
OpenCV-Python 系列 五十六 | 理解K-Means聚类
本文是全系列中第39 / 63篇:OpenCV-Python
- OpenCV-Python 系列 四 | 视频入门
- OpenCV-Python 系列 十二 | 图像的几何变换
- OpenCV-Python 系列 二十 | 轮廓:入门
- OpenCV-Python 系列 二十八 | 直方图4:直方图反投影
- OpenCV-Python 系列 三十六 | 哈里斯角检测
- OpenCV-Python 系列 四十四 | 特征匹配 + 单应性查找对象
- OpenCV-Python 系列 五十二 | 理解K近邻
- OpenCV-Python 系列 六十 | 高动态范围
- OpenCV-Python 系列 五 | OpenCV中的绘图功能
- OpenCV-Python 系列 十三 | 图像阈值
- OpenCV-Python 系列 二十一 | 轮廓特征
- OpenCV-Python 系列 二十九 | 傅里叶变换
- OpenCV-Python 系列 三十七 | Shi-tomas拐角检测器和益于跟踪的特征
- OpenCV-Python 系列 四十五 | 如何使用背景分离方法
- OpenCV-Python 系列 五十三 | 使用OCR手写数据集运行KNN
- OpenCV-Python 系列 六十一 | 级联分类器
- OpenCV-Python 系列 六 | 鼠标作为画笔
- OpenCV-Python 系列 十四 | 图像阈值
- OpenCV-Python 系列 二十二 | 轮廓属性
- OpenCV-Python 系列 三十 | 模板匹配
- OpenCV-Python 系列 三十八 | SIFT尺度不变特征变换
- OpenCV-Python 系列 四十六 | Meanshift和Camshift
- OpenCV-Python 系列 五十四 | 理解SVM
- OpenCV-Python 系列 六十二 | 级联分类器训练
- OpenCV-Python 系列 七 | 轨迹栏作为调色板
- OpenCV-Python 系列 十五 | 图像平滑
- OpenCV-Python 系列 二十三 | 轮廓:更多属性
- OpenCV-Python 系列 三十一 | 霍夫线变换
- OpenCV-Python 系列 三十九 | SURF简介(加速的强大功能)
- OpenCV-Python 系列 四十七 | 光流
- OpenCV-Python 系列 五十五 | 使用OCR手写数据集运行SVM
- OpenCV-Python 系列 六十三 | OpenCV-Python Bindings 如何工作?
- OpenCV-Python 系列 八 | 图像的基本操作
- OpenCV-Python 系列 十六 | 形态学转换
- OpenCV-Python 系列 二十四 | 轮廓分层
- OpenCV-Python 系列 三十二 | 霍夫圈变换
- OpenCV-Python 系列 四十 | 用于角点检测的FAST算法
- OpenCV-Python 系列 四十八 | 相机校准
- OpenCV-Python 系列 五十六 | 理解K-Means聚类
- OpenCV-Python 系列 一 | 系列简介与目录
- OpenCV-Python 系列 九 | 图像上的算术运算
- OpenCV-Python 系列 十七 | 图像梯度
- OpenCV-Python 系列 二十五 | 直方图-1:查找、绘制和分析
- OpenCV-Python 系列 三十三 | 图像分割与Watershed算法
- OpenCV-Python 系列 四十一 | BRIEF(二进制的鲁棒独立基本特征)
- OpenCV-Python 系列 四十九 | 姿态估计
- OpenCV-Python 系列 五十七 | OpenCV中的K-Means聚类
- OpenCV-Python 系列 二 | 安装OpenCV-Python
- OpenCV-Python 系列 十 | 性能衡量和提升技术
- OpenCV-Python 系列 十八 | Canny边缘检测
- OpenCV-Python 系列 二十六 | 直方图-2:直方图均衡
- OpenCV-Python 系列 三十四 | 交互式前景提取使用GrabCut算法
- OpenCV-Python 系列 四十二 | ORB(面向快速和旋转的BRIEF)
- OpenCV-Python 系列 五十 | 对极几何
- OpenCV-Python 系列 五十八 | 图像去噪
- OpenCV-Python 系列 三 | 图像入门
- OpenCV-Python 系列 十一 | 改变颜色空间
- OpenCV-Python 系列 十九 | 图像金字塔
- OpenCV-Python 系列 二十七 | 直方图-3:二维直方图
- OpenCV-Python 系列 三十五 | 理解特征
- OpenCV-Python 系列 四十三 | 特征匹配
- OpenCV-Python 系列 五十一 | 立体图像的深度图
- OpenCV-Python 系列 五十九 | 图像修补
目标
在本章中,我们将了解K-Means聚类的概念,其工作原理等。
理论
我们将用一个常用的例子来处理这个问题。
T-shirt尺寸问题
考虑一家公司,该公司将向市场发布新型号的T恤。显然,他们将不得不制造不同尺寸的模型,以满足各种规模的人们的需求。因此,该公司会记录人们的身高和体重数据,并将其绘制到图形上,如下所示:
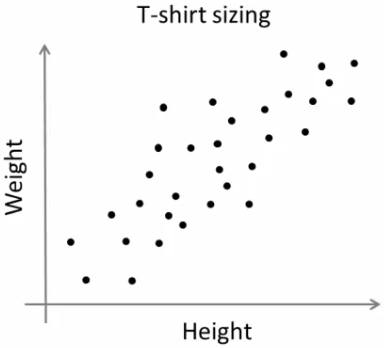
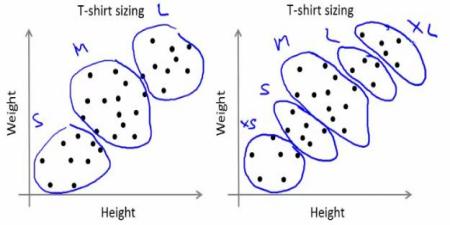
公司无法制作所有尺寸的T恤。取而代之的是,他们将人划分为小,中和大,并仅制造这三种适合所有人的模型。可以通过k均值聚类将人员分为三组,并且算法可以为我们提供最佳的3种大小,这将满足所有人员的需求。如果不是这样,公司可以将人员分为更多的组,可能是五个,依此类推。查看下面的图片:
如何起作用?
该算法是一个迭代过程。我们将在图像的帮助下逐步解释它。
考虑如下一组数据(您可以将其视为T恤问题)。我们需要将此数据分为两类。
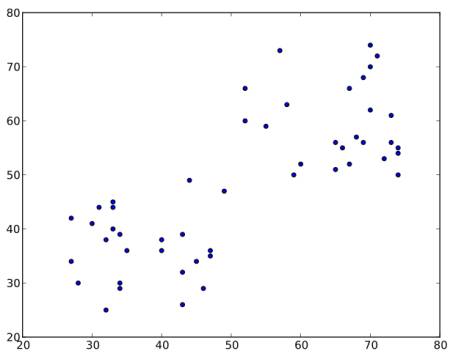
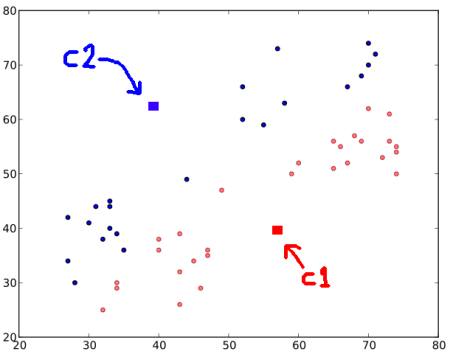
步骤:1 -算法随机选择两个质心$C_1$和$C_2$(有时,将任何两个数据作为质心)。
步骤:2 -计算每个点到两个质心的距离。如果测试数据更接近$C_1$,则该数据标记为“0”。如果它更靠近$C_2$,则标记为“1”(如果存在更多质心,则标记为“2”,“3”等)。
在我们的示例中,我们将为所有标记为红色的“0”和标记为蓝色的所有“1”上色。因此,经过以上操作,我们得到以下图像。
步骤:3 -接下来,我们分别计算所有蓝点和红点的平均值,这将成为我们的新质心。即$C_1$和$C_2$转移到新计算的质心。(请记住,显示的图像不是真实值,也不是真实比例,仅用于演示)。
再次,使用新的质心执行步骤2,并将标签数据设置为’0’和’1’。
所以我们得到如下结果:
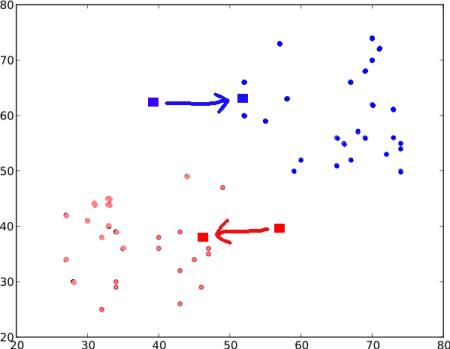
现在,迭代步骤2和步骤3,直到两个质心都收敛到固定点。*(或者可以根据我们提供的标准(例如最大的迭代次数或达到特定的精度等)将其停止。)***这些点使测试数据与其对应质心之间的距离之和最小**。或者简单地说,$C_1↔Red_Points$和$C_2↔Blue_Points$之间的距离之和最小。
$$
minimize ;bigg[J = sum_{All: Red_Points}distance(C1,Red_Point) + sum_{All: Blue_Points}distance(C2,Blue_Point)bigg]
$$
最终结果如下所示:
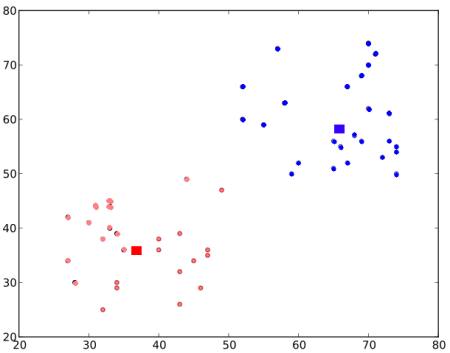
因此,这仅仅是对K-Means聚类的直观理解。有关更多详细信息和数学解释,请阅读任何标准的机器学习教科书或查看其他资源中的链接。它只是K-Means聚类的宏观层面。此算法有很多修改,例如如何选择初始质心,如何加快迭代过程等。
附加资源
- Machine Learning Course, Video lectures by Prof. Andrew Ng (Some of the images are taken from this)
练习s
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/04/02/opencv-python-%e7%b3%bb%e5%88%97-%e4%ba%94%e5%8d%81%e5%85%ad-%e7%90%86%e8%a7%a3k-means%e8%81%9a%e7%b1%bb/
