤常遇到的問題,作者認為,我們應該把這個問題歸咎於ID在連續幀上的保持,而不是獨立看到每一幀的物件間進行連結
在時間t時,現在的輸入是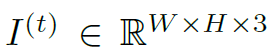
跟上個帧t-1
上個帧的物件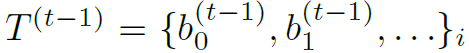
給個物件存放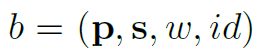
- P是中心點座標
- %s是長寬
- ω是检测置信度
- ID指他被賦予的ID

我們的任務是把這個Frame和上個Frame相同的物件給予相同的ID,這會面臨到兩個挑戰
跟踪条件检测
CenterTrack一次輸入兩的Frame、分別是現在t時間的Frame以及上一個Frame t-1、因為有些物件在t時間被遮擋住,在t-1的時後卻還在,這樣能幫助他辨認
除了輸入前一幀的圖片外,還又額外輸入前一幀的热图結果,只要前一幀那個物件的热图置信度大於τ(阈值)、就傳入當前幀
通过偏移关联
有了前一幀的热图、模型會額外輸出一個2D的偏移預測(置换)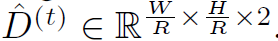
上圖的偏移在Ground Truth上的算法是,物件在當前t的中心點減去t-1時的中心點,下圖的p是中心點座標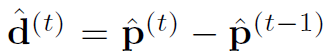
损失的計算如下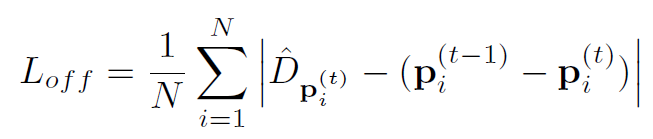
下圖在說明中心跟踪的輸入和輸出
輸入:
- 現在的圖片,上一幀的圖片,上一幀的热图
輸出
- 检测、大小、偏移(位移)
之後用贪婪匹配把相近的物件當成是同一個物件,贪婪匹配就是先把離最近的連起來,通常這樣做的Cost也接近於最佳解。此時設定一個距離κ,如果這個物件在距離κ以內都沒有人可以與他相連,就把他設為新出現的物件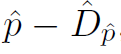
p是現在的位子D是預測出來的偏移量,所以p-D的結果是回到前一個位置的意思,回到前一個位置的新座標,就可以跟上一幀物件的座標匹配
关于视频数据的培训
從Centernet到CenterTrack的架構變化很少,僅僅多了4個输入通道和2個输出通道,也可以用Centernet的预训重量微调就好了
訓練中心跟踪時,最主要的挑戰源自於如何生成一張真實的堆映射,為了讓模型更強健,作者使用了三種扩充
而輸入t-1幀也不用真的是當前輸入的同一幀,只要是同一支影片中的Frame即可,避免在Frame Rate上过拟合
静电图片数据培训
中心跟踪可以在只有偵測的Ground Truth上訓練,至於前一幀要怎麼來,作者說可以利用隨機縮放和平移當前幀來模擬前一幀
端到端3D对象跟踪
3D物件偵測上還有多一些資訊,像是深度和旋轉那些的,從2D變成3D的中心點也會不太一樣,要多預測一個中心點偏移
实验
数据集
- MOT17
- 凯蒂
- NuScenes
评估指标
- MOT常見的指標,MOTA、IDS那些
表1:MOT17的結果,+D代表偵測時間
表2:KITTI測試結果
表3:NuScenes測試結果
表4:消融研究,
- 仅检测的意思是只有Centernet和單純用中心點位子把物件做關聯
- 无偏移把置换的偏移都設為零,然後依樣輸入前一幀的热贴图
- 没有热图不把上一幀的热图輸入當前幀
雖然沒有Offset的結果沒有差很多,但是如果輸入Frame Rate比較低的影片,物件移動的幅度較大,偏移還是能提供較好的幫助
表5:是一些額外實驗、
- W.O.嘈杂的Hm沒有加入擾動热图這像增强
- 静电图片使用圖片訓練,而不是用影片
- W.匈牙利匹配時不用贪婪演算法,改用匈牙利算法
- W.重生過幾幀沒有被匹配到,就給新的ID(設定32幀,MOT才需要)
表6:更換運動模型
- 无运动就是把偏移設為零,跟上面有一個實驗一樣
- 卡尔曼过滤可以稍微預測下一幀軌跡
- 光流光流法,有興趣可以去查一下
- Our就是上面介紹的Offset方法
我們可以看到現有的方法沒有一個是在3種不同DataSet中都有好成績,除了作者提出的預測Offset這個方法,這其實仰賴了大量的Data Engrading,才能把Offset訓練好
下面為圖像化的結果
结论
中心跟踪的概念其實滿簡單的,先用中心网找出物件,然後用預測未移的方式(偏移)來跟前一幀的物件匹配,匹配的方式也是最簡單快速的贪婪演算法(距離最短就直接匹配在一起)
最令我感到意外的是,如果沒訓練時沒有加入热图噪声,準確度竟然會從66.1大幅下降到34.4,讓我意識到有時後要突破極限,靠的不一定是模型有多優秀,訓練的方式也很重要
他們也提出静电镜像的方式來訓練,這樣就不需要影片,只要用有Detect的圖片訓練,畢竟訓練資料標記物件ID是一件很麻煩的事情,我發現現在大家都在想不用影片的訓練方式、FairMOT就提出Self-Supervisor、把偵測到的物件做Data Augaging來訓練Re-ID分支机构、也就是說用少了ID訊息訓練模型也是個好方法
代码
原廠程式碼,但我猜應該很難讀,因為中心网的程式碼就很難讀
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/30/%e4%b8%ad%e5%bf%83%e8%b7%9f%e8%b8%aa%e5%99%a8%e5%b7%a5%e5%85%b7%ef%bc%9a%e5%b0%86%e5%af%b9%e8%b1%a1%e4%bd%9c%e4%b8%ba%e7%82%b9%e8%a9%b3%e7%b4%b0%e4%bb%8b%e7%b4%b9%e8%bf%9b%e8%a1%8c%e8%bf%bd%e8%b8%aa-2/
