
基于word2vec训练词向量(一)
1.回顾DNN训练词向量
上次说到了通过DNN模型训练词获得词向量,这次来讲解下如何用word2vec训练词获取词向量。
回顾下之前所说的DNN训练词向量的模型:
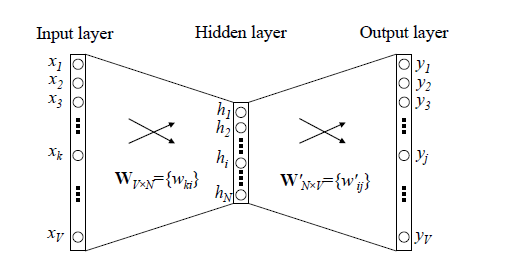
DNN模型中我们使用CBOW或者Skip-gram模式结合随机梯度下降,这样每次都只是取训练样本中几个词训练,每完成一次训练就反向传播更新一下神经网络中W和W’。
我们发现其中DNN模型仍存在两个缺点:
首先,每次我们只是使用了几个单词进行训练,但是在计算梯度的过程却要对整个参数矩阵进行运算,这样计算效率低下。
更重要的一个缺点是在输出层中用softmax时,需要对输出层中每个位置求其概率,sotfmax函数如下图:
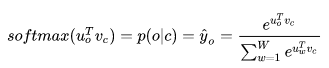
这里u_0是W’的一个神经元的参数向量,v_c对应的是训练样本与隐藏层参数W相乘激活后得到的向量。可以发现,为了得到输出层的每个位置的概率,我们需要求得所有单词的得分,如果一个词汇表很庞大的话,这是很耗资源的。
2.Word2vec
2.1 前瞻
针对DNN模型训练词向量的缺点,2013年,Google开源了一款用于词向量计算的工具–word2vec,引起了工业界和学术界的关注。Word2vec采用了Hierarchical Softmax或Negative Sampling两种技术来提高训练词向量性能,由于篇幅较长,本次只讲解基于Hierarcical Softmax优化的CBOW模型。
2.2 霍夫曼树
在介绍word2vec的网络结构之前这里需要简短的回顾下霍夫曼树,输入不同的权值的w节点,将其看作是n棵森林,先选取这些节点中最小两个权值w_i,w_j节点进行合并,得到一棵新的树,原来的w_i,w_j成为这个新树的左右子树。新树的权值是w_i和w_j节点对应的权值之和,将新树作为新加入的一棵树,删除原来的w_i,w_j树,重新选取两棵最小的树合并,以此类推直到所有的树都合并了。举个例子,假如有(a,b,c,d,e,f)共6个点,节点权值分布是(16,4,8,6,20,3)。规定左分支为0,右分支为1。
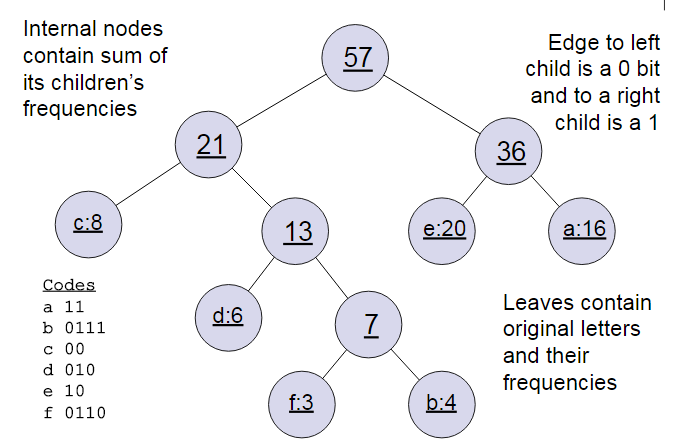
其中所有的词都是叶子结点,霍夫曼树的好处就是权值较大的词(即频率较大的词)会在深度更小的叶子处,获得更短的编码。这样频率更高的词会以更小的代价被发现。
2.3 Hierarcical Softmax网络结构
Word2vec有两种优化加速模型,一种是基于Hierarcical Softmax优化,另一种是基于Negative Sampling优化,本次只讲解基于Hierarcical Softmax优化。下图是Word2vec基于Hierarcical Softmax优化的模型,训练模式选用CBOW模型:
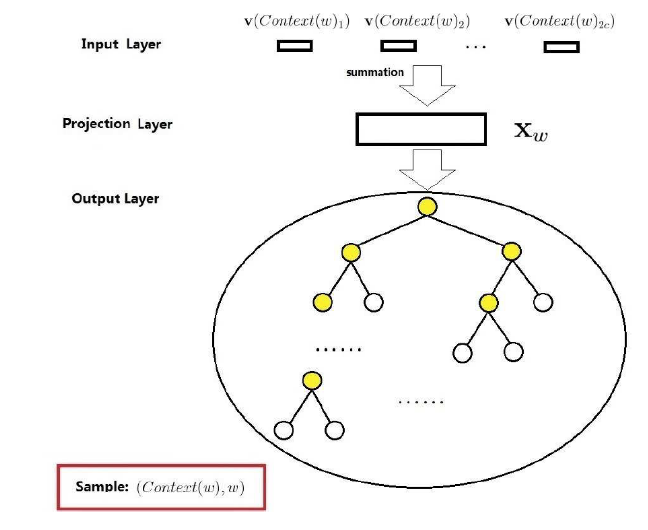
该网络结构包含了三层,输入层,投影层(即原来的隐藏层)和输出层,假设存在样本(Context(w),w),Context(w)是由w前后各c个词构成作输入样本train_X,w作输出值train_y。
- 输入层:
包含Context(w)中2c个词向量v(Context(w)_1),v(Context(w)_2),……,v(Context(w)_2c)组成,词向量长度相同。
- 投影层:
将输入层2c个词向量累加后求平均作为X_w。
- 输出层:
输出层是对应一棵霍夫曼树,其中叶子节点就是对应词汇表中的词,非叶子节点即(黄色节点)等价于原来DNN模型中隐藏层到输出层的参数W’,用θ_i表示该节点的权重,是一个向量,根节点是投影层的输出X_w。
2.4 基于Hierarcical Softmax优化的Word2vec优点:
Word2vec相比较于DNN训练词向量,其网络结构有两点很大的不同:
- 舍去了隐藏层,在CBOW模型从输入层到隐藏层的计算改为直接从输入层将几个词的词向量求和平均作为输出。
- 舍去了隐藏层到输出层的全连接结构,换成了霍夫曼树来代替隐藏层到输出层的映射。
第一个改进在于去除了隐藏层,Word2vec训练词向量的网络结构严格上来说不算是神经网络的结构,因为其整个网络结构是线性的,没有激活函数并且取消了隐藏层。这么做对于训练词向量反而是极好的,我们在神经网络中使用激活函数,是因为我们处理的问题很多不是线性相关的,输入的样本之间一般也不是线性相关的。但处理词的问题时,我们知道一个词与其上下文是相关的,也就是说输入的上下文几个词也应该是线性相关的。取消了隐藏层没有了激活函数也就意味着承认了输入的几个上下文词的关系也是呈线性相关的。Google的Tomas Mkolov就发现了如果将DNN模型中的隐藏层移除,训练出来的词向量就会成大量线性相关,于是就有了我们在上一篇开头所说的神奇的地方:
第二个改变是为了针对降低原来DNN的softmax的计算量,我们把softmax计算改成了沿着一棵霍夫曼树找叶子节点的计算,这里霍夫曼树德非叶子节点相当与DNN中隐藏层到输出层的权重,在霍夫曼树中不需要计算所有的非叶子结点,只需要计算找寻某个叶子结点时经过的路径上存在的节点,极大的减少了计算量。
2.5 Hierarcical Softmax优化原理
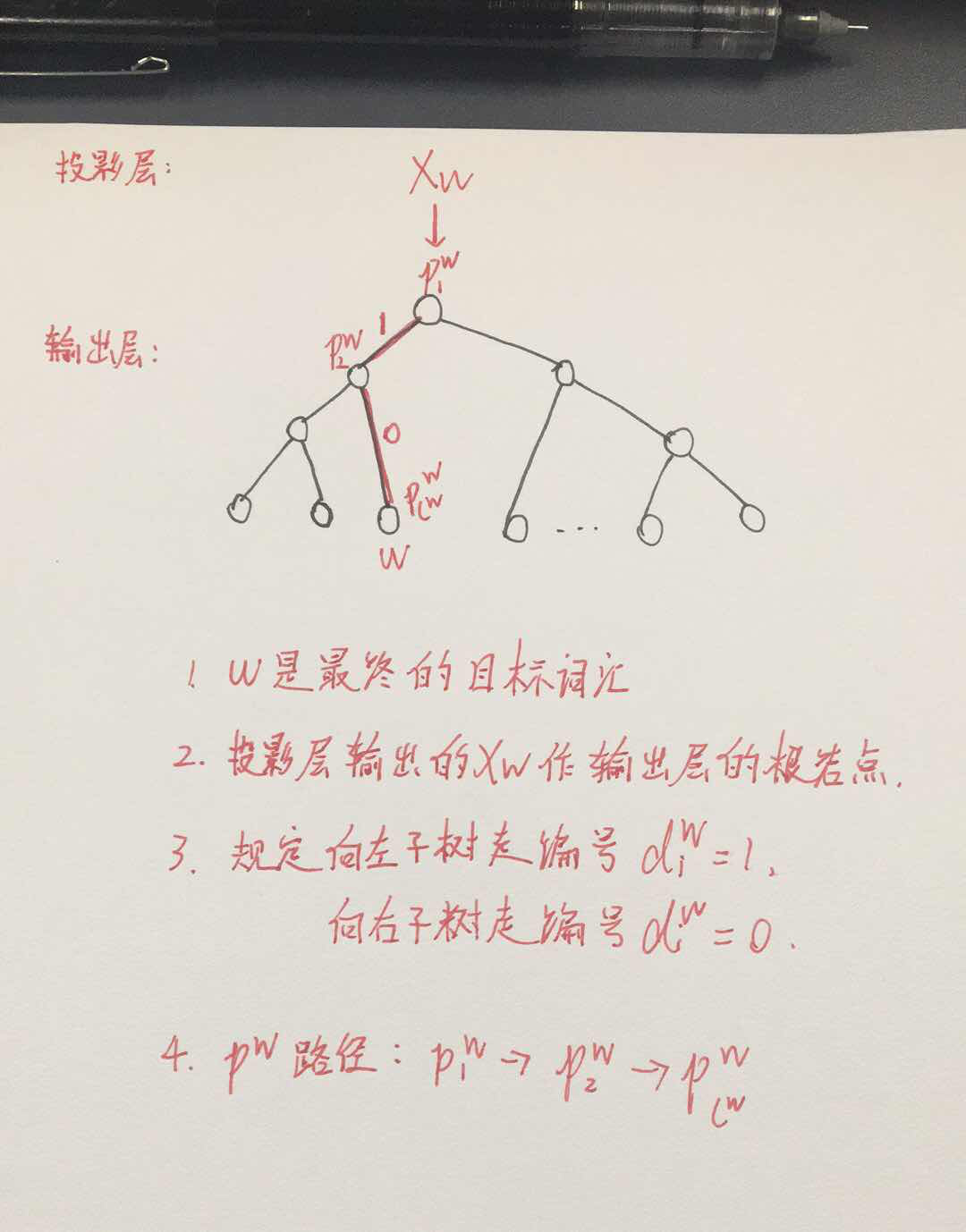
上图是一个根据词频构建好的霍夫曼树,各叶子节点代表词汇表中的所有词,在计算之前引入一些符号:
假设w使我们要求的目标词,Context(w)是该目标词的上下文词组,一共有c个,x_w是投影层的输出。

在word2vec中使用了二元逻辑回归的方法,这时候从根节点到叶子节点的过程是一个二分类问题,规定当前节点走到下一个节点,沿着左右子树走的概率分别为:
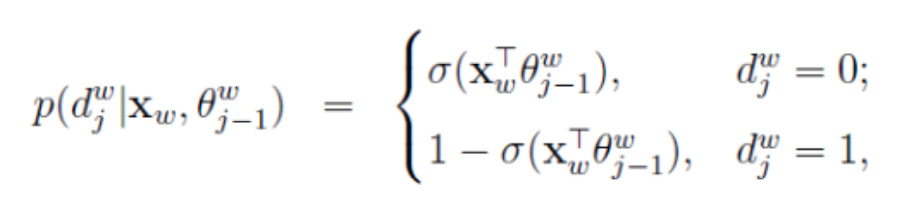 …(1)
…(1)
使用了sigmoid函数来计算选取当前节点的概率,因为只存在0,1两种取值,我们可以用指数形式写在一起:
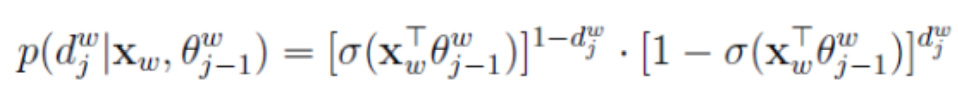 …(2)
…(2)
因为计算每一个非叶子是相互独立的,所以在从根节点到找到叶子节点对应的词w的概率可以写成,就是我们的目标函数,我们希望最大化这个目标函数:
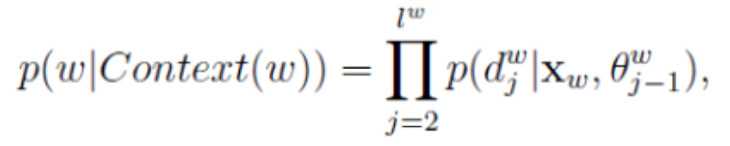 …(3)
…(3)
这里我们的目标函数可以去对数似然:
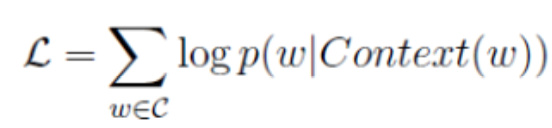
…(4)
将(2)带入(4),得:
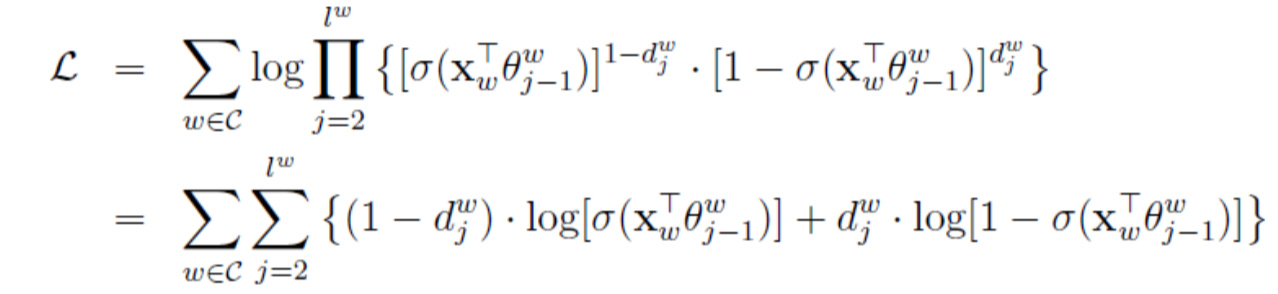 …(5)
…(5)
为了方便理解,将(5)改成c项之和:
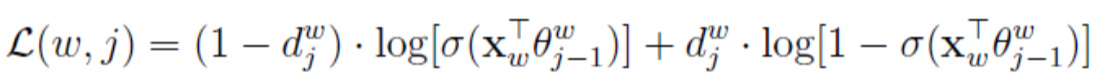
…(6)
我们的目标是最大化对数似然函数(5),等效成最大化每一项(6)即可。这时对(6)每个变量(X_w,θ_j-1)求偏导,对每一个样本,带入偏导数表达式得到在该函数上增长的梯度,然后让对应的参数加上这个梯度,函数就在偏导数对应的维度上增长了,这就是梯度上升法。


于是可以得到参数更新的伪代码,在训练开始前要把词汇表放入,统计每个词频构建好霍夫曼树,然后开始进行训练:

如果梯度收敛,则结束梯度迭代,算法结束。
3.总结
基于Hierarcical Softmax优化的Word2vec,相对于DNN,使用霍夫曼树网络结构不需要计算所有非叶子节点,每次只会反向对路径上的参数求偏导更新路径上的节点参数,提高了词向量训练效率。但是仍存在一些问题,比如霍夫曼树的结构是基于贪心的思想,这样训练频率很大的词很有效,但是对词频很低的词很不友好,路径很深。在基于Negative Sampling 的word2vec可以很高效率对词频很低的词训练,下次会继续讲解最后一篇基于Negative Sampling 的word2vec,学习路漫漫,和大家一起分享学得的东西,自己对于word2vec的一些拙见,如有不足或理解错误的地方,望各位指点!
原创文章,作者:晨, 汪,如若转载,请注明出处:https://panchuang.net/2018/04/11/word2vec/
