
使用Keras进行深度学习:(五)RNN和双向RNN讲解及实践
本文是全系列中第5 / 9篇:Keras 从入门到精通
Ray
介绍
通过对前面文章的学习,对深度神经网络(DNN)和卷积神经网络(CNN)有了一定的了解,也感受到了这些神经网络在各方面的应用都有不错的效果。然而这些网络都有一个共同的特点:每一层的神经元之间是相互独立的,如输入层的神经元彼此之间是独立的。然而,现实世界中很多元素之间都是有相互联系的。比如一部连续剧的内容,上一集和这一集的内容会有一定的联系;同样的,一句话,如“天空很蓝”,我们通过“天空”和“很”会认为接下来的词为“蓝”的概率会较高。正如这种时序数据问题,使用之前所学的模型(除了text-CNN)可能很难做到准确的推断,因此我们引入今天所讲的循环神经网络(recurrent neural network),其主要的用处就是处理和预测序列数据。
目录
- RNN网络结构及原理讲解
- 双向RNN网络结构及原理讲解
- 深层RNN网络结构
- Keras对RNN的支持
- 使用Keras RNN、BRNN、DBRNN模型进行实践
一、RNN网络结构及原理讲解
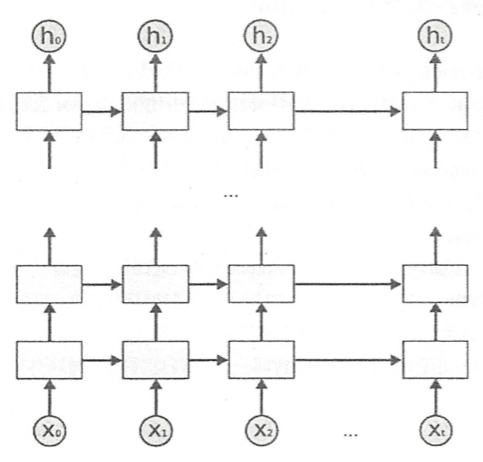
RNN的网络结构如下图:
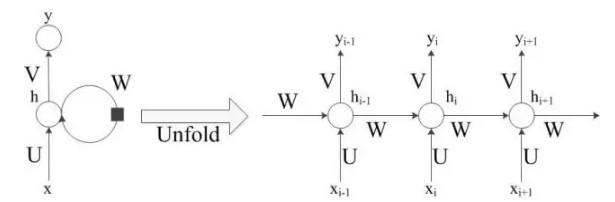
图中左侧是未展开RNN模型,在模型中间有个大圆圈表示循环,正是这个循环允许信息的持久化。但这个看起来可能不太好理解,因此将其展开为右侧的模型,并做进一步详细介绍如何实现信息的持久化。
右图中圆圈可以看作一个单元。定义Xi为第i时刻的输入,hi为第i时刻的记忆,yi为第i时刻的输出。
举个例子说明RNN实现过程:假设有一个句子的输入是”今天天空很”,要预测下个词是什么。通过分词后可能得到三个词作为输入:“今天”,“天空”,“很”,对应的就是上图的Xi-1,Xi,Xi+1,那么输出yi-1应该是“天空”,yi应该是“很”,预测下个词yi+1是什么,根据这句话,“蓝”的概率比较大。因此预测下个词应该是“蓝”。
通过上述浅显易懂的例子读者应该对RNN实现过程有个大概的了解,接下来将具体讲解RNN实现的详细过程。
输入层到隐藏层:
从上图的箭头指示,读者或许发现第i时刻的输出是由上一时刻的记忆和当前时刻共同决定的。这个思想很符合对时序数据处理的思路。正如我们在看连续剧的时候如果直接看中间某一集,可能会对部分剧情不能理解,但是,当我们看过前几集后会对剧情有所记忆,再加上该集剧情内容,我们就能更好的理解接下来剧情内容。因此用公式表示RNN当前时刻的记忆为:
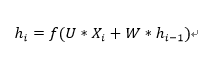
其中f()函数为激活函数。在此处要加上激活函数也很好理解,因为得到的信息并不是所有的都是重要的信息,而我们只需要记住重要的信息即可。这个时候就可以使用激活函数,如tanh,去对一些不重要的信息进行过滤,保留重要的信息即可。
隐藏层到输出层:
同样使用电视剧的例子进行通俗解释,当我们对上几集和该集的剧情进行整理,留下一些重要信息之后,我们会试图去猜测下一集的内容大概会是怎么样的。同样的,RNN的思路也如此。当我们hi中保留了i时刻的重要信息后,就试图使用这些重要信息进行预测下一个词应该是什么。用公式表示RNN当前时刻的输出为:
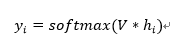
使用softmax函数是RNN希望预测每个词出现的概率,然后概率最高的词就是预测的下一个词。
注:U、W、V分别是对应的权重矩阵,通过反向传播算法调整相应的值使得预测的结果更加准确。与CNN一样,网络中的每个单元都共享同一组(U、V、W),可以极大的降低了计算量。
具体的前向传播计算过程如下:
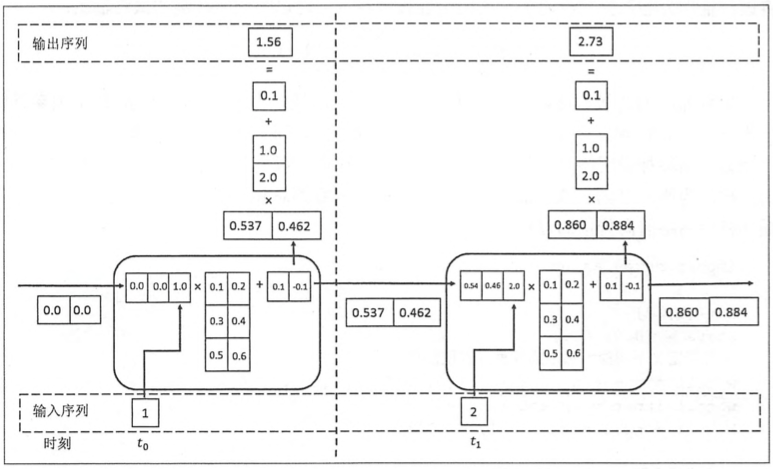
在t1时刻的输入为2,结合上一时刻的记忆(0.537,0.462),得到(0.54,0.46,2.0),然后与隐藏层的权重矩阵相乘得到该时刻的记忆(0.860,0.884)。通过该时刻的记忆与输出层的权重矩阵相乘得到该时刻的预测值2.73。这就是一个时刻RNN前向传播的具体过程。
因此,通过上述思想,RNN就能有效的处理时序数据,对每个输入保留一些重要的信息,理论上最后就能得到整个输入的所有重要信息,进而综合考虑所有输入去预测输出。
二、双向RNN(BRNN)网络结构及原理讲解
在RNN中只考虑了预测词前面的词,即只考虑了上下文中“上文”,并没有考虑该词后面的内容。这可能会错过了一些重要的信息,使得预测的内容不够准确。正如电视剧的例子,当在该集新出现了一个人物,若要预测该人物的名字,单从前几集的内容,并不能有效的进行预测。但如果我们看了后几集的内容,可能就能更加有效的进行预测。双向RNN也是基于这种思想,不仅从前往后(如下图黄色实箭头)保留该词前面的词的重要信息,而且从后往前(如下图黄色虚箭头)去保留该词后面的词的重要信息,然后基于这些重要信息进行预测该词。双向RNN模型如下:
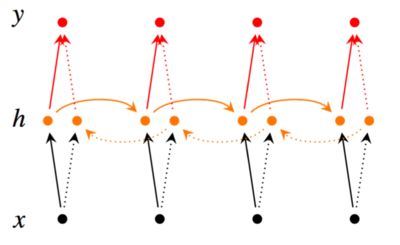
用公式表示双向RNN过程如下:

另外,双向RNN需要保存两个方向的权重矩阵,所以需要的内存约为RNN的两倍。
三、深层RNN(DRNN)网络结构
深层RNN网络是在RNN模型多了几个隐藏层,是因为考虑到当信息量太大的
时候一次性保存不下所有重要信息,通过多个隐藏层可以保存更多的重要信息,正如我们看电视剧的时候也可能重复看同一集记住更多关键剧情。同样的,我们也可以在双向RNN模型基础上加多几层隐藏层得到深层双向RNN模型。
注:每一层循环体中参数是共享的,但是不同层之间的权重矩阵是不同的。
四、Keras对RNN的支持
在Keras同样对RNN模型进行了封装,并且调用起来十分方便,我们将会在下一节搭建RNN模型来呈现使用Keras搭建是多么方便。
Keras在layers包的recurrent模块中实现了RNN相关层模型的支持,并在wrapper模型中实现双向RNN包装器。
recurrent模块中的RNN模型包括RNN、LSTM、GRU等模型(后两个模型将在后面Keras系列文章讲解):
1.RNN:全连接RNN模型
SimpleRNN(units,activation=’tanh’,dropout=0.0,recurrent_dropout=0.0, return_sequences=False)
2.LSTM:长短记忆模型
LSTM(units,activation=’tanh’,dropout=0.0,recurrent_dropout=0.0,return_sequences=False)
3.GRU:门限循环单元
GRU(units,activation=’tanh’,dropout=0.0,recurrent_dropout=0.0,return_sequences=False)
4.参数说明:
units: RNN输出的维度
activation: 激活函数,默认为tanh
dropout: 0~1之间的浮点数,控制输入线性变换的神经元失活的比例
recurrent_dropout:0~1之间的浮点数,控制循环状态的线性变换的神经元失活比例
return_sequences: True返回整个序列,用于stack两个层,False返回输出序列的最后一个输出,若模型为深层模型时设为True
input_dim: 当使用该层为模型首层时,应指定该值
input_length: 当输入序列的长度固定时,该参数为输入序列的长度。当需要在该层后连接Flatten层,然后又要连接Dense层时,需要指定该参数
wrapper模块实现双向RNN模型:
- 双向RNN包装器
Bidirectional(layer, merge_mode=’concat’, weights=None)
参数说明:
layer: SimpleRNN、LSTM、GRU等模型结构,确定是哪种RNN的双向模型
Merge_mode: 前向和后向RNN输出的结合方式,为sum,mul,concat,ave和None之一,若为None,则不结合,以列表形式返回,若是上文说到的拼接则为concat
五、使用Keras RNN、BRNN模型、DBRNN模型进行实践
本次实践同样使用上一篇文章中使用到的Imdb数据集进行情感分析。对于该数据集的预处理在本篇文章中就不再介绍,若想了解可阅读上一篇文章。
Keras在实现循环神经网络很方便,已经将其封装好,只需要调用相应的层就可以搭建该模型,接下来简单的搭建上述三种模型。
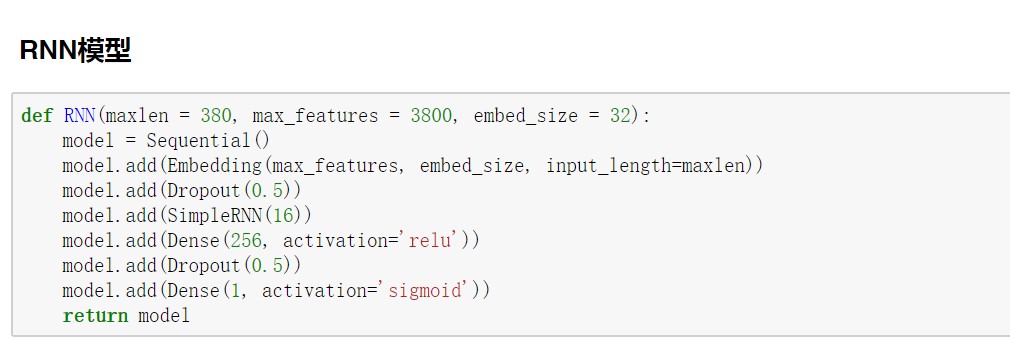
搭建一层的RNN模型,只需要在模型中加入SImpleRNN层,并设置该层的输出即可,其他模型的搭建都和上篇文章中讲解的一样,相当方便。

BRNN模型需要使用wrappers包的Bidirecitional模块实现双向RNN模型,并且要将return_sequences参数设置为True,因为如上文所述需要将前、后向的重要信息拼接起来,所以需要将整个序列返回,而不是只返回最后一个预测词。
并且上文提到的是将前后向的进行拼接,所以使用的是’concat’,也可以使用sum对前后向结果求和或者其他对结果进行相应的操作。
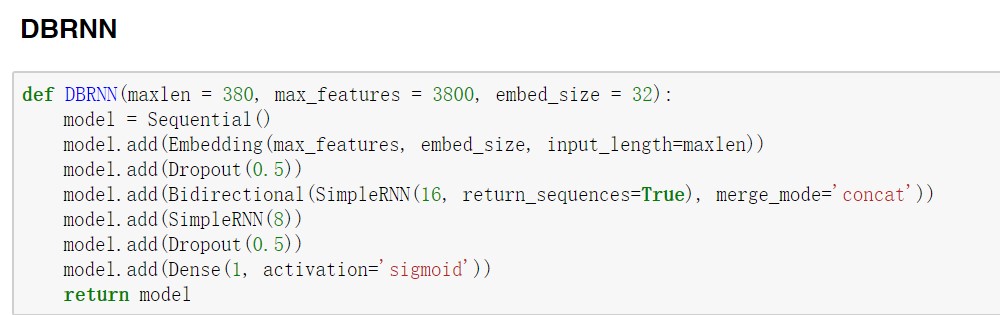
DBRNN模型的搭建也很方便,比如在这里我们要搭建一个两层的DBRNN模型,只需要再加一层SimpleRNN即可。要注意的是,如果要搭建多层DBRNN模型,除了最后一层SimpleRNN外,其他的SimpleRNN层都需要将return_sequences参数设置为True。
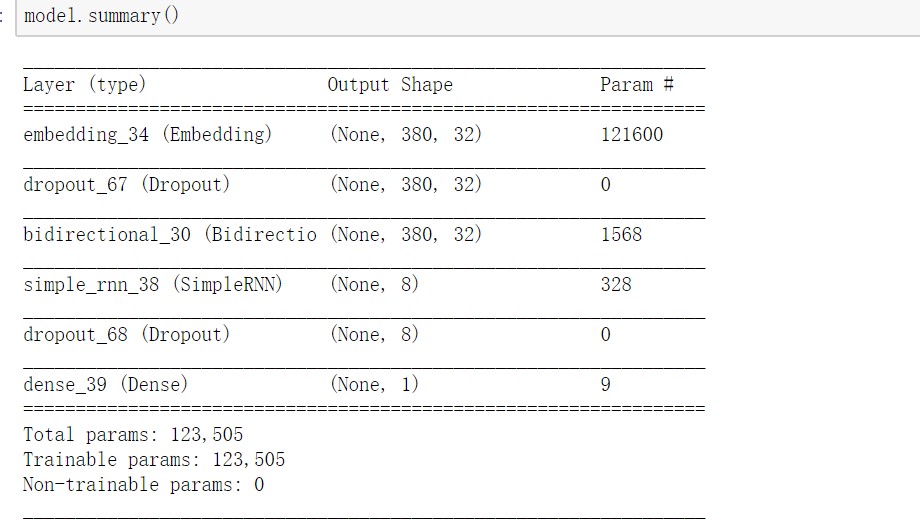
可能读者会认为虽然Keras搭建模型很方便,但是这会导致新手对于模型的输入输出欠缺理解。同样的,Keras也考虑到了这一点,因此Keras中有model.summary()的内置函数,通过这个函数就可以知道我们搭建的模型的输入输出和参数等信息,便于我们理解模型和debug。下图给出上图搭建的DBRNN的summary。
模型的损失函数,优化器和评价指标如下:

在训练模型之前,介绍Keras中一种优化模型效果且可以加快模型学习速度的方法:EarlyStopping。
EarlyStopping介绍
EarlyStopping是Callbacks的一种,callbacks用于指定在每个epoch开始和结束的时候进行哪种特定操作,即用于提前停止训练的callbacks。之所以要提前停止训练,是因为继续训练会导致测试集上的准确率下降。那继续训练导致测试准确率下降的原因笔者猜测可能是1. 过拟合 2. 学习率过大导致不收敛 3. 使用正则项的时候,Loss的减少可能不是因为准确率增加导致的,而是因为权重大小的降低。
EarlyStopping的使用
一般是在model.fit函数中调用callbacks,fit函数中有一个参数为callbacks。注意这里需要输入的是list类型的数据,所以通常情况只用EarlyStopping的话也要是[EarlyStopping()]
keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=0, verbose=0, mode=’auto’)
参数说明:
monitor:需要监视的量,如’val_loss’, ‘val_acc’, ‘acc’, ‘loss’。
patience:能够容忍多少个epoch内都没有improvement。
verbose:信息展示模式
mode:‘auto’,‘min’,‘max’之一,在min模式下,如果检测值停止下降则中止训练。在max模式下,当检测值不再上升则停止训练。例如,当监测值为val_acc时,模式应为max,当检测值为val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动推断。


可以看到在第13次训练完成后,验证集的准确率下降后就停止了继续训练,这样可以既可以加快训练模型速度,也可以使得在验证集的准确率不再下降。
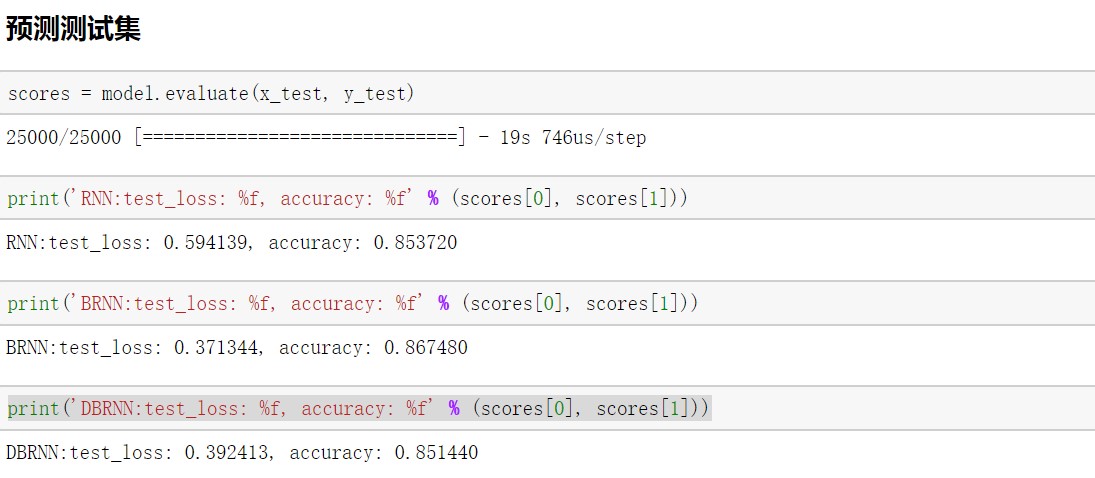
最后我们使用三种训练好的模型进行预测测试集,得到在RNN和DBRNN上模型的准确率在0.85左右,在BRNN模型在0.87左右。读者可以通过调参进一步提高模型的准确率。
完整代码下载:
https://github.com/hongweijun811/wjgit
至此,我们应该对RNN模型以及Keras实现RNN模型有了一定的了解。下一篇文章我们将会对RNN模型的改进模型LSTM模型进行详细讲解。欢迎持续关注我们的Keras系列文章!
原创文章,作者:Ray,如若转载,请注明出处:https://panchuang.net/2018/04/26/keras_5/
