
Python机器学习算法的7个损失函数的详细指南
Python机器学习算法的7个损失函数的详细指南
译者|VK
来源|Analytics Vidhya
概述
- 学习什么是损失函数以及它们如何在机器学习算法中工作
- 损失函数实际上是我们经常使用的技术的核心
- 本文介绍了多种损失函数与它们的工作原理以及如何使用Python对它们进行编程
介绍
想象一下-你已经在给定的数据集上训练了机器学习模型,并准备好将它交付给客户。但是,你如何确定该模型能够提供最佳结果?是否有指标或技术可以帮助你快速评估数据集上的模型?
当然是有的,简而言之,机器学习中损失函数可以解决以上问题。
损失函数是我们喜欢使用的机器学习算法的核心。但大多数初学者和爱好者不清楚如何以及在何处使用它们。
它们并不难理解,反而可以增强你对机器学习算法的理解。那么,什么是损失函数,你如何理解它们的意义?
在本文中,我将讨论机器学习中使用的7种常见损失函数,并解释每种函数的使用方法。
目录
- 什么是损失函数?
- 回归损失函数
- 平方误差损失
- 绝对误差损失
- Huber损失
- 二分类损失函数
- 二分类交叉熵
- Hinge损失
- 多分类损失函数
- 多分类交叉熵损失
- KL散度(Kullback Leibler Divergence Loss)
什么是损失函数?
假设你在山顶,需要下山。你如何决定走哪个方向?

我要做的事情如下:
- 环顾四周,看看所有可能的路径
- 拒绝那些上升的路径。这是因为这些路径实际上会消耗更多的体力并使下山任务变得更加艰难
- 最后,走我认为的坡度最大的路径
关于我判断我的决策是否好坏的直觉,这正是损失函数能够提供的功能。
损失函数将决策映射到其相关成本
决定走上坡的路径将耗费我们的体力和时间。决定走下坡的路径将使我们受益。因此,下坡的成本是更小的。
在有监督的机器学习算法中,我们希望在学习过程中最小化每个训练样例的误差。这是使用梯度下降等一些优化策略完成的。而这个误差来自损失函数。
损失函数(Loss Function)和成本函数(Cost Function)之间有什么区别?
在此强调这一点,尽管成本函数和损失函数是同义词并且可以互换使用,但它们是不同的。
损失函数用于单个训练样本。它有时也称为误差函数(error function)。另一方面,成本函数是整个训练数据集的平均损失(average function)。优化策略旨在最小化成本函数。
回归损失函数
此时你必须非常熟悉线性回归。它涉及对因变量Y和几个独立变量$X_i$之间的线性关系进行建模。因此,我们在空间中对这些数据拟合出一条直线或者超平面。
[code lang=text]
Y = a0 + a1 * X1 + a2 * X2 + ….+ an * Xn
[/code]
我们将使用给定的数据点来找到系数a0,a1,…,an。

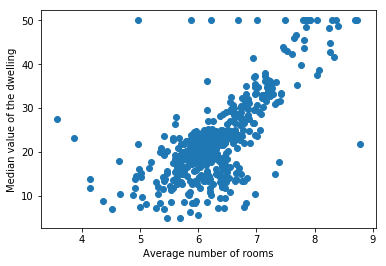
我们将使用著名的波士顿住房数据集1来理解这个概念。为了简单起见,我们将只使用一个特征-每个住宅的平均房间数(Average number of rooms per dwelling)(X)来预测因变量-1000美元价位的房屋的中位数价值(Median Value)(Y)。
我们将使用梯度下降(Gradient Descent)作为优化策略来查找回归线。我不会详细介绍Gradient Descent的细节,但这里提醒一下权重更新规则:
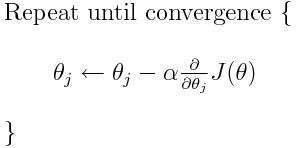
这里,$\theta_j$是要更新的权重,$\alpha$是学习率,$J$是成本函数。成本函数由$\theta$参数化。我们的目标是找到产生最小总成本的θ值。
我已经为下面的每个损失函数定义了我们将遵循的步骤:
- 写出预测函数f(X)的表达式,并确定我们需要找到的参数
- 确定每个训练样本计算得到的损失
- 找到成本函数(所有样本的平均损失)的表达式
- 找到与每个未知参数相关的成本函数的梯度
- 确定学习率并在固定次数中进行迭代执行权重更新规则
1.平方误差损失
每个训练样本的平方误差损失(也称为L2 Loss)是实际值和预测值之差的平方:
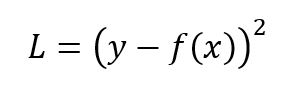
相应的成本函数是这些平方误差的平均值(MSE)。
在波士顿住房数据上,在不同的学习率中分别迭代了500次得到下图:

让我们再谈谈MSE损失函数,它是一个二次函数(形式为ax^2+bx+c),并且值大于等于0。二次函数的图形如下图所示:
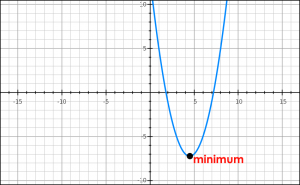
二次函数仅具有全局最小值。由于没有局部最小值,所以我们永远不会陷入它。因此,可以保证梯度下降将收敛到全局最小值(如果它完全收敛)。
MSE损失函数通过平方误差来惩罚模型犯的大错误。把一个比较大的数平方会使它变得更大。但有一点需要注意,这个属性使MSE成本函数对异常值的健壮性降低。因此,如果我们的数据容易出现许多的异常值,则不应使用这个它。
2.绝对误差损失
每个训练样本的绝对误差是预测值和实际值之间的距离,与符号无关。绝对误差也称为L1 Loss:
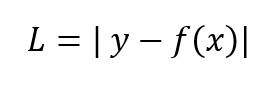
正如我之前提到的,成本是这些绝对误差的平均值(MAE)。
与MSE相比,MAE成本对异常值更加健壮。但是,在数学方程中处理绝对或模数运算符并不容易。我们可以认为这是MAE的缺点。
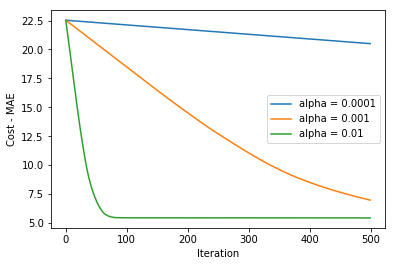
在不同学习速率中分别迭代500次后,我们得到以下图:
3.Huber损失
Huber损失结合了MSE和MAE的最佳特性。对于较小的误差,它是二次的,否则是线性的(对于其梯度也是如此)。Huber损失需要确定$\delta$参数:

我们以0.0001的学习速率分别对$\delta$参数的不同值进行500次权重更新迭代得到下图:
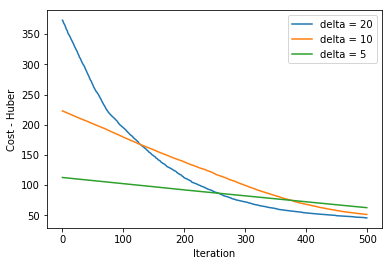
Huber损失对于异常值比MSE更强。它用于稳健回归(robust regression),M估计法(M-estimator)和可加模型(additive model)。Huber损失的变体也可以用于分类。
二分类损失函数
意义如其名。二分类是指将物品分配到两个类中的一个。该分类基于应用于输入特征向量的规则。二分类的例子例如,根据邮件的主题将电子邮件分类为垃圾邮件或非垃圾邮件。
我将在乳腺癌数据集2上说明这些二分类损失函数。
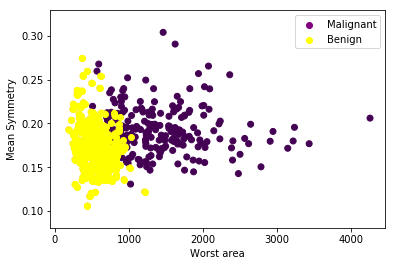
我们希望根据平均半径,面积,周长等特征将肿瘤分类为”恶性(Malignant)“或”良性(Benign)“。为简化起见,我们将仅使用两个输入特征(X_1和X_2),即”最差区域(worst area)“和”平均对称性(mean symmetry)“用于分类。Y是二值的,为0(恶性)或1(良性)。
这是我们数据的散点图:
1.二元交叉熵损失
让我们从理解术语”熵”开始。 通常,我们使用熵来表示无序或不确定性。测量具有概率分布p(X)的随机变量X:

负号用于使最后的结果为正数。
概率分布的熵值越大,表明分布的不确定性越大。同样,一个较小的值代表一个更确定的分布。
这使得二元交叉熵适合作为损失函数(你希望最小化其值)。我们对输出概率p的分类模型使用二元交叉熵损失。
[code lang=text]
元素属于第1类(或正类)的概率=p
元素属于第0类(或负类)的概率=1-p
[/code]
然后,输出标签y(可以取值0和1)的交叉熵损失和和预测概率p定义为:

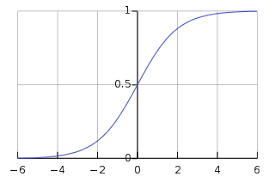
这也称为Log-Loss(对数损失)。为了计算概率p,我们可以使用sigmoid函数。这里,z是我们输入功能的函数:

sigmoid函数的范围是[0,1],这使得它适合于计算概率。
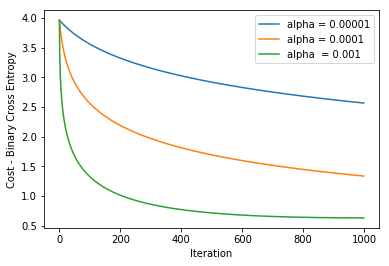
在不同alpha值里使用权重更新规则进行1000次迭代得到下图:
2.Hinge损失
Hinge损失主要用于带有类标签-1和1的支持向量机(SVM)。因此,请确保将数据集中”恶性”类的标签从0更改为-1。
Hinge损失不仅会惩罚错误的预测,还会惩罚不自信的正确预测。
数据对(x,y)的Hinge损失如图:
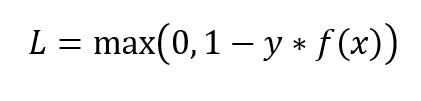
在使用三个不同的alpha值运行2000次迭代的更新函数之后,得到下图:
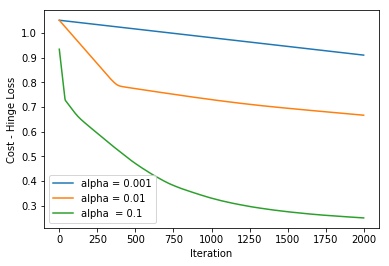
Hinge损失简化了SVM的数学运算,同时最大化了损失(与对数损失(Log-Loss)相比)。当我们想要做实时决策而不是高度关注准确性时,就可以使用它。
多分类损失函数
电子邮件不仅被归类为垃圾邮件或垃圾邮件(这不再是90年代了!)。它们分为各种其他类别-工作,家庭,社交,促销等。
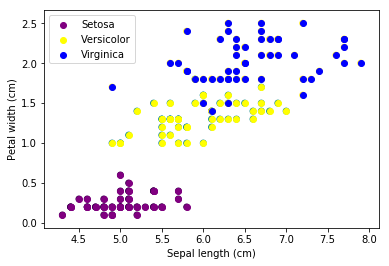
我们将使用Iris数据集3来理解剩余的两个损失函数。我们将使用2个特征$X_1$萼片长度(Sepal length)和特征$X_2$花瓣宽度(Petal width)来预测鸢尾花的类别(Y) –Setosa,Versicolor或Virginica
我们的任务是使用神经网络模型和Keras内置的Adam优化器来实现分类器。这是因为随着参数数量的增加,数学以及代码将变得难以理解。
这是我们数据的散点图:
1.多分类交叉熵损失
多分类交叉熵损失是二元交叉熵损失的推广。输入向量$X_i$和相应的one-hot编码目标向量$Y_i$的损失是:
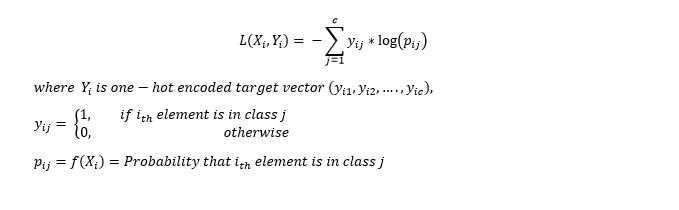
我们使用softmax函数来找到概率$p_{ij}$:
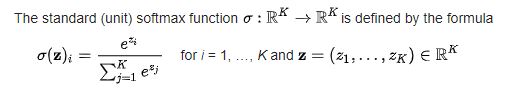
“Softmax层是接在神经网络的输出层前。Softmax层必须与输出层具有相同数量的节点。”Google Developer’s Blog
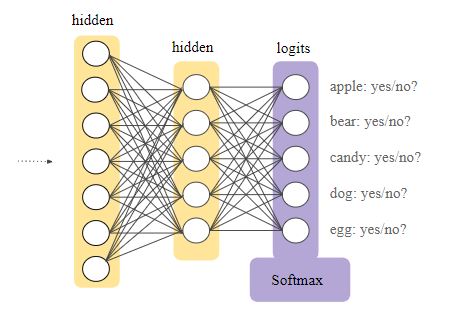
最后,我们的输出是具有给定输入的最大概率的类别。
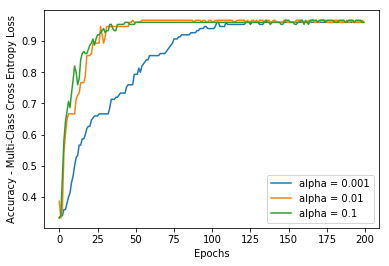
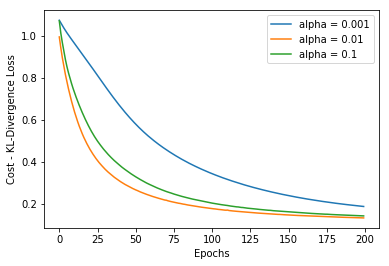
在不同的学习率经过200轮训练后成本和准确度的图如下:

2. KL散度
KL散度概率分布与另一个概率分布区别的度量。KL散度为零表示分布相同。

请注意,发散函数不对称。即:
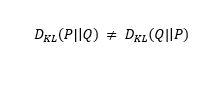
这就是为什么KL散度不能用作距离度量的原因。
我将描述使用KL散度作为损失函数而不进行数学计算的基本方法。在给定一些近似分布Q的情况下,我们希望近似关于输入特征的目标变量的真实概率分布P. 由于KL散度不对称,我们可以通过两种方式实现:
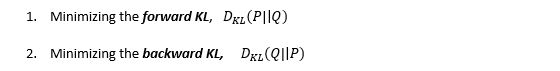
第一种方法用于监督学习,第二种方法用于强化学习。KL散度在功能上类似于多分类交叉熵,KL散度也可以称为P相对于Q的相对熵:
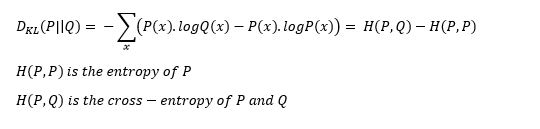
在不同的学习率经过200轮训练后成本和准确度的图如下:
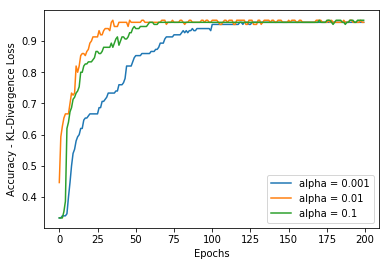
与多分类分类相比,KL散度更常用于逼近复杂函数。我们在使用变分自动编码器(VAE)等深度生成模型时经常使用KL散度。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2019/08/25/python-7-loss-function/
