
概述
- 学习如何开发自动生成音乐的端到端模型
- 理解WaveNet架构,并使用Keras从头实现它
- 比较WaveNet与建立自动音乐生成模型的LSTM的性能
介绍
“如果我不是物理学家,我可能会成为音乐家。我经常在音乐上思考。我在音乐中实现我的白日梦。我从音乐的角度来看待我的生活。——爱因斯坦
我可能不是像爱因斯坦先生那样的物理学家,但我完全同意他对音乐的看法!我不记得有哪一天我没有打开我的音乐播放器。我上下班的旅途伴随着音乐,老实说,它帮助我专注于我的工作。
我一直梦想着作曲,但对乐器却不是很熟悉。直到我遇到了深度学习。使用特定的技术和框架,我可以创作自己的原创音乐,而不需要真正了解任何音乐理论!
这是我最喜欢的专业项目之一。我把我的两个爱好——音乐和深度学习——结合起来,创造了一个自动生成音乐的模型。梦想成真了!

我很高兴与你分享我的方法,包括整个代码,使你能够生成自己的音乐!我们将首先快速理解自动音乐生成的概念,然后再深入探讨我们可以使用的不同方法。最后,我们将启动Python并设计我们自己的自动音乐生成模型。
目录
- 什么是自动音乐生成?
- 音乐的构成要素是什么?
- 不同的音乐生成方法
- 使用WaveNet架构
- 使用长短时记忆(LSTM)
- 实现-使用Python自动作曲
什么是自动音乐生成?
音乐是一种艺术,一种通用的语言。
我把音乐定义为不同频率的音调的集合。因此,音乐的自动生成是一个创作一小段音乐的过程,并且在在这个过程中人类的介入不多。

产生音乐的最简单形式是什么?
这一切都是从随机选择声音并将它们组合成一段音乐开始的。在1787年,莫扎特提出了一个骰子游戏,这些随机的声音选择。他手工创作了近272个音调!然后,他根据两个骰子的总和选择一个音调。

另一个有趣的想法是利用音乐语法来产生音乐。
音乐语法包括正确安排和组合音乐声音以及正确演奏音乐作品所必需的知识 -音乐语法基础
在20世纪50年代早期,Iannis Xenakis使用统计和概率的概念来创作音乐——通常被称为随机音乐。他把音乐定义为偶然发生的一系列元素(或声音)。因此,他用随机理论来阐述它。他对元素的随机选择完全依赖于数学概念。
最近,深度学习架构已经成为自动生成音乐的最新技术。在本文中,我将讨论使用WaveNet和LSTM(长短时记忆)架构实现自动作曲的两种不同方法。
音乐的构成要素是什么?
音乐基本上是由音符和和弦组成的。让我从钢琴乐器的角度来解释这些术语:
- 注:单个键发出的声音称为音符
- 和弦:两个或多个键同时发出的声音称为和弦。一般来说,大多数和弦包含至少3个键音
- 八度:重复的模式称为八度。每个八度音阶包含7个白键和5个黑键
自动生成音乐的不同方法
我将详细讨论两种基于深度学习的自动生成音乐的架构——WaveNet和LSTM。但是,为什么只有深度学习架构呢?
深度学习是受神经结构启发的机器学习领域。这些网络自动从数据集中提取特征,并且能够学习任何非线性函数。这就是为什么神经网络被称为通用函数逼近器。
因此,深度学习模型是自然语言处理(NLP)、计算机视觉、语音合成等领域的最新技术。让我们看看如何为音乐作曲建立这些模型。
方法1:使用WaveNet
WaveNet是一个基于深度学习的原始音频生成模型,由谷歌DeepMind开发。
WaveNet的主要目标是从原始数据分布中生成新的样本。因此,它被称为生成模型。
Wavenet类似于NLP中的语言模型。
在一个语言模型中,给定一个单词序列,该模型试图预测下一个单词:

与WaveNet中的语言模型类似,给定一个样本序列,它尝试预测下一个样本。
方法2:使用长短时记忆(LSTM)模型
长短时记忆模型(Long- Short-Term Memory Model,俗称LSTM)是循环神经网络(RNNs)的一种变体,它能够捕获输入序列中的长期依赖关系。LSTM在序列到序列建模任务中有着广泛的应用,如语音识别、文本摘要、视频分类等。
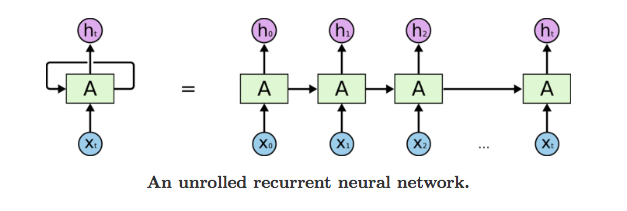
让我们详细讨论如何使用这两种方法来训练我们的模型。
方法1:使用WaveNet
Wavenet:训练阶段
这是一个多对一的问题,输入是一系列振幅值,输出是随后的值。
让我们看看如何准备输入和输出序列。
波形网输入:
WaveNet将原始音频作为输入。原始音频波是指波在时间序列域中的表示。
在时间序列域中,音频波以振幅值的形式表示,振幅值记录在不同的时间间隔内:

波形网输出:
给定振幅值的序列,WaveNet尝试预测连续的振幅值。
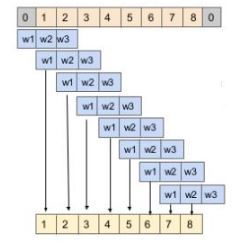
让我们通过一个例子来理解这一点。考虑一个采样率为16,000(即每秒16,000个次采样)的5秒的音频波。现在,我们有80000个样本,每隔5秒记录一次。让我们把音频分成大小相等的块,比如1024(这是一个超参数)。
下图展示了模型的输入和输出序列:
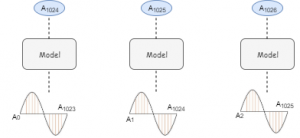
我们可以对其余的块使用类似的过程。
从上面我们可以推断出每个块的输出只依赖于过去的信息(即以前的时间步),而不依赖于未来的时间步。因此,该任务称为自回归任务,该模型称为自回归模型。
推理阶段
在推理阶段,我们将尝试生成新的样本。让我们看看怎么做:
- 选择一个随机的样本值数组作为建模的起点
- 现在,模型输出所有样本的概率分布
- 选择具有最大概率的值并将其附加到样本数组中
- 删除第一个元素并作为下一个迭代的输入传递
- 对一定数量的迭代重复步骤2和4
理解WaveNet架构
WaveNet的构建块是因果扩展的一维卷积层。让我们首先了解相关概念的重要性。
为什么?什么是卷积?
使用卷积的一个主要原因是从输入中提取特征。
例如,在图像处理的情况下,将图像与过滤器进行卷积可以得到一个特征图。

卷积是结合两个函数的数学运算。在图像处理中,卷积是图像某些部分与核的线性组合
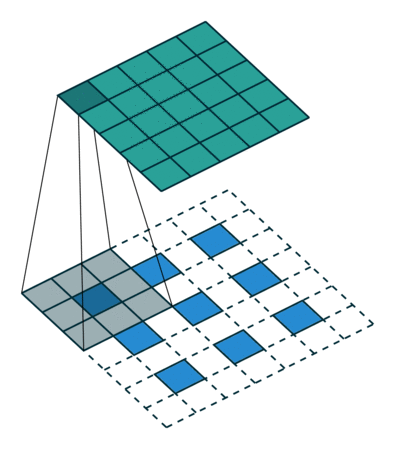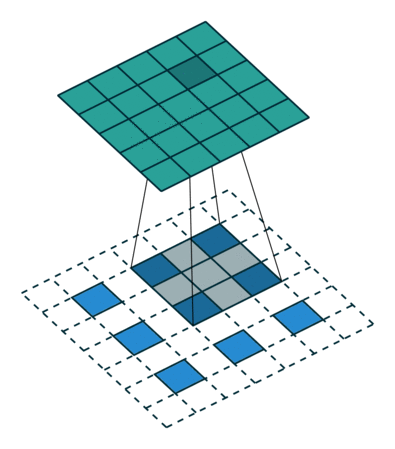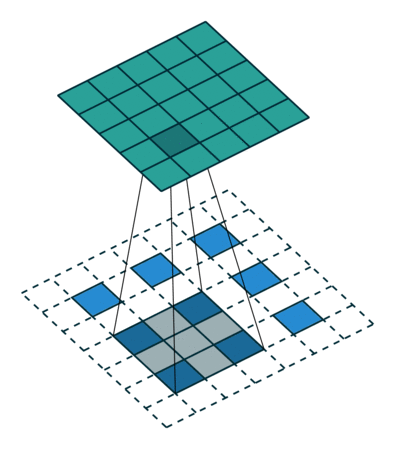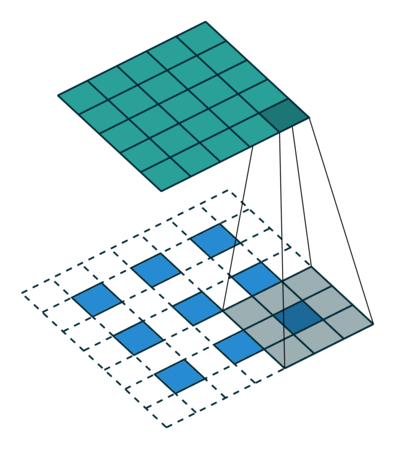
什么是一维卷积?
一维卷积的目标类似于长短时记忆模型。它用于解决与LSTM类似的任务。在一维卷积中,一个核或一个滤波器只沿着一个方向运动:
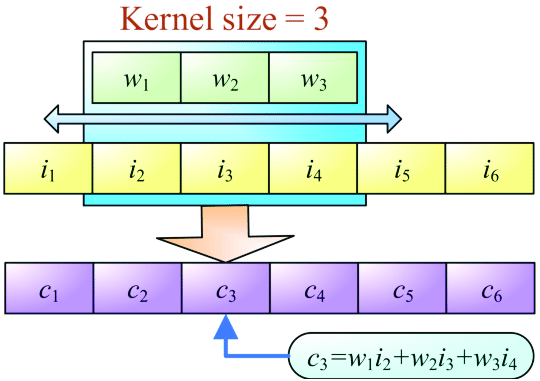
卷积的输出取决于核的大小、输入形状、填充类型和步幅。现在,我将带你通过不同类型的填充来理解使用因果扩展一维卷积层的重要性。
当我们设置padding有效值时,输入和输出序列的长度会发生变化。输出的长度小于输入的长度:
当我们将padding设为相同时,在输入序列的两边填充0,使输入和输出的长度相等:
1D卷积的优点:
- 捕获输入序列中出现的顺序信息
- 与GRU或LSTM相比,训练要快得多,因为它们不像循环神经网络是串联的
1D卷积的缺点:
- 当padding设置为same时,时间步t的输出与之前的t-1和未来的时间步t+1进行卷积。因此,它违反了自回归原则
- 当填充被设置为valid时,输入和输出序列的长度会发生变化,这是计算残差连接所需的(稍后将介绍)
这为因果卷积扫清了道路。
注意:我在这里提到的优点和缺点是针对这个问题的。
什么是一维因果卷积?
这被定义为卷积,其中在t时刻的输出只与来自t时刻以及更早的前一层的元素进行卷积。
简单地说,普通卷积和因果卷积只在填充上不同。在因果卷积中,在输入序列的左侧添加0,以保持自回归原理:
因果1D卷积的优点:
- 因果卷积不考虑未来的时间步,而未来的时间步是构建生成模型的一个标准
因果1D卷积的缺点:
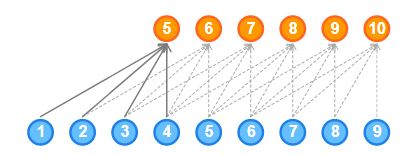
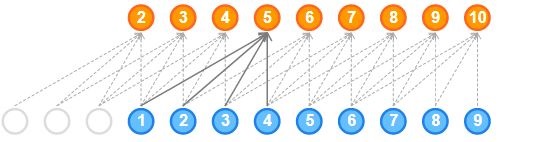
- 因果卷积不能回溯到过去或者序列中较早发生的时间步。因此,因果卷积的接受域非常低。网络的接受域是指影响输出的输入数量:
正如你在这里看到的,输出仅受5个输入的影响。因此,网络的接受域为5,非常低。网络的接受域也可以通过添加大尺寸的核来增加,但是要记住计算复杂度会增加。
这让我们想到了因果扩展一维卷积的概念。
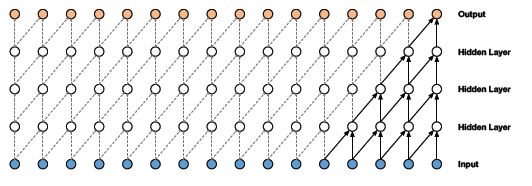
什么是因果扩展一维卷积?
在核值之间存在空穴或空隙的因果一维卷积层称为扩展一维卷积。
要添加的空格数由扩展率给出。它定义了网络的接收域。大小为k且扩展速率为d的核在k的每个值之间有d-1个洞。

正如你在这里看到的,将一个33的核与一个77的输入用扩展率2来进行卷积,其接收域为5*5。
扩展一维因果卷积的优点:
- 扩展1D卷积网络通过指数增加每一隐藏层的扩展率来增加接受域:
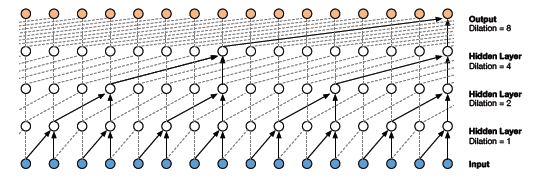
正如你在这里看到的,输出受到所有输入的影响。因此,网络的接受域是16。
WaveNet的残差块:
一个块包含残差连接和跳跃连接,这些连接只是为了加快模型的收敛速度而添加的:
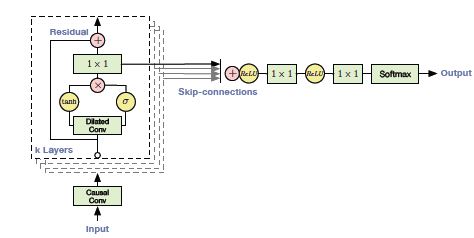
WaveNet的工作流程:
- 输入被输入到一个因果一维卷积
- 然后,输出被馈送到两个不同的sigmoid和tanh激活的扩展一维卷积层
- 两个不同激活值的元素相乘接着是跳跃连接
- 在元素上加入一个跳跃连接和因果1D的输出会产生残差
- 跳跃连接和因果一维输出来计算残差
方法2:长短时记忆(LSTM)方法
另一种自动生成音乐的方法是基于长短时记忆(LSTM)模型。输入和输出序列的准备类似于WaveNet。在每个时间步,振幅值被输入到长短时记忆单元-然后计算隐藏的向量,并将其传递到下一个时间步。
在$h_t$时刻的当前隐藏向量是基于$h_t$时刻的当前输入$a_t$和之前的隐藏向量$h_{t-1}$计算的。这是如何捕获序列信息在任何循环神经网络:
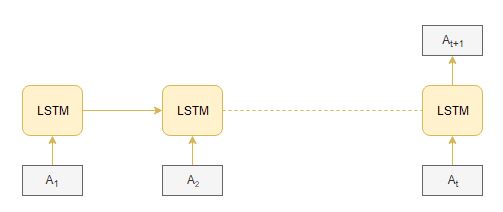
LSTM的优点:
- 捕获输入序列中出现的顺序信息
LSTM的缺点:
- 由于它按顺序处理输入,因此会消耗大量的训练时间
实现-使用Python自动生成音乐
等待结束了!让我们开发一个自动生成音乐的端到端模型。打开你的Jupyter 笔记本或者Colab(或者任何你喜欢的IDE)。
下载数据集:
我从众多资源中下载并组合了一架数字钢琴的多个古典音乐文件。你可以从这里下载最终的数据集。
https://drive.google.com/file/d/1qnQVK17DNVkU19MgVA4Vg88zRDvwCRXw/view?usp=sharing
让我们首先为可重复的结果设置种子。这是因为深度学习模型在执行时由于随机性可能会输出不同的结果。这确保了我们每次都能得到相同的结果。
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(2)
导入库:
Music 21是由麻省理工学院为理解音乐数据而开发的Python库。MIDI是存储音乐文件的标准格式(它代表乐器数字接口)。MIDI文件包含的是指令而不是实际的音频。因此,它占用的空间很少。这就是为什么它通常是首选传输文件。
#处理MIDI文件
from music21 import *
#数组处理
import numpy as np
import os
#随机数生成
import random
#keras构建深度学习模型
from keras.layers import *
from keras.models import *
import keras.backend as K
读取数据:
定义一个读取MIDI文件的函数。它返回音乐文件中的一组音符和和弦。
def read_midi(file):
notes=[]
notes_to_parse = None
#解析MIDI文件
midi = converter.parse(file)
#基于乐器分组
s2 = instrument.partitionByInstrument(midi)
#遍历所有的乐器
for part in s2.parts:
#只选择钢琴
if 'Piano' in str(part):
notes_to_parse = part.recurse()
#查找特定元素是音符还是和弦
for element in notes_to_parse:
if isinstance(element, note.Note):
notes.append(str(element.pitch))
elif isinstance(element, chord.Chord):
notes.append('.'.join(str(n) for n in element.normalOrder))
return notes
从目录中读取MIDI文件:
#读取所有文件名
files=[i for i in os.listdir() if i.endswith(".mid")]
#读取每个midi文件
all_notes=[]
for i in files:
all_notes.append(read_midi(i))
#所有midi文件的音符和和弦
notes = [element for notes in all_notes for element in notes]
准备文章中提到的输入和输出序列:
#输入序列的长度
no_of_timesteps = 128
n_vocab = len(set(notes))
pitch = sorted(set(item for item in notes))
#为每个note分配唯一的值
note_to_int = dict((note, number) for number, note in enumerate(pitch))
#准备输入和输出序列
X = []
y = []
for notes in all_notes:
for i in range(0, len(notes) - no_of_timesteps, 1):
input_ = notes[i:i + no_of_timesteps]
output = notes[i + no_of_timesteps]
X.append([note_to_int[note] for note in input_])
y.append(note_to_int[output])
卷积1D或LSTM的输入必须是(样本、时间步、特征)的形式。因此,让我们根据需要的形状来重新设计输入数组。注意,每个时间步中的特征数量为1:
X = np.reshape(X, (len(X), no_of_timesteps, 1))
#标准化输入
X = X / float(n_vocab)
我在这里定义了两个架构——WaveNet和LSTM。请尝试这两种架构来理解WaveNet架构的重要性。
def lstm():
model = Sequential()
model.add(LSTM(128,return_sequences=True))
model.add(LSTM(128))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
return model
我简化了WaveNet的结构,没有添加残差连接和跳跃连接,因为这些层的作用是提高更快的收敛速度(而WaveNet将原始音频作为输入)。但在我们的情况下,输入将是一组节点和和弦,因为我们正在生成音乐:
K.clear_session()
def simple_wavenet():
no_of_kernels=64
num_of_blocks= int(np.sqrt(no_of_timesteps)) - 1
model = Sequential()
for i in range(num_of_blocks):
model.add(Conv1D(no_of_kernels,3,dilation_rate=(2**i),padding='causal',activation='relu'))
model.add(Conv1D(1, 1, activation='relu', padding='causal'))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(n_vocab, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
return model
定义每50个epoch后保存模型的回调:
import keras
mc = keras.callbacks.ModelCheckpoint('model{epoch:03d}.h5', save_weights_only=False, period=50)
实例化并训练批处理大小为128的模型:
model = simple_wavenet()
model.fit(X,np.array(y), epochs=300, batch_size=128,callbacks=[mc])
这是本文中提到的推理阶段的一个实现。它为一定次数的迭代后预测最有可能的元素:
def generate_music(model, pitch, no_of_timesteps, pattern):
int_to_note = dict((number, note) for number, note in enumerate(pitch))
prediction_output = []
# 生成50个
for note_index in range(50):
#输入数据
input_ = np.reshape(pattern, (1, len(pattern), 1))
#预测并选出最大可能的元素
proba = model.predict(input_, verbose=0)
index = np.argmax(proba)
pred = int_to_note[index]
prediction_output.append(pred)
pattern = list(pattern)
pattern.append(index/float(n_vocab))
#将第一个值保留在索引0处
pattern = pattern[1:len(pattern)]
return prediction_output
下面是一个函数转换成一个MIDI文件组成的音乐:
def convert_to_midi(prediction_output):
offset = 0
output_notes = []
# 根据模型生成的值创建音符和和弦对象
for pattern in prediction_output:
# 模式是和弦
if ('.' in pattern) or pattern.isdigit():
notes_in_chord = pattern.split('.')
notes = []
for current_note in notes_in_chord:
new_note = note.Note(int(current_note))
new_note.storedInstrument = instrument.Piano()
notes.append(new_note)
new_chord = chord.Chord(notes)
new_chord.offset = offset
output_notes.append(new_chord)
# 模式是音符
else:
new_note = note.Note(pattern)
new_note.offset = offset
new_note.storedInstrument = instrument.Piano()
output_notes.append(new_note)
# 指定两个音符之间的持续时间
offset+ = 0.5
# offset += random.uniform(0.5,0.9)
midi_stream = stream.Stream(output_notes)
midi_stream.write('midi', fp='music.mid')
现在让我们来谱写自己的音乐吧!
#为第一次迭代选择随机块
start = np.random.randint(0, len(X)-1)
pattern = X[start]
#载入最好的模型
model=load_model('model300.h5')
#生成和保存音乐
music = generate_music(model,pitch,no_of_timesteps,pattern)
convert_to_midi(music)
以下是我们的模型创作的几首曲子。是时候欣赏音乐了!
太棒了,对吧?但你的学习还不止于此。这里有一些方法可以进一步提高模型的性能:
- 增加训练数据集的大小会产生更好的旋律,因为深度学习模型可以很好地在大型训练数据集上进行泛化
- 在构建具有大量层的模型时添加跳跃和残差连接
结尾
深度学习在我们的日常生活中有着广泛的应用。解决任何问题的关键步骤都是理解问题陈述,制定它并定义解决问题的体系结构。
在做这个项目的时候,我有很多乐趣(和学习)。音乐是我的爱好,把深度学习和音乐结合起来是很有趣的。
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/02/26/%e9%80%9a%e8%bf%87%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e6%9d%a5%e5%88%9b%e4%bd%9c%e8%87%aa%e5%b7%b1%e7%9a%84%e9%9f%b3%e4%b9%90-%ef%bc%88%e9%99%84%e4%bb%a3%e7%a0%81%ef%bc%89/
