
MMDetection官方教程 技术细节 | 四
本文是全系列中第1 / 4篇:MMDetection
- MMDetection官方教程 技术细节 | 四
- MMDetection 安装 | 一
- MMDetection 入门 | 二
- MMDetection 基准测试 和 Model Zoo | 三
作者|open-mmlab
编译|Flin
来源|Github
技术细节
在本节中,我们将介绍训练检测器的主要单元:数据管道,模型和迭代管道。
数据管道
按照规定, 我们使用Dataset和DataLoader用于多个处理的数据加载。Dataset返回对应于模型的forward方法的参数的数据项字典。由于对象检测中的数据大小可能不同(图像大小,gt bbox大小等),因此我们在MMCV中引入了一种新类型DataContainer,以帮助收集和分配不同大小的数据。有关更多详细信息,请参见此处(https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py) 。
对数据准备管道和数据集进行分解。通常,数据集定义了如何处理注释,数据管道定义所有准备数据字典的步骤。流水线由一系列操作组成。每个操作都将一个dict作为输入,并为下一个转换输出一个dict。
在下图中,我们展示了经典管道。蓝色块是管道操作。随着管道的进行,每个操作员可以向结果字典添加新键(标记为绿色)或更新现有键(标记为橙色)。
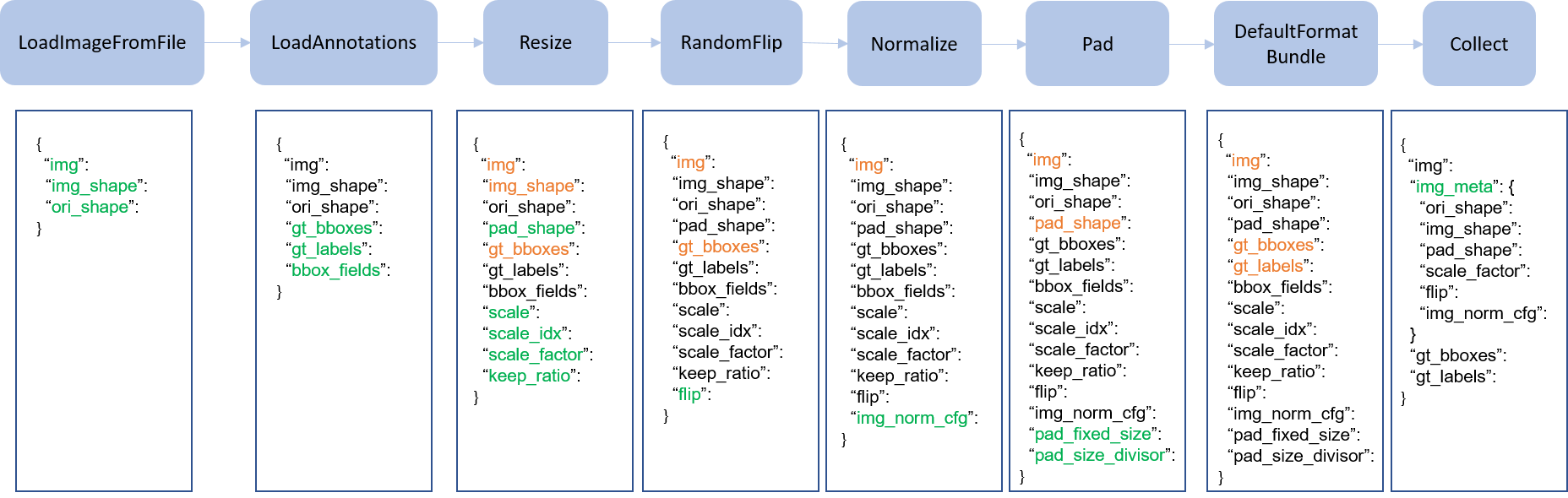
这些操作分为数据加载, 预处理, 格式化和测试时间扩充。
这是Faster R-CNN的管道示例。
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
对于每个操作,我们都列出了添加/更新/删除的相关字典字段。
数据加载
LoadImageFromFile
– 添加: img, img_shape, ori_shape
LoadAnnotations
– 添加: gt_bboxes, gt_bboxes_ignore, gt_labels, gt_masks, gt_semantic_seg, bbox_fields, mask_fields
LoadProposals
– 添加: proposals
预处理
Resize
– 添加: scale, scale_idx, pad_shape, scale_factor, keep_ratio
– 更新: img, img_shape, *bbox_fields, *mask_fields, *seg_fields
RandomFlip
– 添加: flip
– 更新: img, *bbox_fields, *mask_fields, *seg_fields
Pad
– add: pad_fixed_size, pad_size_divisor
– 更新: img, pad_shape, *mask_fields, *seg_fields
RandomCrop
– 更新: img, pad_shape, gt_bboxes, gt_labels, gt_masks, *bbox_fields
Normalize
– 添加: img_norm_cfg
– 更新: img
SegRescale
– 更新: gt_semantic_seg
PhotoMetricDistortion
– 更新: img
Expand
– 更新: img, gt_bboxes
MinIoURandomCrop
– 更新: img, gt_bboxes, gt_labels
Corrupt
– 更新: img
格式化
ToTensor
– 更新: specified by keys.
ImageToTensor
– 更新: specified by keys.
Transpose
– 更新: specified by keys.
ToDataContainer
– 更新: specified by fields.
DefaultFormatBundle
– 更新: img, proposals, gt_bboxes, gt_bboxes_ignore, gt_labels, gt_masks, gt_semantic_seg
Collect
– 添加: img_meta (img_meta的键由meta_keys指定)
– 删除: 除 keys指定的键以外的所有其他键
测试时间增加
MultiScaleFlipAug
模型
在MMDetection中,模型组件基本上分为4种类型。
– backbone: 通常是FCN网络,用于提取特征图,例如ResNet。
– neck: backbones 和 heads之间的部分, 例如FPN, ASPP.
– head: 用于特定任务的部分,例如bbox 预测 和 mask 预测.
– roi 提取器: 用于从特征图中提取特征部分,例如RoI Align。
我们还使用上述组件编写了一些通用的检测管道,例如SingleStageDetector 和 TwoStageDetector.
建立与基本部件的模型
遵循一些基本流程(例如two-stage detectors),可以通过配置文件轻松定制模型结构。
如果我们要实现一些新组件,例如,路径聚合网络中用于实例分段的路径聚合FPN结构(https://arxiv.org/abs/1803.01534) ,则有两件事要做。
- 在
mmdet/models/necks/pafpn.py中创建一个新文件。.from ..registry import NECKS @NECKS.register class PAFPN(nn.Module): def __init__(self, in_channels, out_channels, num_outs, start_level=0, end_level=-1, add_extra_convs=False): pass def forward(self, inputs): ### 忽略实现 pass - 在
mmdet/models/necks/__init__.py中导入模块from .pafpn import PAFPN - 修改配置文件,从
neck=dict( type='FPN', in_channels=[256, 512, 1024, 2048], out_channels=256, num_outs=5)变成
neck=dict( type='PAFPN', in_channels=[256, 512, 1024, 2048], out_channels=256, num_outs=5)
我们将发布更多组件(backbones, necks, heads) 用于研究的目的。
写一个新的模型
要编写新的检测管道,你需要继承BaseDetector,它定义了以下抽象方法。
extract_feat():给定一批形状(n,c,h,w)的图像,提取特征图。forward_train():训练模式的forward方法simple_test():无扩展的单尺度测试-
aug_test():扩展测试(多尺度、翻转等)
TwoStageDetector (https://github.com/hellock/mmdetection/blob/master/mmdet/models/detectors/two_stage.py)
是一个很好的例子,展示了如何做到这一点。
迭代管道
我们对单台机器和多台机器都采用分布式训练。假设服务器有8个GPU,将启动8个进程,并且每个进程都在单个GPU上运行。
每个过程都保持一个独立的模型,数据加载器和优化器。模型参数在开始时仅同步一次。在向前和向后传递之后,所有GPU之间的梯度都将减小,优化器将更新模型参数。由于所有梯度均减小,因此迭代后所有过程的模型参数均保持不变。
其他信息
有关更多信息,请参阅我们的技术报告。
(https://arxiv.org/abs/1906.07155).
原文链接:https://mmdetection.readthedocs.io/en/latest/TECHNICAL_DETAILS.html
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/05/06/mmdetection%e5%ae%98%e6%96%b9%e6%95%99%e7%a8%8b-%e6%8a%80%e6%9c%af%e7%bb%86%e8%8a%82-%e5%9b%9b/
