
当我在深度学习(DL)的旅程中前进时,我注意到通过搜索网站和论坛来寻找问题的答案变得更具挑战性。所以我发现把我的经历写在博客上更重要。它将促进我自己和其他人的学习。
对于那些正在使用Fast.ai进入DL的人,我建议您也参考一下之前的这些博客:
a.DL的必要准备信息:CoLab的设立、安装和导入;
b.有关从互联网下载和收集图像的说明;
c.可用于处理、培训、可视化结果和启动简单应用程序的步骤。
2.培养深度学习的品味包括:Developing a taste for Deep Learning
a.介绍DL术语的简单定义;
b.很好的资源,您可以在那里找到可以使用的数据集;
c.关于如何转换图像的示例;
通过玩弄学习率、历时数和模型深度来改进模型的方法的图解。
前两个博客的主题是根据照片上的单个主要对象对图像进行分类。在本博客中,我们将尝试训练多标签或多类别分类模型。我们的目标是提出一种模型,可以预测图像中的一个或多个对象或没有主要目标对象。
我们开始吧:
收集数据的方式多种多样。Fastai提供了一个包含包含友好格式的玩具数据集的库。我选择使用来自外部网站的数据,这样我就可以熟悉使用真实世界数据的挑战。
检查是否有与图像相关联的注释(即标签)。有时批注来自不同的文件或文件夹,有时它们派生自文件名或源。如果你有时间,你也可以自己给它加注释。
对于这个迷你项目,我必须找到一个在一些图像上包含多个标签的标签。它涉及的是在水族馆中可以找到的活动物,你可以在这里查看来源。here
2.确保您的编码平台可以访问数据。
我用谷歌可乐来编码。以下是使Colab能够查找您的数据的步骤:
a.将您的数据上传到Google Drive。“路径”将与您的数据在Google Drive中放置的层次结构相关。
b.打开Colab笔记本,进行安装和导入: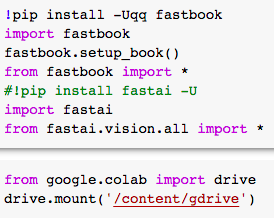
c.一个可能的替代/补充步骤是在Colab中安装Drive:
I.单击屏幕左下角的命令调色板,或从工具栏上的工具中单击。
二、二、查找装载驱动器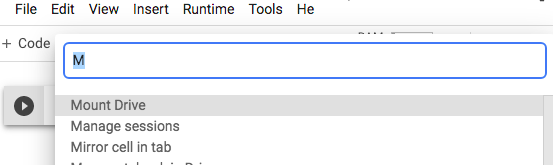
三、三、通过单击连接来访问Google Drive。
3.给出在哪里可以找到数据的说明(即路径)。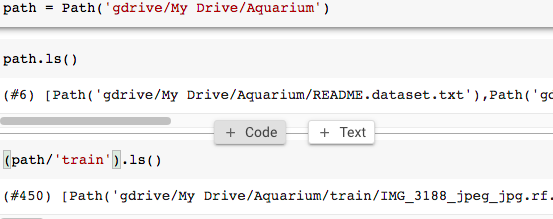
4.资料的初步探索。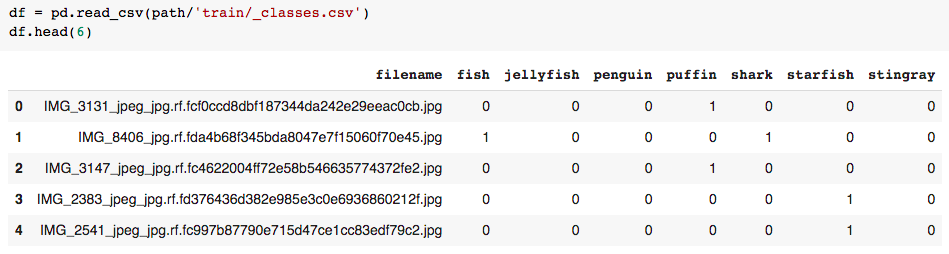
文件名很长,除了img_number之外,内容看起来并不重要。但是,根据我玩这套的经验,没有必要清理这段文字。我们将保持df.filename不变。
数据以编码的方式呈现。有7种可能的标签。1编码存在,0编码不存在指定的对象标签。我们在这里看到一个多标签的早期例子:索引1既被标记为“鱼”,也被标记为“鲨鱼”。
这个迷你项目将遵循Fast.ai关于多类别分类的第6课。我们将设置与本课中使用的Pascal数据集类似的数据格式。在Pascal数据集中,标签是在单个列中找到的,因此我们将颠倒编码。lesson 06
5.准备标签。
a.标明标明存在的对象名称。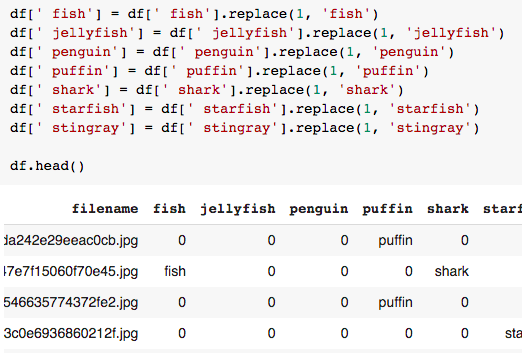
b.将标签合并为一列。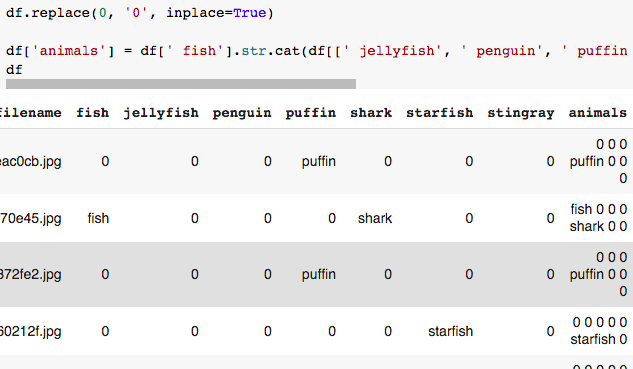
c.考虑图像中没有可识别对象的可能性。
d.清理标签栏。
删除0和空格。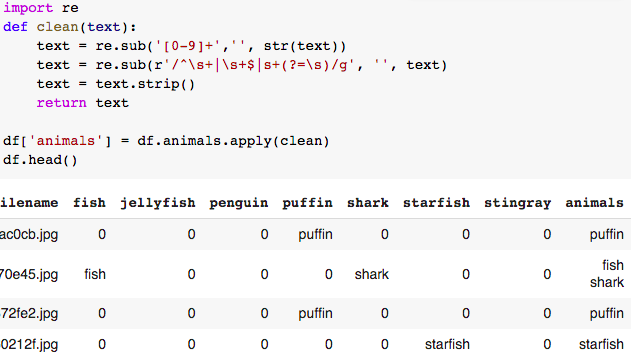
我们现在已经在一个df.Animals专栏中收集了所有阳性标签。
6.准备数据块。
数据块是使您能够生成数据集和数据加载器的说明。这些都是基于PyTorch结构化的。其思想是将数据代码与模型代码分开。数据集将存储数据和标签,并且作为元组,它不能更改。在数据集中找到的数据将在DataLoaders中进行处理。在数据加载器上应用模型训练。PyTorch structuring
在前两个博客中,我们使用了一个完全构造的数据块,并检查了DataLoaders上的输出。
在本博客中,我们将一次构造一个数据块的元素,并在继续使用DataLoaders之前首先检查数据集的输出。
a.基线数据块。
从一个空的数据块开始(尚未给出明确的指令),请注意它已经将数据划分为训练集和验证集。您可以选择自己控制拆分,但是对于这个小型项目,我们将保留拆分的默认值。
b.设置因变量(Y)和自变量(X)。
- 对于get_x:仅返回文件名不会生成图像数据。必须通过指定路径来告诉它在哪里可以找到数据。
注意:这是与df.filename的唯一交互。因此,没有必要花费时间清理df.filename的文本,甚至可能导致误导。
- 对于get_y:‘Animals’与我们在前面步骤中准备的目标标签的列名相关。Split函数是在我们的结果中提供适当的文本/字符结构所必需的,我们将在后面看到这一点。
注意:从理论上讲,get_y也应该能够处理数据,但是,我尝试在此步骤中包含清理过程并没有得到预期的结果。因此,我在将数据分配给数据块之前移动了清理步骤。
- 从输出中可以看到,我们仍然有可以清除的空白条目。但就目前而言,我们将继续前进。
c.直观地检查示例,看看我们的数据块说明是否进展顺利。
数据集的输出显示了鱼和鲨鱼的标签,我们可以通过亲眼检查来确认这个标签的准确性。我看到可能代表鱼和/或鲨鱼的物体。
- 注意:此时,我们不会讨论注释是好是坏。
d.指明我们将处理的数据类型。
- ImageBlock使我们能够处理图像(从技术上讲,使用Python成像库(PILImage))。
- MultiCategoryBlock使我们能够处理具有多标签分类目标的数据。
- 请注意,TensorMultiCategory输出是标签的编码。
e.检查是否能够按预期识别标签。
我们从word ab输出中看到,所有7个标签都被识别(加上我们前面提到的空格)。
使用“WHERE”函数将使我们能够定位索引,并潜在地将索引与词汇进行映射。
注意:如果我们没有将Split函数放在数据块中,那么单词将给我们单个字符,而不是单词。
我们现在对数据相当满意,可以继续下去了。
f.完成数据块。
拆分器、Item_tfms和Batch_tfms在上一篇博客中已经讨论过。previous blog
一旦我们对存储在DataSet中的数据感到满意,我们就可以转到DataLoaders并开始考虑模型。
7.可视化数据加载器的内容。
DataLoaders可以批量处理数据,我们将使用默认值(1)。
8.开始学习!
我们雇佣了美国有线电视新闻网的“学习者”。CNN Learner
因为我们有多个可能的标签,所以我们希望每个图像的每个标签都有一个二进制(0或1)预测。Accuracy_MULTI度量在S型分布中使用阈值默认值0.5。如果项目的预测概率阈值至少为0.5,则为其分配标签。否则就是零。
“Partial”是一个Python函数,它允许在不同项之间分发方法。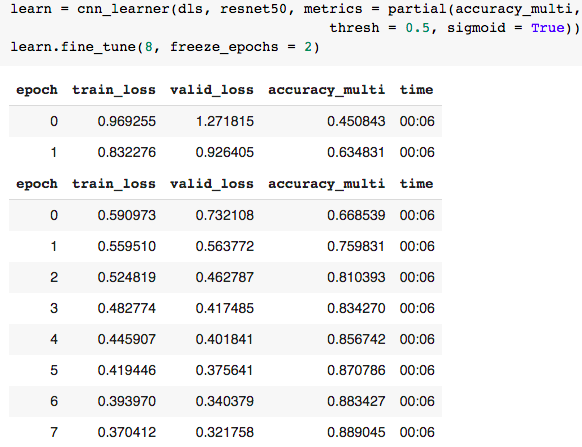
9.比较各种学习模型和超参数。
我们使用各种方法来查看各个组件的效果。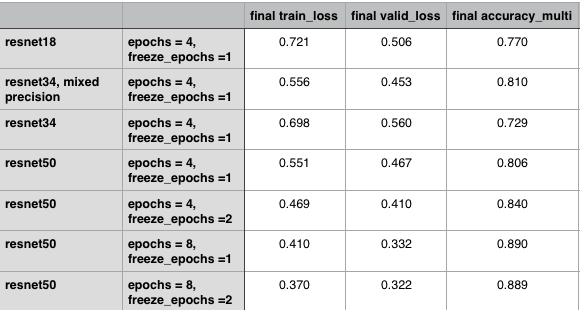
从上面的汇总表中,我们看到增加从resnet18到resnet34的深度并没有产生一个好的模型。然而,更深入的再网50可以提供更好的损失和准确性。
当分辨率为50时,中间层冻结的历元数越多,效果越好。将历元从4个增加到8个,表现出更大的改善。
选择resnet50给了我们81-89%的准确率。
10.将结果可视化。
该函数不显示哪些是实际标签和预测标签。检查文档中的代码将给我们一个线索,即顶部标签是实际的标签。docs
虽然红色标签看起来令人担忧,但它并不表明是一款糟糕的车型。Accuracy_MULTI考虑每个对象的预测,而不是每个图像的预测。同样,它惩罚预测不足和预测过高的精确点。关于这一点的进一步解释可以在处理精度_MULTI度量中阅读。Tackling the accuracy_multi metric
考虑到困难的水下图像环境,正确地标记5个对象中的4个是相当不错的!
11.评估可能的模型改进。
这反映了通过删除空白条目/空格进一步清除df.Animals列的文本可能会产生更准确的模型。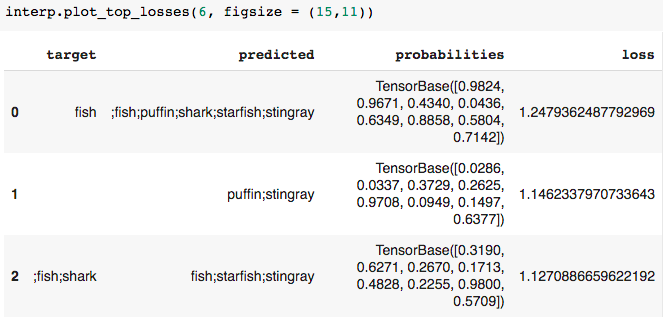

根据顶部损失的结果,该模型似乎在预测黄貂鱼和海星方面是慷慨的。回顾一下每个对象及其注释的分布可能会显示出一些不平衡。
无目标标签表示不足。
这些问题可以通过平衡对象之间的分布(包括无对象)来解决。
摘要:
我们能够使用中的外部数据作为预先训练的深度学习模型的输入。我们能够讨论模型所需的输入和说明。我们比较了不同的模型深度和超参数。我们还制作了一个模型,可以准确地标记出具有挑战性的水族馆图像中的多个物体。
确认:
感谢Fast.ai的创始人创造了一个精彩的学习平台。
感谢Fast.ai、StackOverflow和SharpestMinds论坛中帮助初学者的贡献者。
向便利信息传播和获取的媒介转变。
至@ai_fast_Track以获得导师资格。
:)
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/31/%e5%bc%80%e5%a7%8b%e6%b7%b1%e5%85%a5%e5%ad%a6%e4%b9%a0/
