
卷积神经网络:简介
花点时间观察并环顾四周。即使你™静静地坐在椅子上或躺在床上,你的大脑也一直在试图分析你周围的动态世界。如果没有你有意识的努力,你的大脑就会不断地创造预测,并根据预测采取行动。
仅仅看了一下这张照片,你就认出了海滩上的一家餐厅。你立刻认出了场景中的一些物体,比如盘子、桌子、灯等。你很可能猜到,天气很适合夜间散步。但是,你能做出这些预测吗?但是,你有没有在照片里建立很多物体呢?
大自然花了很多年的进化才取得了这一杰出的成就。我们的眼睛和我们的大脑非常和谐地工作,创造了如此令人惊叹的视觉体验。为我们创造这种潜力的系统是我们大脑中的眼睛、视觉通路和皮质区。
我们体内的一个系统允许我们理解上面的图片、本文中的文本以及我们每天执行的所有其他视觉识别任务。
我们™从孩提时代起就这样做了。我们学会了辨认狗、猫或人。我们能教计算机这样做吗?我们能制造出一台能像人类一样看得懂、看得懂的机器吗?
答案是肯定的!同样,孩子是如何学会识别物体的,我们需要向算法展示数百万张图片,然后才能概括输入,并对以前从未见过的图像进行预测。
计算机欧元œ看到欧元�世界的方式与我们所做的截然不同。他们只能看到œ�某种数字,大概是这样的:
教计算机从这一组数字中找出意义是一项具有挑战性的任务。计算机科学家花了几十年的时间建立能够理解图像的系统、算法和模型。今天,在人工智能和机器学习的时代,我们在识别图像中的对象、识别图像的上下文、检测情感等方面取得了显著的成功。卷积神经网络(CNN)是目前最受欢迎的计算机视觉算法之一。
卷积神经网络:
卷积神经网络具有不同于常规神经网络的设计。传统的神经网络通常通过一系列隐藏的神经网络层来转换输入。每一层都是由一组神经元组成的,其中每一层都完全连接到之前层内的所有神经元。最后,欧元œ输出层-欧元�是表示预测的最后一个完全连接层。
卷积神经网络有点不同。首先,每一层都被组织成三个维度:宽度、高度和深度。此外,一层中的神经元并不只与随后一层中的所有神经元连接到一个很小的区域。最后,最终输出将被缩减为沿深度维度组织的一个似然分数向量。
CNN由两大部分组成:
- 特征提取:在这一部分中,神经网络执行一系列卷积操作和汇集操作,通过这些操作来检测特征。如果你有一张斑马图,这是网络会承认它的条纹、两只耳朵和四条腿的部分;
- 分类:在这里,完全连通的层在这些提取的特征之上起分类器的作用。他们将为图像上的对象指定算法预测的可能性。
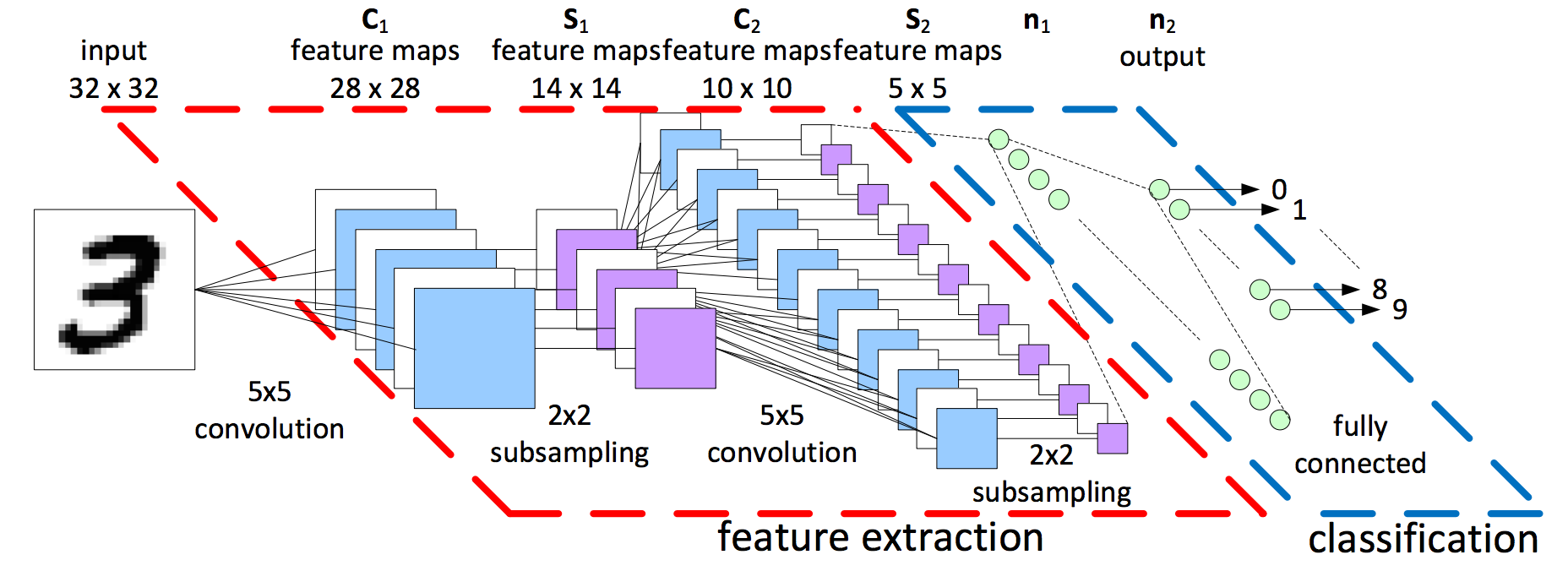
红色虚线区域内有方块和线条,稍后我们将对其进行分析。图像右侧蓝色虚线区域内的绿色圆圈称为分类。该神经网络或多层感知器区域充当分类器。此图层(特征提取)的输入来自前面称为特征提取的部分。
无论这个网络从何而来,特征提取都是CNN设计的一部分。卷积是这个算法程序有效性的核心数学运算。让™在更高的层次上感知红色自我封闭区域内发生的事情。红色区域的输入是我们想要分类的图像,因此输出可能是一组特征。以特征为例来考虑图像;例如,猫的图片可能需要胡须、两只耳朵、四条腿等特征。手写数字图像可能需要水平和垂直线或环和曲线等特征。稍后我将向您演示如何从图像中提取这些元素。
特征提取:卷积
cnn中的卷积层是使用过滤或内核在大专学位输入图像上执行的。要了解滤波和卷积,您需要从左到右扫描屏幕,并在覆盖屏幕-™的宽度后向下移动一步-重复相同的过程,直到您-™正在检查整个屏幕。
例如,如果输入的图片和过滤看起来是这样的: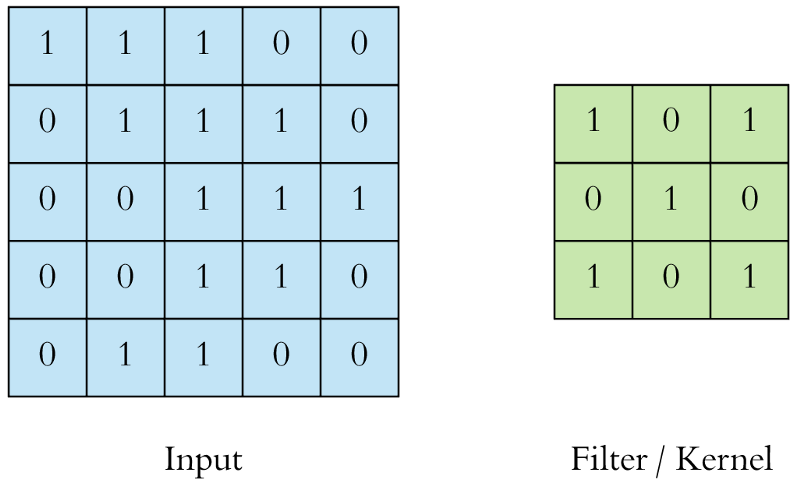
过滤(绿色)从左上角开始一次滑过输入图像(蓝色)一步(像素)。上面编写的过滤将其值与图像的重叠值相乘,然后在其上滑动并将所有值相加,为每个重叠输出一个值,直到遍历整个图像: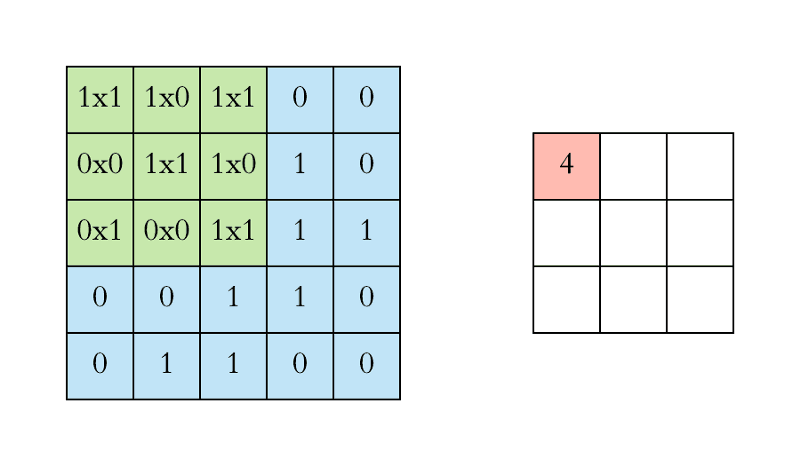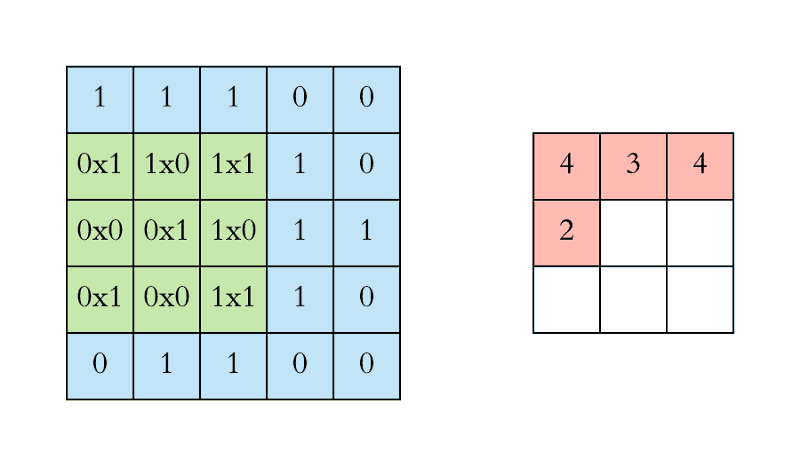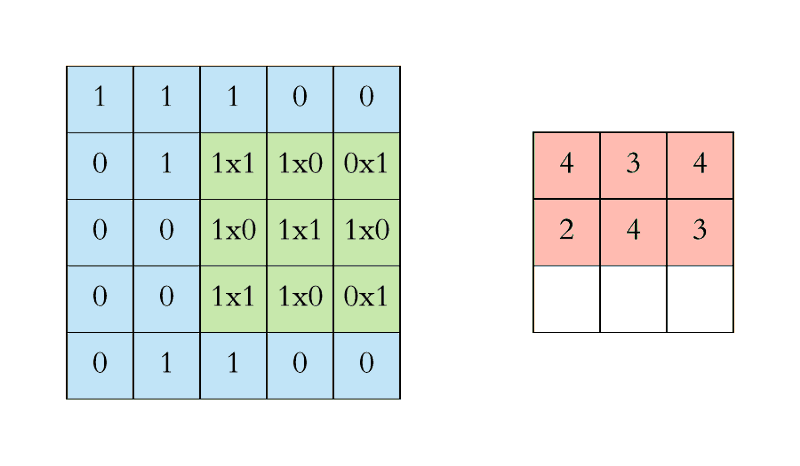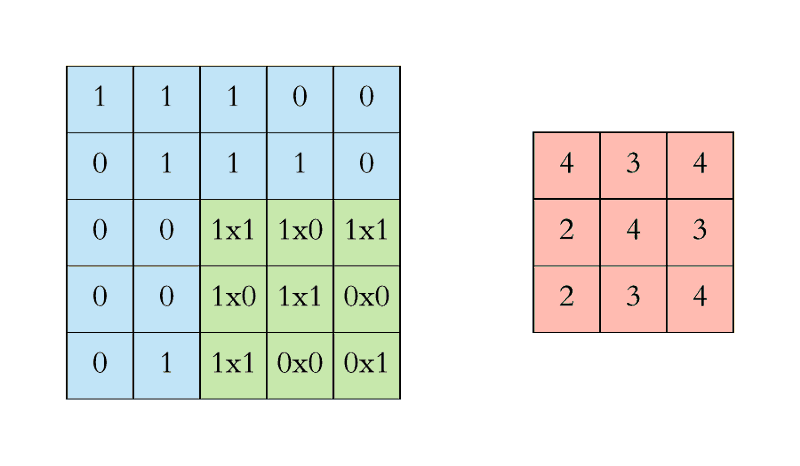
在上面的GIF动画中,红色(右上)输出矩阵中的值4(左上角)对应于图像左上角的过滤重叠,我们计算如下: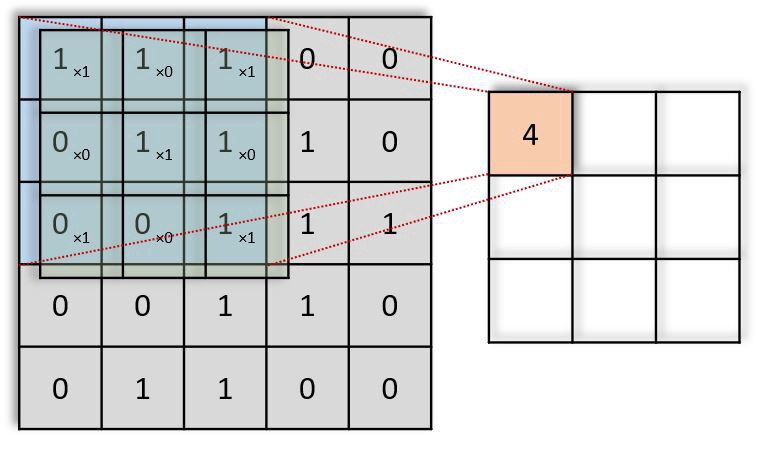
(1×1+0×1+1×1)+(0×0+1×1+1×0)+(1×0+0×0+1×1)=4
类似地,我们倾向于计算输出矩阵的相反值。请注意,输出矩阵内的左上值(4)仅取决于原始图像矩阵左上角的九个值(3×3)。即使图片中的值的睡觉改变了,™也不变。这是我们CNN中这个输出值或神经元的接受场。输出矩阵中的每个值都对原始图像中的特定区域敏感。
在具有多个通道(例如,RGB)的图像中,内核具有输入图像的恒定深度。在ğ��?ğ�‘>和ğ��?ğ�’>堆栈([ğ��?1,ğ��?1]、[ğ��?2,ğ��?2]、[ğ��?3,ğ��?3])之间执行矩阵运算,并将所有结果与偏置相加,为我们提供压缩的单深度通道卷积特征输出: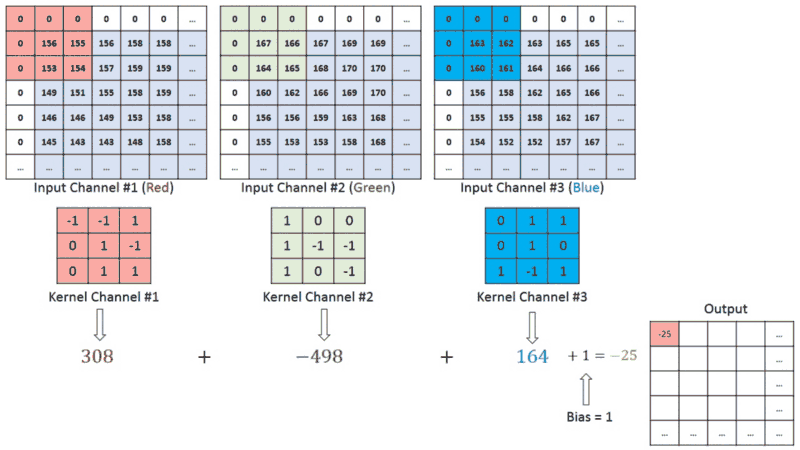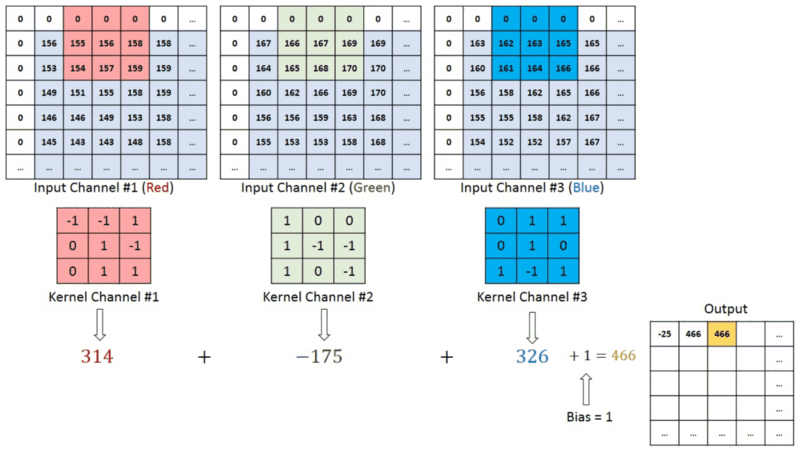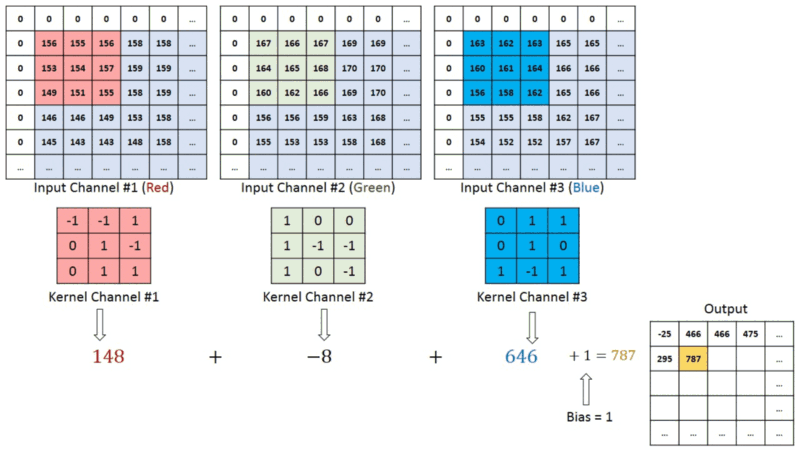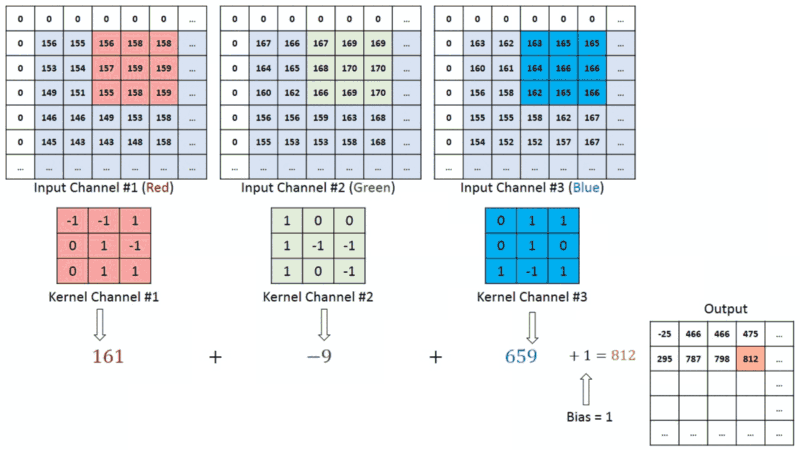
输出矩阵内的每个神经元都有重叠的感受区。下面的动画可以让您更好地了解卷积过程中发生的事情。传统上,主ConvLayer负责捕获边缘、颜色、渐变方向等低层特征。有了更多层,体系结构可以适应高层特征。它为我们提供了一个网络,包括对数据集中图像的全面理解,就像我们可能做的那样。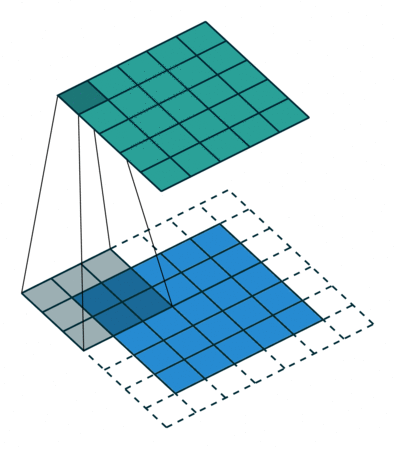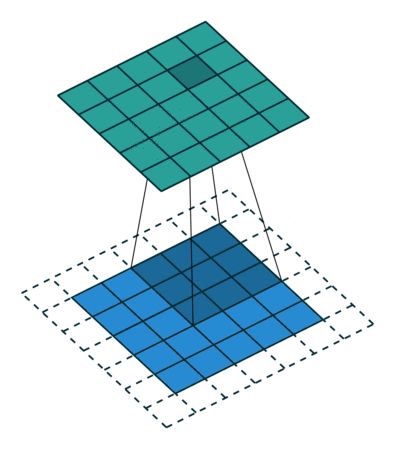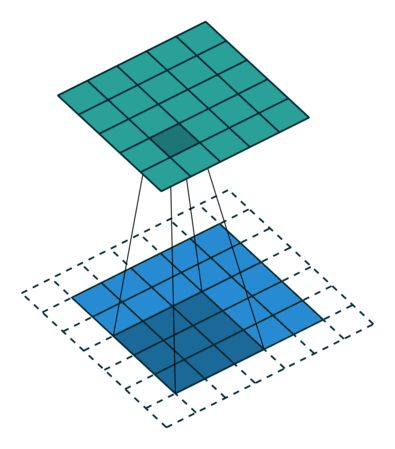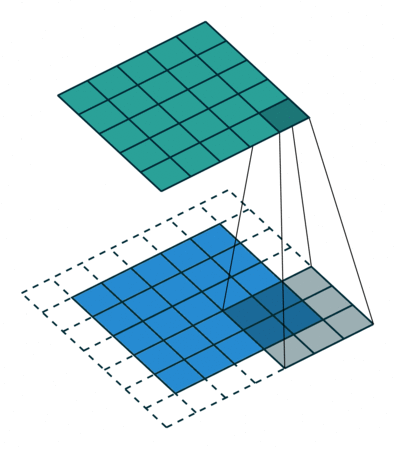
特征提取:填充
操作有两种类型的结果。第一种是当与输入相比,卷积特征的维数降低时。第二种是当维数增加或保持不变时。这是通过应用有效的填充物或在后者的情况下应用相同的填充物来实现的。在上面的示例中,我们的填充是1。
在我们的示例中,当我们将5x5x1图像增加为7x7x1图像,然后在其上应用3x3x1内核时,我们发现卷积矩阵的维度为5x5x1。这意味着我们的输出图像具有与我们的输出图像完全相同的尺寸(相同的填充)。
另一方面,如果我们在没有填充的情况下执行相同的操作,我们将在输出中收到尺寸缩小的图像™。因此,我们的(5x5x1)图像将变为(3x3x1)。
特征提取:示例
假设™‘s有一个书写的数字图像,如下图所示。我们只想从图像中提取水平边缘或线条。我们将使用过滤或内核,一旦与初始图像缠绕在一起,所有那些没有水平边缘的区域都会变暗:过滤(™)或内核(Kernel),一旦与初始图像缠绕在一起,所有那些没有水平边缘的区域都会变暗:
请注意,输出图像只有一条水平白线,图像的睡觉是暗淡的。这里的核心就像一个窥视孔,是一个水平的狭缝。同样,对于垂直边提取器,过滤类似于垂直狭缝窥视孔,输出将如下所示:
特征提取:非线性
在将过滤滑动到原始图像上之后,输出将通过另一个称为激活函数的数学函数。在CNN特征提取中,大多数情况下常用的激活函数是RELU,也就是纠正线性单元。这只会将所有负值转换为零,并保持正值不变: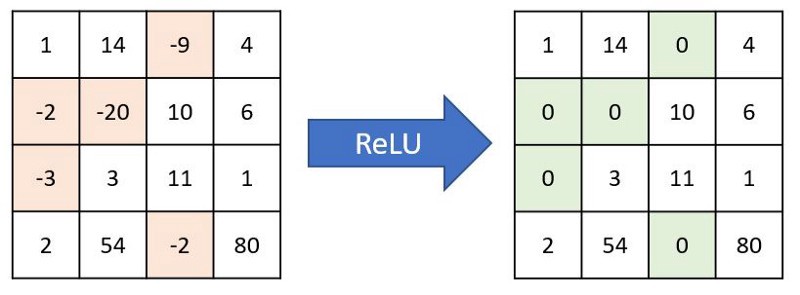
通过relu函数传递输出后,它们如下所示:
因此,对于一幅图像,我们可以通过将其与各种滤波器卷积得到多幅输出图像。对手写数字分别采用水平边缘提取器和垂直边缘提取器,得到两幅输出图像。我们可以使用其他几个过滤器来生成更多这样的输出图像,也称为特征地图。
特征提取:池化
经过卷积图层处理后,一旦我们得到了特征地图,在™图层中添加一个池或子采样层是很常见的。与卷积层一样,池层负责减小卷积特征–™的抽象大小,这通常会通过空间缩减来降低处理数据所需的计算能力。混合训练缩短了训练时间,并控制了过度适应。此外,它还有助于提取主导特征的旋转和位置不变性,从而有效地训练模型。
有两种类型的池化:
- 最大池化过程从内核覆盖的图像部分返回最大值。Max Pooling还起到了抑制噪音胃口的作用。它完全丢弃了噪声激活,并随着降维而额外地起到去噪的作用。
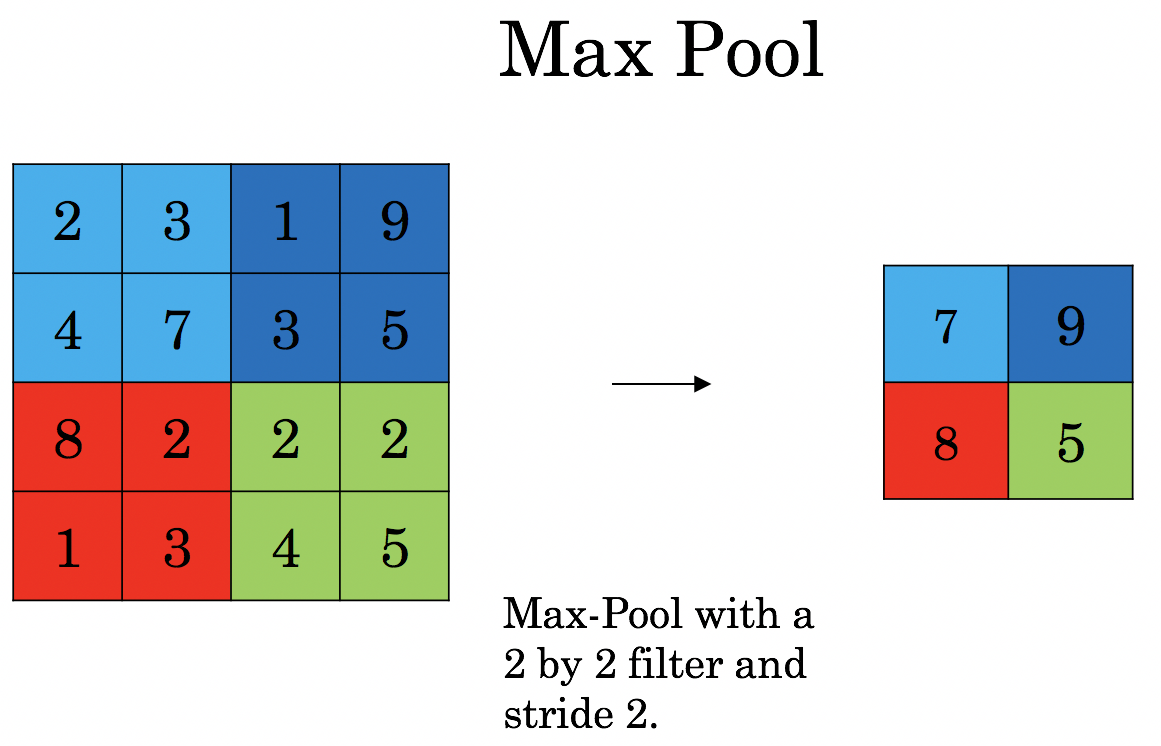
- 平均池化过程返回内核覆盖的图像部分的所有值的平均值。平均汇集仅执行作为噪声抑制机制的空间性降低。因此,我们可以说Max Pooling的性能比平均Pooling要好得多。

卷积层和汇聚层构成卷积神经网络的第i层。根据图像中的复杂性,这些层的数量也会被夸大,以进一步捕捉低级别的细节,但代价是额外的计算能力。
在经历了上述方法之后,我们成功地实现了™,并使模型能够理解这些特性。此外,我们将扁平化最终的输出层,并将其馈送到常规神经网络以用于分类目的。
分类?欧元“全连接层(FC层):
添加完全连接层可能是通过卷积层的输出学习高级特征的非线性组合的(通常)低成本方法,如下所示。完全连接层理解该空间中的假定非线性函数。CNN网络示例:
既然我们已经将输入图像转换为可接受的类型,那么我们将倾向于将图像展平为列向量。我们将平坦的输出馈送到前馈神经网络,并对每个训练迭代应用反向传播。经过一系列的历时,该模型可以区分图像中的主要特征和特定的低层特征,并利用Softmax分类技术对它们进行分类。
因此,目前,我们已经准备好了制作™所需的所有组件。卷积、重排和合并。我们将最大值汇集的输出提供给我们最初提到的分类器,该分类器通常是一个多层感知器层。通常,在cnnâuro™中,这些层被多次使用,即卷积->RELU->MAX-POOL->卷积->RELU->MAX-POOL等等。我们不会在本文中讨论完全连接层(Full Connected Layer)。™
结论:
CNN是一种非常强大的算法,广泛应用于图像分类和目标检测。图像的层次结构和强大的特征提取能力使CNN对于各种图像和对象识别任务具有很强的鲁棒性。
卷积神经网络的各种架构是构建算法的关键,这些算法将在可预测的未来为人工智能提供动力。其中有ZFNet、AlexNet、VGGNet、LeNet、GoogLeNet、ResNet等。
感谢阅读!在我接下来的教程中,我们将开始使用TensorFlow构建我的第一个™模型。
最初发表于https://pylessons.com/CNN-tutorial-introductionhttps://pylessons.com/CNN-tutorial-introduction
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/31/%e5%8d%b7%e7%a7%af%e7%a5%9e%e7%bb%8f%e7%bd%91%e7%bb%9c%e5%88%86%e6%ad%a5%e4%bb%8b%e7%bb%8d/
