
十大预训练模型,助力入门深度学习(第1部分 – 计算机视觉)
作者 | Joey
编辑 | 安可
出品 | 磐创AI技术团队
【磐创AI导读】:本文主要为深度学习入门者介绍了十大预训练模型。想要学习更多的机器学习、深度学习知识,欢迎大家点击上方蓝字关注我们的公众号:磐创AI。
介绍
对于希望运用某个现有框架来解决自己的任务的人来说,预训练模型可以帮你快速实现这一点。通常来说,由于时间限制或硬件水平限制大家往往并不会从头开始构建并训练模型,这也就是预训练模型存在的意义。大家可以使用预训练模型作为基准来改进现有模型,或者针对它测试自己的模型:

图片来源:Facebook AI
在本文中,将向大家介绍Keras中多种可应用在计算机视觉领域的预训练模型。这里选择Keras的原因,一是因为它易上手,对于刚开始使用神经网络的人来说是一个很好的选择;二是希望在本系列文章中统一使用一个框架,也帮大家省去很多麻烦,只需关注模型的具体使用即可。大家可以通过多次调整模型参数的形式对本文介绍的模型进行实践,这样将更有助于理解。
本主题将包含一系列文章,本文为本系列的第一部分,第二部分将侧重于自然语言处理(NLP),第三部分将关注语音处理模型。希望通过这些可以帮助到大家,让大家迅速上手那些现有的模型。
目录
- 目标检测
- Mask R-CNN
- YOLOv2
- MobileNet
- 成熟/未成熟的番茄分类
- 汽车分类
- 面部识别和再生
- VGG-Face模型
- 单幅图像的三维人脸重建
- 分割
- 语义图像分割 – Deeplabv3
- 机器手术分割(Robot Surgery Segmentation)
- 其他
- 图像描述(Image Captioning)
目标检测是计算机视觉领域中最常见的应用之一。它适用于各行各业,从自动驾驶汽车到计算人群中的人数。本节介绍可用于目标检测的预训练模型。
MaskR-CNN
(https://github.com/matterport/Mask_RCNN)

MaskR-CNN是为目标实例分割而开发的灵活框架。这个github提供的预训练模型是Mask R-CNN适配的Keras版本。它为给定图像中的对象的每个实例生成边界框和分割掩模(如上所示)。
这个GitHub存储库提供了大量的资源来帮助入门。它包括Mask R-CNN的源代码,用于MS COCO的训练代码和预训练权重,用于可视化检测pipline的每个步骤的Jupyter notebook等。
YOLOv2
(https://github.com/experiencor/keras-yolo2)

YOLO是一种应用深度学习技术的超流行目标检测框架。此存储库包含YOLOv2在Keras上的实现。同时开发人员已经在多种目标图像(如袋鼠检测,自动驾驶汽车,红细胞检测等)上应用了这个框架,而且他们已经发布了用于浣熊检测的预训练模型。
大家可以在此处(https://github.com/experiencor/raccoon_dataset)下载浣熊数据集,立即开始使用此预训练模型!该数据集由200个图像组成(160个训练,40个验证)。整个模型预训练的权重在这里下载(https://1drv.ms/f/s!ApLdDEW3ut5feoZAEUwmSMYdPlY)。根据开发人员的说法,这些权重可以适用于所有单类别的目标检测器。
MobileNet
(https://keras.io/applications/#mobilenet)
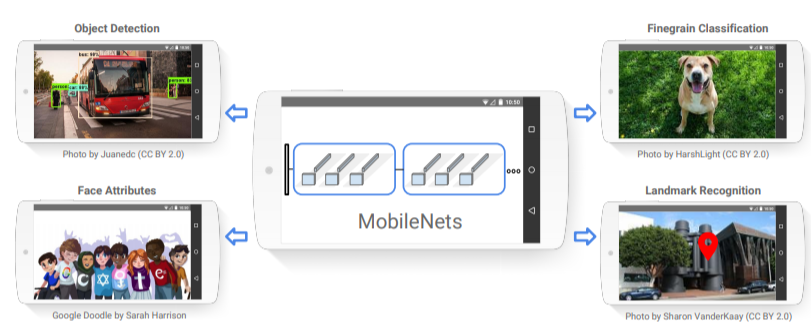
顾名思义,MobileNet是一种专为移动设备设计的架构,它是由谷歌建立的。我们在上面链接的这个特殊模型在流行的ImageNet数据库上提供了预训练权重(它是一个包含数百万张属于20,000多类的图像数据库)。
正如你所见,MobileNet的应用不仅限于目标检测,还涵盖各种计算机视觉任务,如面部属性、地标(landmark)识别、细粒度分类等。
成熟/未成熟的番茄分类
(https://github.com/fyrestorm-sdb/tomatoes)

如果给你几百张西红柿的图片,你会如何对它们进行分类?是有缺陷/无缺陷,或成熟/未成熟?从深度学习的角度考虑,这个问题的首选技术是基于深度学习的图像处理。在这个分类问题中,我们可以使用预训练的Keras VGG16模型来识别给定图像中的番茄是成熟的还是未成熟。
该模型在来自ImageNet数据集的390张成熟和未成熟的番茄图像进行了训练,并在18种不同的番茄验证图像上进行了测试。 这些验证图像的总体结果如下:
| 查全率 | 0.8888889 |
| 查准率 | 0.9411765 |
| F1得分 | 0.9142857 |
汽车分类
(https://github.com/michalgdak/car-recognition)

有许多方法可以对车辆进行分类,如通过它的车身风格,车门数量,开放式或封闭式车顶,座椅数量等等。在这个特殊问题中,我们必须将车辆图像分类为不同的类别。这些类包括品牌,型号,年份,例如2012款特斯拉Model S等等。为了开发这个模型,使用了斯坦福的汽车数据集(http://ai.stanford.edu/~jkrause/cars/car_dataset.html),其中包含19618类汽车的16185张图像。
使用预训练的VGG16,VGG19和InceptionV3模型训练模型。VGG网络的特点在于其结构简单,仅使用3×3卷积层堆叠起来以增加深度。16和19代表网络中的weight layers。
由于数据集很小,最简单的模型,即VGG16,是最准确的。使用交叉验证法训练VGG16网络的准确率达到66.11%。由于偏差/方差问题,像InceptionV3这样的更复杂的模型可能并不会太准确。
面部识别和再生(Facial Recognition and Regeneration)在深度学习社区中风靡一时。越来越多的技术和模型在以惊人的速度发展,以实现面部识别。它的应用涵盖了多个方面,如手机解锁,人群检测,面部表情分析等。
另一方面,面部再生是从面部的特写图像生成3D面部建模。仅仅从二维信息创建3D结构化对象是业界另一个需要思考的问题。面部再生的应用在电影和游戏行业中是巨大的。各种CGI模型的自动化,可以节省大量的时间和金钱。
本文的这一部分涉及这两个领域的预训练模型。
VGG-Face模型(https://gist.github.com/EncodeTS/6bbe8cb8bebad7a672f0d872561782d9)

从头开始创建面部识别模型是一项艰巨的任务。你需要寻找、收集,然后注释大量的图像才有希望建立一个像样的模型。因此,在该领域中使用预训练模型非常有意义。
VGG-Face(http://www.robots.ox.ac.uk/~vgg/data/vgg_face/)是一个包含2622个独特身份且规模超过两百万的数据集。这种预训练模型是通过以下方法设计的:
- vgg-face-keras:直接将vgg-face模型转换为keras模型
- vgg-face-keras-fc:首先将vgg-face Caffe模型转换为mxnet模型,然后将其转换为keras模型
单幅图像的三维人脸重建
(https://github.com/dezmoanded/vrn-torch-to-keras)

这是一个非常酷的深度学习技术应用。大家可以从上面的图像推断出该模型如何工作,以便将面部特征重建为三维空间。
这种预训练模型最初是使用Torch(https://github.com/AaronJackson/vrn)开发的,然后转换到了Keras。
语义图像分割 – Deeplabv3+
(https://github.com/bonlime/keras-deeplab-v3-plus)
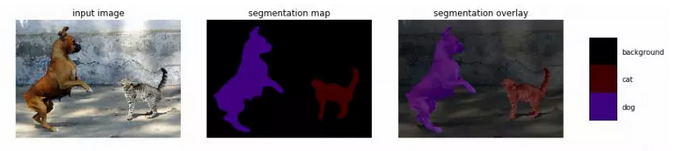
语义图像分割是将语义标签分配到图像中每个像素的任务。这些标签可以是“天空”,“汽车”,“道路”,“长颈鹿”等。这项技术的作用是要找到物体的轮廓,从而也限制了精度要求(这就是它与图像分类的根本区别,具有更宽松的准确度要求)。
Deeplabv3是谷歌最新的语义图像分割模型。它最初是使用TensorFlow创建的,现在已经可以使用Keras实现。这个GitHub存储库还包含如何获取标签的代码,以及如何使用这个带有自定义类的预训练模型。当然也有如何训练自己的模型的指引。
机器人手术分割(Robot Surgery Segmentation)
(https://github.com/ternaus/robot-surgery-segmentation)
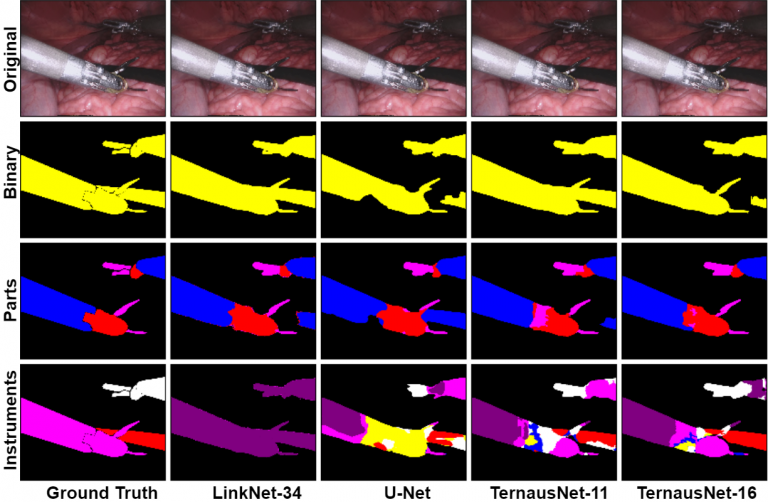
该模型试图解决机器人辅助手术场景中手术器械的图像分割问题。问题进一步分为两部分,如下:
- 二进制分割:图像中的每个像素都标记出是工具还是背景
- 多级分割:不同的工具或工具的不同部分与背景区分开来
这种预训练模型基于U-Net网络架构设计,并通过使用被称为LinkNet和TernausNet的最新语义分割神经网络进一步改进。该模型在8×225帧高分辨率立体相机图像序列上进行了训练。
图像描述
(https://github.com/boluoyu/ImageCaption)

还记得那些曾经玩过的根据图片生成文字的游戏么?那些就是基本的图像描述。它结合了NLP技术和Computer Vision技术来生成字幕。 这项任务长期以来一直是一项具有挑战性的任务,因为它需要具有无偏图像与场景的大型数据集。而且在满足上述所有约束后,还需要针对性的图像推理算法。
现在很多企业已经在使用这种技术了,那么我们怎样才能更方便的去研究这项技术呢?其实他的核心在于将给定的输入图像转换为简短且有意义的描述,而且编码器-解码器框架广泛用于解决这项核心任务。图像编码器正是卷积神经网络(CNN)。
这是在MS COCO数据集(http://cocodataset.org/#download)上训练的VGG 16预训练模型,其中解码器是预测给定图像的字幕的长短期记忆(LSTM)网络。
总结
深度学习是一个难以适应的棘手领域,它对硬件的算力有很高的要求,这也是会有这么多的预训练模型的原因。希望上面列出来的一些预训练模型可以帮到大家。
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2018/08/25/%e5%8d%81%e5%a4%a7%e9%a2%84%e8%ae%ad%e7%bb%83%e6%a8%a1%e5%9e%8b%ef%bc%8c%e5%8a%a9%e5%8a%9b%e5%85%a5%e9%97%a8%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%ef%bc%88%e7%ac%ac1%e9%83%a8%e5%88%86-%e8%ae%a1/
