
本文为fastai官方教程编译版本。若有错误,欢迎指正。
总目录:
- 查看数据:本节为初级教程,介绍怎样快速的查看你的数据和模型预测结果。
- 推理学习器(Inference Learner):本节为中级教程,介绍怎样为(模型)推理创建学习器。
-
自定义类ItemList(Custom ItemList):本节为高级教程,介绍如何创建类ItemBase与类ItemList。
-
使用极小的代价实现深度学习:本节介绍如何使用较少的GPU资源实现推理,和避免重启笔记内核的时间。
查看数据
本文目录:
- 查看输入与输出
- 视觉任务
- 分类问题
- 多标签问题
- 回归任务示例
- 分割任务示例
- 文本任务
- 语言模型
- 文本分类
- 列表(Tabular)
查看输入与输出
在本节教程中,我们将介绍如何在一个API中查看视觉任务、文本任务或者列表应用中的模型输入与输出。我们将处理不同的任务,而且每次都在DataBunch中使用data block API来获取数据、查看如何使用show_batch方法查看部分输入、训练合适地Learner后用show_results方法查看模型的实际输出。
注意:照例,此页面从Notebook生成,您可以在fasti git分支(https://github.com/fastai/fastai)中docs_src文件夹找到该笔记。这些示例旨在快速运行,所以我们使用部分示例数据集(且使用ResNet18作为主干网络,不进行长时间训练)。您可以更改任一参数来进行自己的实验!
视觉
为了快速访问fastai内部的所有视觉函数,我们使用通用的 Import 语句:
from fastai.vision import *
分类问题
让我们使用MINIST手写体数据集作为示例数据集:
mnist = untar_data(URLs.MNIST_TINY)tfms = get_transforms(do_flip=False)
它是用imagenet结构建立的,因此我们使用它来加载我们的训练和验证数据集,然后对其进行标记、变换、将其转换为ImageDataBunch,最终对其进行规范化。
data = (ImageList.from_folder(mnist)
.split_by_folder()
.label_from_folder()
.transform(tfms, size=32)
.databunch()
.normalize(imagenet_stats))
在DataBunch中正确设置好您的数据之后,我们可以调用函数 data.showbatch() 查看(可视化)数据。
data.show_batch()

请注意,在显示带有标签的图像之前,图像会自动进行归一化处理(从文件夹名称推断)。如果默认值5太大,我们可以指定行数和限定图形的大小。
data.show_batch(rows=3, figsize=(4,4))

现在,让我们创建一个 Learner 对象来训练分类器。
learn = cnn_learner(data, models.resnet18, metrics=accuracy)learn.fit_one_cycle(1,1e-2)
learn.save('mini_train')
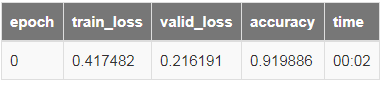
我们的模型迅速达到了91%左右的准确率,接下来让我们看下模型在一组验证样本上的表现。我们使用 show_results 方法实现。
learn.show_results()

由于验证集通常是经过排序的,因此我们仅获得了属于同一类的图像。然后,我们可以再次指定行数、图形大小以及要进行预测的数据集进行查看。
learn.show_results(ds_type=DatasetType.Train, rows=4, figsize=(8,10))

多标签问题
现在让我们使用planet数据集上进行演示,其(与其他数据集的)不同之处在于每个图像可以具有多个标签(而不仅仅是一个标签)
planet = untar_data(URLs.PLANET_TINY)
planet_tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
这里每张图片的标签都存储在labels.csv文件中。我们需要在文件名中添加前缀’train’和后缀’.jpg’,并设定每个标签之间用空格分开。
data = (ImageList.from_csv(planet, 'labels.csv', folder='train', suffix='.jpg')
.split_by_rand_pct()
.label_from_df(label_delim=' ')
.transform(planet_tfms, size=128)
.databunch()
.normalize(imagenet_stats))
我们可以通过函数data.show_batch来查看数据。
data.show_batch(rows=2, figsize=(9,7))

然后我们可以相当轻松的创建Learner对象和进行尝试性训练。
learn = cnn_learner(data, models.resnet18)
learn.fit_one_cycle(5,1e-2)
learn.save('mini_train')
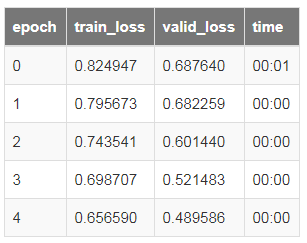
要查看实际的预测结果,我们只需要运行方法learn.show_results()即可。
learn.show_results(rows=3, figsize=(12,15))

回归问题
对于接下来这个示例,我们使用BIWI头部姿态(https://data.vision.ee.ethz.ch/cvl/gfanelli/head_pose/head_forest.html#db)数据集。在人物图像中,我们要找出人脸的中心。在fastai文档中,我们已经建立了一个包含有200张图像数据的BIWI数据集子样本集,同时将每个图像中的中心坐标对应文件名以字典的形式进行存储。
biwi = untar_data(URLs.BIWI_SAMPLE)
fn2ctr = pickle.load(open(biwi/'centers.pkl', 'rb'))
为了获取数据,我们使用这个字典去标记我们的项目。我们同样使用PointsItemList使目标类型为ImagePoints(用于确保可以正确的应用数据增强)。当调用函数transform时我们确保设置tfm_y=True.
data = (PointsItemList.from_folder(biwi)
.split_by_rand_pct(seed=42)
.label_from_func(lambda o:fn2ctr[o.name])
.transform(get_transforms(), tfm_y=True, size=(120,160))
.databunch()
.normalize(imagenet_stats))
接着,我们可以使用data.show_batch()可视化我们的数据.
data.show_batch(row=3, figsize=(9,6))

我们在使用函数learn.show_results()之前先尝试性训练下我们的模型。
learn = cnn_learner(data, models.resnet18, lin_ftrs=[100], ps=0.05)
learn.fit_one_cycle(5, 5e-2)
learn.save('mini_train')
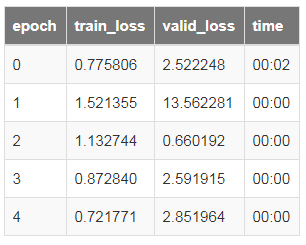
learn.show_results(rows=3)

分割示例
本节我们将使用camvid数据集(至少是其中的一部分数据),我们需要预测数据图像中的每一个像素点的类别。在“images”子文件夹中的每一幅图像都相当于对应的图像“labels”,也就是图像的分割掩码。
camvid = untar_data(URLs.CAMVID_TINY)
path_lbl = camvid/'labels'
path_img = camvid/'images'
我们从’codes.txt’文件中读取类别信息和每个图像与其相关掩码名称的映射关系。
codes = np.loadtxt(camvid/'codes.txt', dtype=str)
get_y_fn = lambda x: path_lbl/f'{x.stem}_P{x.suffix}'
数据模块API允许我们快速获取 DataBunch中的任何内容,同时我们可以通过函数show_batch查看。
data = (SegmentationItemList.from_folder(path_img)
.split_by_rand_pct()
.label_from_func(get_y_fn, classes=codes)
.transform(get_transforms(), tfm_y=True, size=128)
.databunch(bs=16, path=camvid)
.normalize(imagenet_stats))
data.show_batch(rows=2, figsize=(7,5))

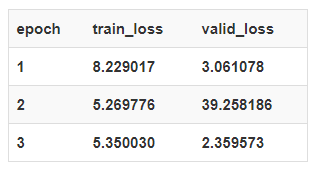
接下来,我们训练Unet网络几个轮次(epochs)。
注意:本次训练是相当不稳定的,使用更多地训练轮次与更全的数据集可以获得更好的结果。
learn = unet_learner(data, models.resnet18)learn.fit_one_cycle(3,1e-2)learn.save('mini_train')
总耗时(00:23)
learn.show_results()

文本
本节介绍在文本上的应用,同样地让我们从导入所有需要函数开始。
from fastai.text import *
语言模型
首先我们在imdb子数据集上微调(fine-tune)一个预训练模型。
imdb = untar_data(URLs.IMDB_SAMPLE)
data_lm = (TextList.from_csv(imdb, 'texts.csv', cols='text')
.split_by_rand_pct()
.label_for_lm()
.databunch())data_lm.save()
函数data.show_batch()同样也可以在这里使用。对于语言模型来说,它向我们展示了沿着批处理维度每个文本序列的开头(目标是猜下一个单词)。
data_lm.show_batch()

现在让我们定义一个语言模型学习器。

总耗时(Total time):00:25
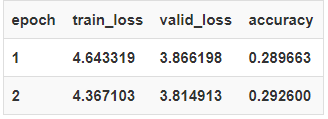
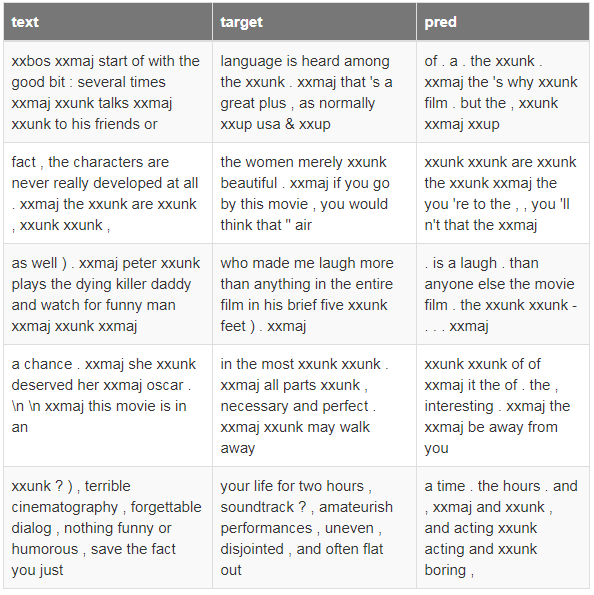
然后我们可以查看结果。它会显示确定数量的单词(默认20),以及之后的20个目标单词和预测的单词。
learn.show_results()
文本分类
本节介绍一个关于文本分类的例子。如果使用保存的编码器,我们要使用与语言模型相同的词汇表。
data_clas = (TextList.from_csv(imdb, 'texts.csv', cols='text', vocab=data_lm.vocab)
.split_from_df(col='is_valid')
.label_from_df(cols='label')
.databunch(bs=42))
这里通过函数 show_batch 显示了每次评审(review)的开始(信息)以及其目标(target)。
data_clas.show_batch()

然后我们可以使用之前的编码器训练一个分类器。
learn = text_classifier_learner(data_clas, AWD_LSTM)
learn.load_encoder('mini_train_encoder')
learn.fit_one_cycle(2, slice(1e-3,1e-2))learn.save('mini_train_clas')
总耗时(Total time):00:25
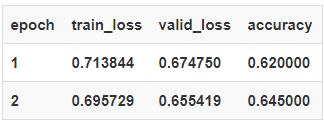
learn.show_results()
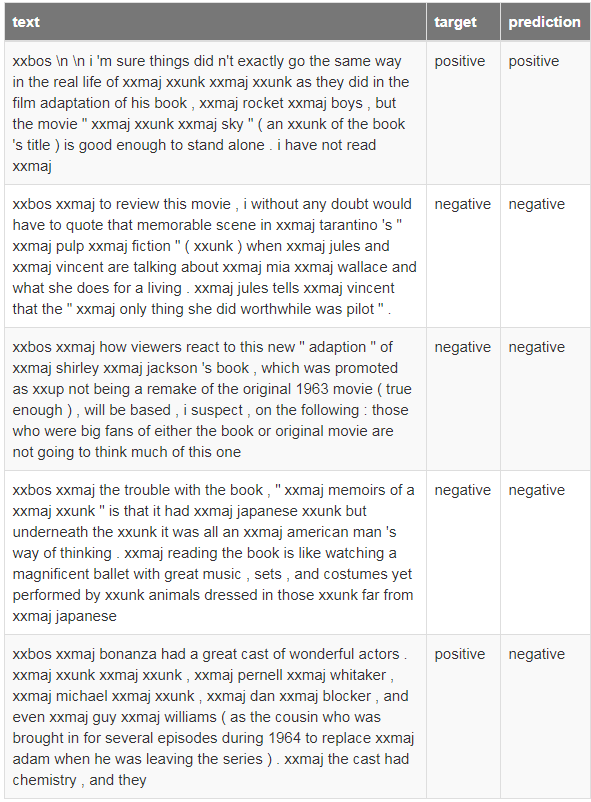
列表
本节介绍列表数据中的应用范例。首先让我们导入全部所需要的函数。
from fastai.tabular import *
我们使用adult数据集(https://archive.ics.uci.edu/ml/datasets/adult)中的一部分数据。当我们读取csv文件时,我们需要指定相关变量、类别变量、连续变量和要使用的处理器。
adult = untar_data(URLs.ADULT_SAMPLE)df = pd.read_csv(adult/'adult.csv')
dep_var = 'salary'
cat_names = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country']
cont_names = ['education-num', 'hours-per-week', 'age', 'capital-loss', 'fnlwgt', 'capital-gain']
procs = [FillMissing, Categorify, Normalize]
然后,我们可以使用数据块API在使用data.show_batch()之前获取所有内容。
data = (TabularList.from_df(df, path=adult, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(valid_idx=range(800,1000))
.label_from_df(cols=dep_var)
.databunch())
data.show_batch()
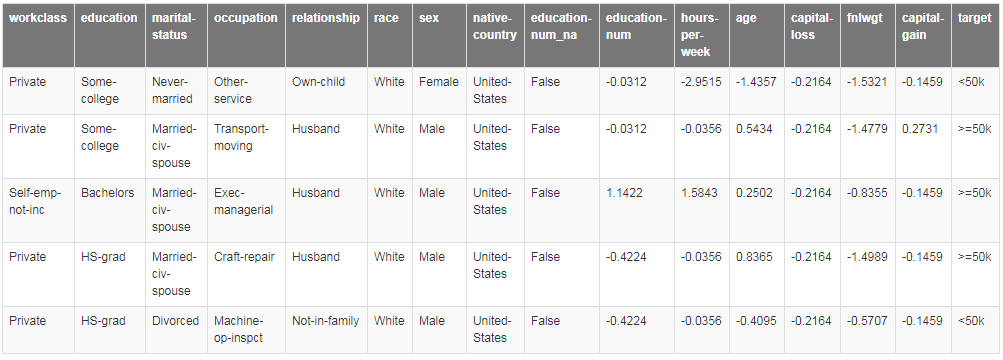
这里我们可以得到尝试性训练后的tabular_learner。
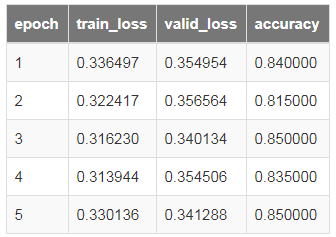
learn = tabular_learner(data, layers=[200,100], metrics=accuracy)
learn.fit(5, 1e-2)
learn.save('mini_train')
总耗时(Total time):00:19
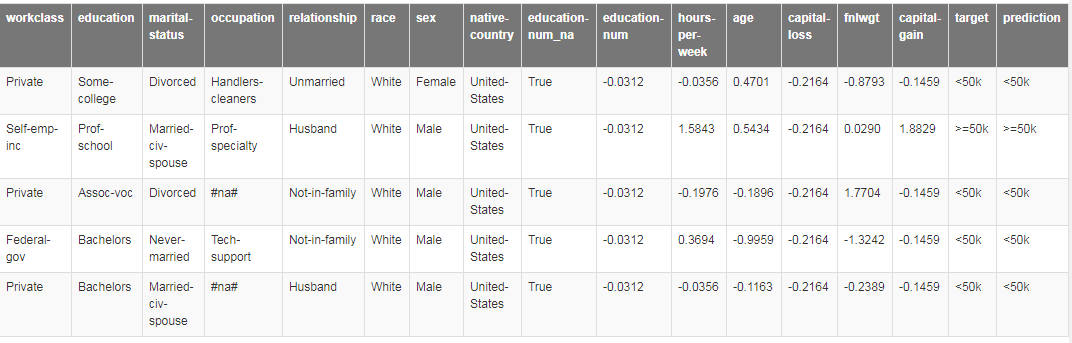
我们可以使用learn.show_results()(查看结果)。
learn.show_results()
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/02/14/fastai-%e5%ae%98%e6%96%b9%e6%95%99%e7%a8%8b%e4%b9%8b%e6%9f%a5%e7%9c%8b%e6%95%b0%e6%8d%ae/
