
作者|GUEST BLOG
编译|VK
来源|Analytics Vidhya
介绍
“事实是每个人都相信的简单陈述。也就是事实是没有错的,除非它被人发现了错误。假设有一个没人愿意相信的建议,那么它要直到被发现有效的时候才能成为事实。” –爱德华·泰勒
我们正在应对一场空前规模的流行病。全世界的研究人员都在疯狂地试图开发一种疫苗或COVID-19的治疗方法,而医生们正试图阻止这种流行病席卷整个世界。
我最近有了一个想法,把我的统计知识应用到这些大量COVID数据中。

考虑这样一个场景:医生有四种医疗方法来治疗病人。一旦我们有了测试结果,用最少时间治愈病人的治疗会是最好的方法。
但如果这些病人中的一些已经部分治愈,或者其他药物已经在治疗他们呢?
为了作出一个有信心和可靠的决定,我们需要证据来支持我们的做法。这就是方差分析的概念发挥作用的地方。
在本文中,我将向你介绍方差分析测试及其用于做出更好决策的不同类型。我将在Python中演示每种类型的ANOVA(方差分析)测试,以可视化它们并处理COVID-19数据。
注意:你必须了解统计学的基本知识才能理解这个主题。最好了解t检验和假设检验。
什么是方差分析测试(ANOVA)
方差分析,或称方差分析,可以看作是两组以上的t检验的推广。独立t检验用于比较两组之间的条件平均值。当我们想比较两组以上患者的病情平均值时,使用方差分析。
方差分析测试模型中某个地方的平均值是否存在差异(测试是否存在整体效应),但它不能告诉我们差异在哪里(如果存在)。为了找出两组之间的区别,我们必须进行事后检验。
要执行任何测试,我们首先需要定义原假设和替代假设:
- 零假设–各组之间无显着差异
- 替代假设–各组之间存在显着差异
基本上,方差分析是通过比较两种类型的变化来完成的,即样本均值之间的变化,以及每个样本内部的变化。以下公式表示单向Anova测试统计数据。
ANOVA公式的结果,即F统计量(也称为F比率),允许对多组数据进行分析,以确定样本之间和样本内部的可变性。
单向ANOVA的公式可以这样写:


当我们绘制ANOVA表时,上面的所有组成部分都可以如下所示:
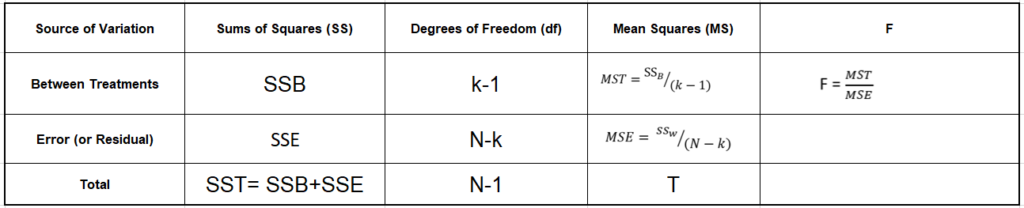
一般来说,如果与F相关联的p值小于0.05,则将拒绝原假设并支持替代假设。如果原假设被拒绝,我们可以得出结论,所有组的均值不相等。
注:如果被测组之间不存在真正的差异,也就是所谓的零假设,那么方差分析的F比统计结果将接近1。
ANOVA检验的假设
在进行方差分析之前,我们需要做一些假设:
- 从因子水平定义的总体中独立且随机地获得观察结果
- 每个因子水平的数据均呈正态分布
- 案例独立性:样本案例应相互独立
- 方差的同质性:同质性是指各组之间的方差应近似相等
方差同质性的假设可以用Levene检验或Brown-Forsythe检验来检验。分数分布的正态性可以用直方图、偏度和峰度值来检验,也可以用Shapiro-Wilk或Kolmogorov-Smirnov或Q-Q图来检验。独立性的假设可以根据研究设计来确定。
值得注意的是,方差分析对于假设独立性的违规行为并不强大。这就是说,即使你违反了同质性或正态性的假设,你也可以进行测试并基本相信结果。
但是,如果违反了独立性假设,方差分析的结果是无效的。一般来说,在违反同质性的情况下,如果具有相同大小的组,则分析被认为是可靠的。对于违反正态性的情况,如果样本量较大,继续进行方差分析通常是可以的。
方差分析检验类型
- 单向方差分析:单向方差分析只有一个自变量
- 例如,可以按国家/地区评估日冕案例的差异,并且一个国家可以将2个,20个或更多不同的类别进行比较
- 双向方差分析:双向方差分析(也称为因子方差分析)是指使用两个独立变量的方差分析
- 扩展上面的示例,双向方差分析可以按年龄组(独立变量1)和性别(独立变量2)检查日冕病例(因变量)的差异。双向方差分析可用于检查两个独立变量之间的相互作用。相互作用表明,自变量的所有类别之间的差异不是统一的
- 例如,老年组总体上可能比青年组具有更高的日冕病例,但是与欧洲国家相比,亚洲国家的差异可能更大(或更小)
- N向方差分析:一个研究者也可以使用两个以上的自变量,这是一个N向方差分析(N是你拥有的自变量的数量),也就是MANOVA检验。
- 例如,可以同时按国家、性别、年龄组、种族等检查日冕病例的潜在差异
- 方差分析会给你一个单变量的f值,而方差分析会给你一个多变量的f值
有复制与无复制
你可能经常听到关于方差分析的复制和不复制。让我们了解这些是什么:
- 具有复制功能的双向ANOVA:两个小组和这些小组的成员所做的不只是一件事情
- 例如,假设尚未开发出针对COVID-19的疫苗,医生正在尝试两种不同的治疗方法来治愈两组感染COVID-19的患者
- 双向ANOVA(无复制):只有一个组并且对同一组进行双重测试时使用
- 例如,假设已为COVID-19开发了一种疫苗,研究人员正在对一组志愿者进行疫苗接种之前和之后的测试,以查看其是否有效
事后检验
当我们进行方差分析时,我们试图确定各组之间是否存在统计学上的显著差异。如果我们发现存在差异,则需要检查组差异的位置。
基本上,事后检验告诉研究者哪些组彼此不同。
此时,你可以运行事后检验,这是t检验,用于检验组之间的均值差异。可以进行多个比较测试来控制I型错误率,包括Bonferroni、Scheffe、Dunnet和Tukey测试。
现在,让我们用一些真实的数据来理解每种类型的方差分析测试,并使用Python。
Python中的单向方差分析测试
我从一个正在进行的Kaggle竞赛中下载了这些数据:https://www.kaggle.com/sudalairajkumar/covid19-in-india
在此测试中,我们将尝试分析区域或状态的密度与日冕例数之间的关系。因此,我们将根据每个州的人口密度来映射每个州。
首先导入所有必需的库和数据:
import pandas as pd
import numpy as np
import scipy.stats as stats
import os
import random
import statsmodels.api as sm
import statsmodels.stats.multicomp
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
import matplotlib.pyplot as plt
from scipy import stats
import seaborn as sns
从目录加载数据:
StatewiseTestingDetails=pd.read_csv('./StatewiseTestingDetails.csv')
population_india_census2011=pd.read_csv('./population_india_census2011.csv')
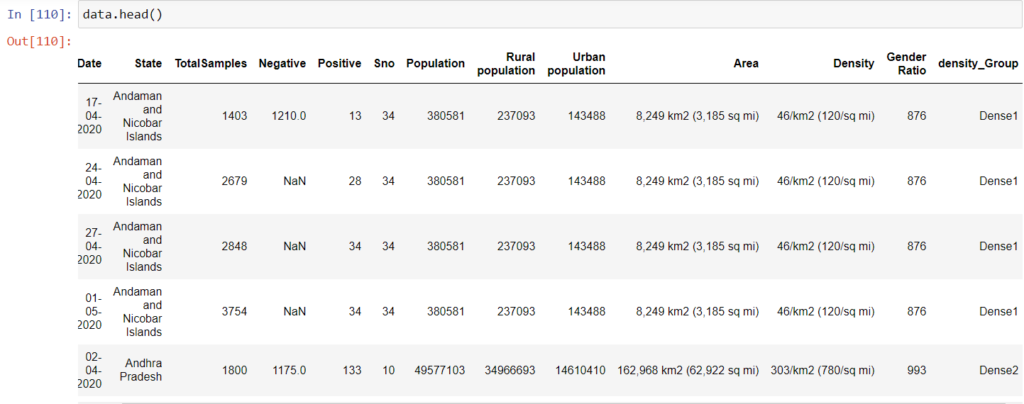
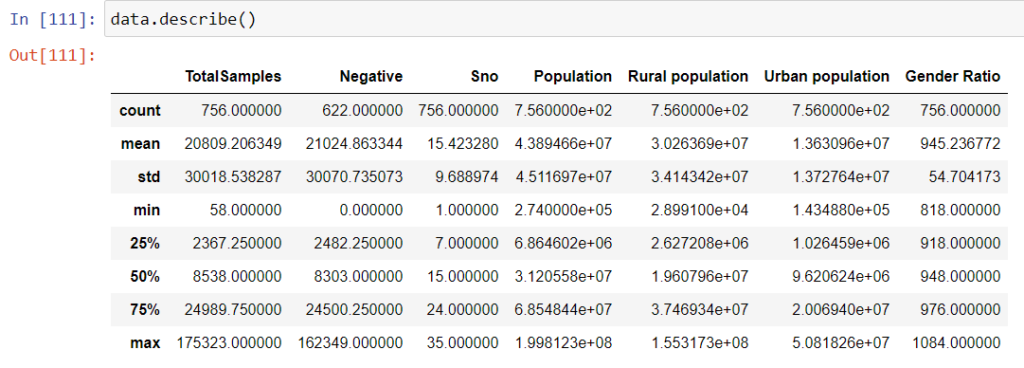
StatewiseTestingDetails包含有关每个州一天中阳性和阴性病例总数的信息。而human_india_census2011包含有关每个州的密度的信息以及有关人口的其他相关信息。
population_india_census2011.head()
StatewiseTestingDetails.head() #了解数据
StatewiseTestingDetails['Positive'].sort_values().head() #排序
从上面的代码片段中,我们可以看到有几个州在一天内有0个日冕案例或没有日冕案例。所以让我们看看这样的州:
StatewiseTestingDetails['State'][StatewiseTestingDetails['Positive']==1].unique()
我们看到,Nagaland和Sikkim在一天内也没有日冕病例。另一方面,Arunachal和Mizoram一天只有一个日冕病例。
估算缺失值:我们注意到“Positive”列中有许多缺失值。因此,让我们用每个州的Positive中值来估算这些缺失的值:
stateMedianData=StatewiseTestingDetails.groupby('State')[['Positive']].median().reset_index().rename(columns={'Positive':'Median'})
stateMedianData.head()
for index,row in StatewiseTestingDetails.iterrows():
if pd.isnull(row['Positive']):
StatewiseTestingDetails['Positive'][index]=int(stateMedianData['Median'][stateMedianData['State']==row['State']])
#合并StatewiseTestingDetails & population_india_census2011
data=pd.merge(StatewiseTestingDetails,population_india_census2011,on='State')
现在我们可以编写一个函数,根据每个州的密度创建一个密度组bucket,其中Dense1<Dense2<Dense3<Dense4:
def densityCheck(data):
data['density_Group']=0
for index,row in data.iterrows():
status=None
i=row['Density'].split('/')[0]
try:
if (',' in i):
i=int(i.split(',')[0]+i.split(',')[1])
elif ('.' in i):
i=round(float(i))
else:
i=int(i)
except ValueError as err:
pass
try:
if (0<i<=300):
status='Dense1'
elif (300<i<=600):
status='Dense2'
elif (600<i<=900):
status='Dense3'
else:
status='Dense4'
except ValueError as err:
pass
data['density_Group'].iloc[index]=status
return data
现在,用密度组映射每个州。我们可以导出这些数据,以便以后在双向方差分析测试中使用:
data=densityCheck(data)
#导出
stateDensity=data[['State','density_Group']].drop_duplicates().sort_values(by='State')
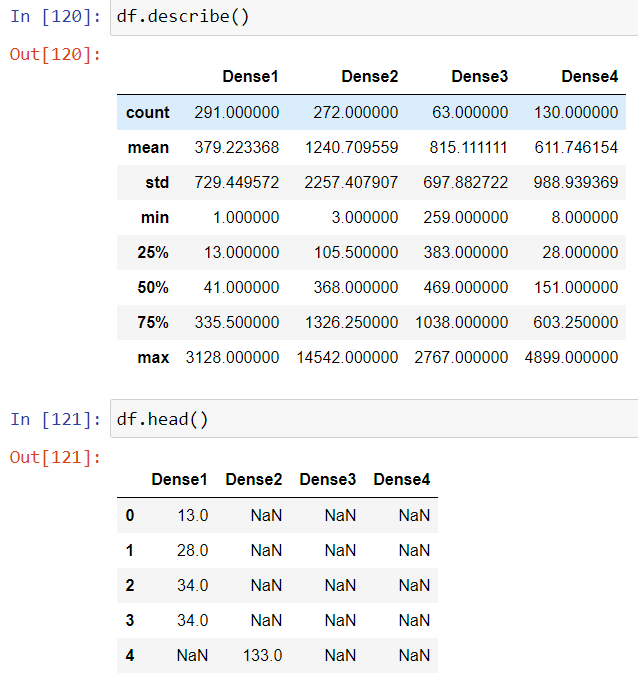
让我们对可以用于方差分析测试的数据集进行重新排列:
df=pd.DataFrame({'Dense1':data[data['density_Group']=='Dense1']['Positive'],
'Dense2':data[data['density_Group']=='Dense2']['Positive'],
'Dense3':data[data['density_Group']=='Dense3']['Positive'],
'Dense4':data[data['density_Group']=='Dense4']['Positive']})
我们的ANOVA检验假设之一是应随机选择样本,并且样本应接近高斯分布。因此,让我们从每个因子或水平中选择10个随机样本:
np.random.seed(1234)
dataNew=pd.DataFrame({'Dense1':random.sample(list(data['Positive'][data['density_Group']=='Dense1']), 10),
'Dense2':random.sample(list(data['Positive'][data['density_Group']=='Dense1']), 10),
'Dense3':random.sample(list(data['Positive'][data['density_Group']=='Dense1']), 10),
'Dense4':random.sample(list(data['Positive'][data['density_Group']=='Dense1']), 10)})
让我们绘制日冕案例数量的密度分布图,以检查它们在不同密度组中的分布:
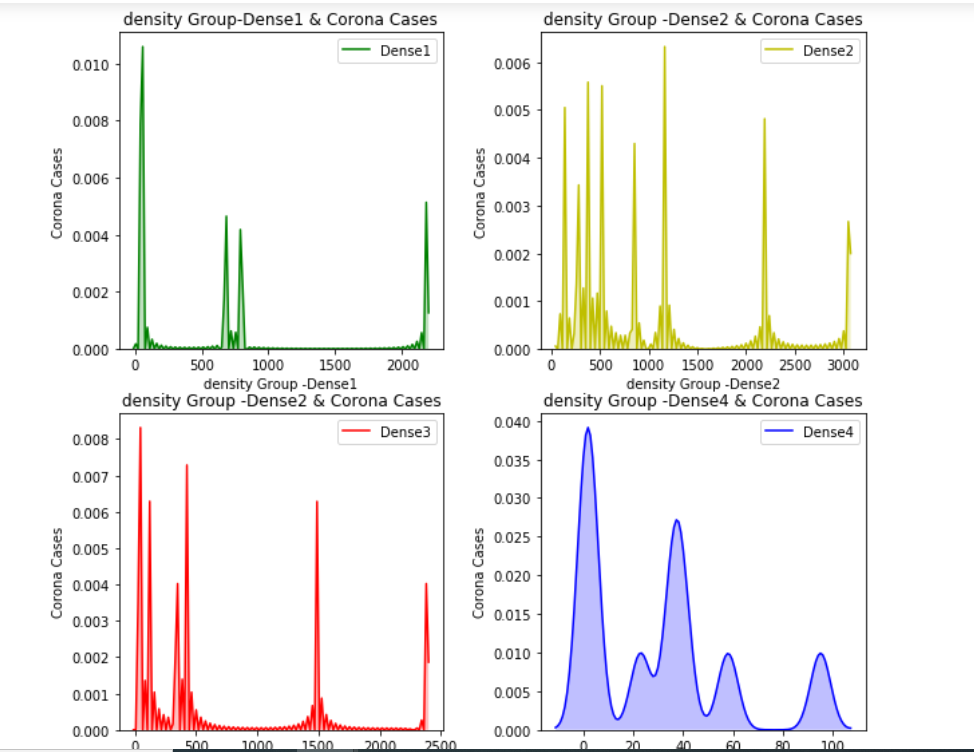
我们可以清楚地看到数据不遵循高斯分布。
有不同的数据转换方法可以使数据接近高斯分布。我们进行Box-Cox变换:
dataNew['Dense1'],fitted_lambda = stats.boxcox(dataNew['Dense1'])
dataNew['Dense2'],fitted_lambda = stats.boxcox(dataNew['Dense2'])
dataNew['Dense3'],fitted_lambda = stats.boxcox(dataNew['Dense3'])
dataNew['Dense4'],fitted_lambda = stats.boxcox(dataNew['Dense4'])
现在让我们再次绘制它们的分布图来检查:

方法1:使用statsmodels模块进行单向方差分析
Python中有两种方法可以执行ANOVA测试。一个是stats.f_oneway()方法:
F, p = stats.f_oneway(dataNew['Dense1'],dataNew['Dense2'],dataNew['Dense3'],dataNew['Dense4'])
## 看看整体模型是否重要
print('F-Statistic=%.3f, p=%.3f' % (F, p))
我们发现p值<0.05。因此,我们可以拒绝零假设——不同密度组之间没有差异。
方法2:用OLS模型进行单因素方差分析
正如我们在回归中所知道的,我们可以对每个输入变量进行回归,并检查其对目标变量的影响。所以,我们将遵循同样的方法,我们在线性回归中遵循的方法。
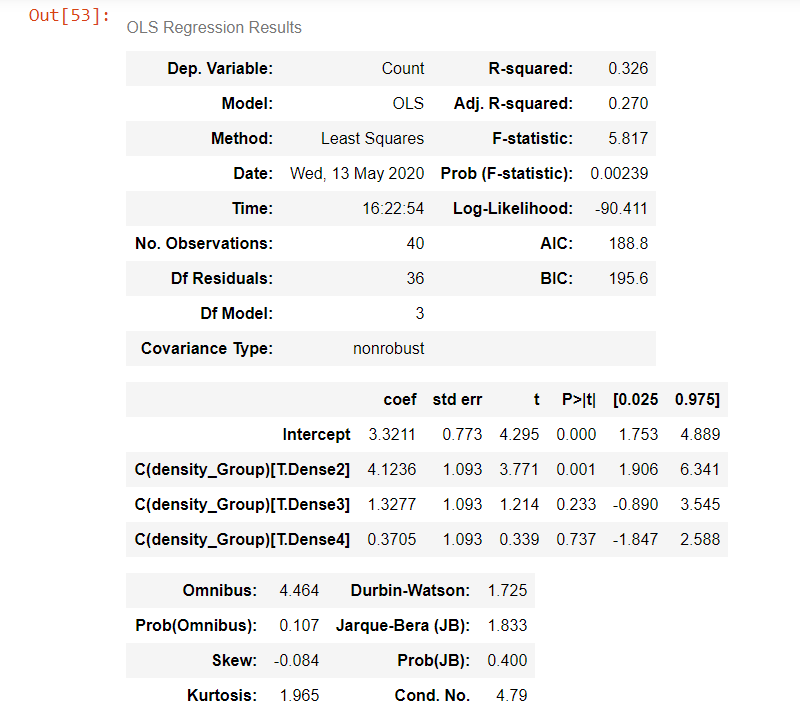
model = ols('Count ~ C(density_Group)', newDf).fit()
model.summary()
## 看看整体模型是否重要
print(f"Overall model F({model.df_model: .0f},{model.df_resid: .0f}) = {model.fvalue: .3f}, p = {model.f_pvalue: .4f}")
#创建方差分析表
res = sm.stats.anova_lm(model, typ= 2)
res
从以上输出结果可以看出,p值小于0.05。因此,我们可以拒绝不同密度组之间没有差异的零假设。
F-statistic= 5.817,p-value= 0.002,这表明density_Group对日冕阳性病例有总体显着影响。但是,我们尚不知道desnity_groups之间的区别在哪里。因此,基于p值,我们可以拒绝H0;就面积密度和日冕例数而言,没有显着差异。
事后比较检验
当我们进行方差分析时,我们试图确定各组之间是否存在统计学上的显着差异。那么,如果我们发现统计学意义呢?
如果发现存在差异,则需要检查组差异的位置。因此,我们将使用Tukey HSD测试来确定差异所在:
mc = statsmodels.stats.multicomp.MultiComparison(newDf['Count'],newDf['density_Group'])
mc_results = mc.tukeyhsd()
print(mc_results)
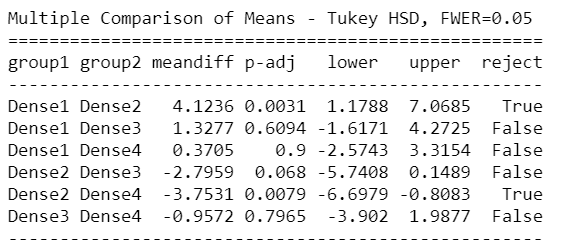
Tuckey HSD测试清楚地表明,Group1 – Group3,Group1 – Group4,Group2 – Group3和Group3 – Group4之间存在显着差异。
这表明,除上述两组外,所有其他日冕病例数的成对比较均拒绝零假设,且无统计学显著性差异。
假设检验/模型诊断
正态分布假设检验
当使用线性回归和方差分析模型时,假设与残差有关,而不是变量本身。
方法1:Shapiro-Wilk试验:
### 正态性假设检查
w, pvalue = stats.shapiro(model.resid)
print(w, pvalue)
从上面的代码片段中,我们看到所有密度组的p值都大于0.05。因此,我们可以得出结论,它们遵循高斯分布。
方法2:Q-Q图试验:
我们可以使用Q-Q图来检验这个假设:
res = model.resid
fig = sm.qqplot(res, line='s')
plt.show()
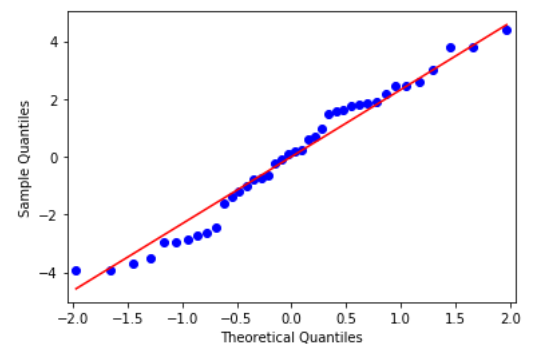
从上图中,我们看到所有数据点都靠近45度线,因此我们可以得出结论,它遵循正态分布。
方差假设检验的同质性检查
应针对分类变量的每个级别检查方差假设的同质性。我们可以使用Levene检验来检验组之间的均等方差。
w, pvalue = stats.bartlett(newDf['Count'][newDf['density_Group']=='Dense1'], newDf['Count'][newDf['density_Group']=='Dense2']
, newDf['Count'][newDf['density_Group']=='Dense3'], newDf['Count'][newDf['density_Group']=='Dense4'])
print(w, pvalue)
## Levene 方差测试
stats.levene(dataNew['Dense1'],dataNew['Dense2'],dataNew['Dense3'],dataNew['Dense4'])
我们发现所有密度组的p值都大于0.05。因此,我们可以得出结论,各组具有相等的方差。
Python中的双向方差分析测试
同样,使用相同的数据集,我们将试图了解一个地区或州的密度、人口年龄和日冕病例数量之间是否存在显著关系。因此,我们将根据居住在其中的人口密度绘制每个州的地图。
让我们导入数据并检查是否存在任何数据歧义:
individualDetails=pd.read_csv('./individualDetails.csv',parse_dates=[2])
stateDensity=pd.read_csv('./stateDensity.csv')
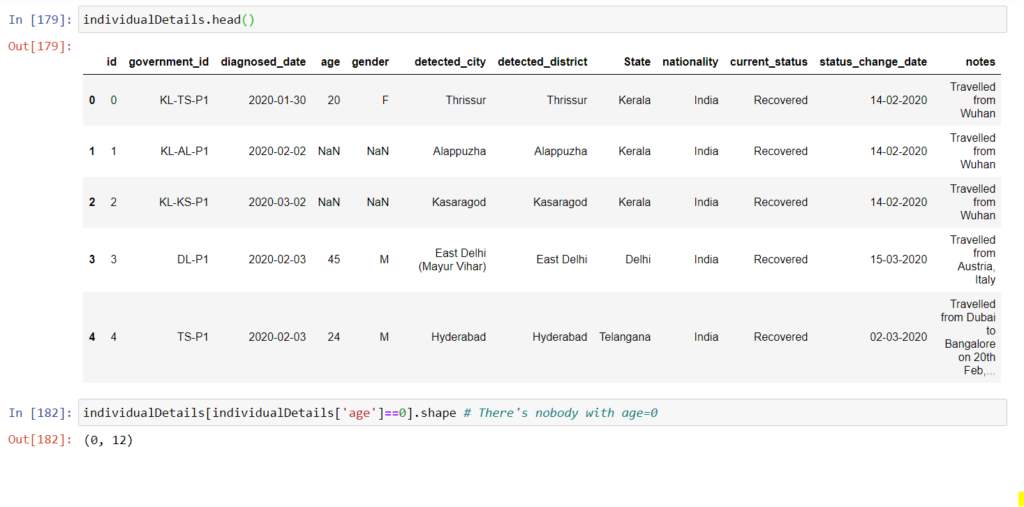
从上面的代码片段中,我们可以看到没有感染婴儿的记录。接下来,检查数据中是否缺少值:
individualDetails.isna().sum()
print('Percentage of missing values in age & gender columns respectively :',
(individualDetails['age'].isna().sum()/individualDetails.shape[0])*100,'%',
(individualDetails['gender'].isna().sum()/individualDetails.shape[0])*100,'%')
我们发现在年龄和性别栏中分别有超过91%和80%的条目丢失。所以我们需要设计一种方法来估算它们。
在这里,我将以各州的性别中位数和各州的性别中位数估算年龄。因此,我将计算中位数和众数:
ageMedianPerState=individualDetails[~individualDetails['age'].isna()]
ageMedianPerState['age']=ageMedianPerState['age'].astype(str).astype(int)
ageMedianPerState=ageMedianPerState.groupby('State')[['age']].median().reset_index()
ageMedianPerState['age']=ageMedianPerState['age'].apply(lambda x:math.ceil(x))
#通过COVID-19查找每个州的最常感染的性别
genderModePerState=individualDetails.groupby(['State'])['gender'].agg(pd.Series.mode).to_frame().reset_index()
#这没有获得有关总体性别的信息性别
genderModePerState=genderModePerState[genderModePerState['State']!='Arunachal Pradesh']
#现在在年龄和性别栏填充丢失的值
for index,row in individualDetails.iterrows():
if row['State']=='Arunachal Pradesh':
individualDetails.drop([index],inplace=True)
continue
if pd.isnull(row['age']):
individualDetails['age'][index]=list(ageMedianPerState['age'][ageMedianPerState['State']=='West Bengal'].values)[0]
if pd.isnull(row['gender']):
if len(genderModePerState['gender'][genderModePerState['State']==row['State']].values)>0:
individualDetails['gender'][index]=(genderModePerState['gender'][genderModePerState['State']==row['State']].values[0])
现在,让我们合并individualDetails和stateDensity数据帧,为我们创建一个整体数据集:
data = pd.merge(individualDetails,stateDensity,on='State',how='left').reset_index(drop=True)
现在我们可以创建年龄组桶:
data.dropna(subset=['density_Group'],inplace=True)
data.reset_index(drop=True,inplace=True)
合并数据以获得一个数据集,其中每个人都映射了他们的年龄组和各自的州密度组:
patient_Count=data.groupby(['diagnosed_date','density_Group'])[['diagnosed_date']].count().
rename(columns={'diagnosed_date':'Count'}).reset_index()
data=pd.merge(data,patient_Count,on=['diagnosed_date','density_Group'],how='inner')
newData=data.groupby(['density_Group','age_Group'])['Count'].apply(list).reset_index()
newData.head()
np.random.seed(1234)
AnovaData=pd.DataFrame(columns=['density_Group','age_Group','Count'])
for index,row in newData.iterrows():
count=17
tempDf=pd.DataFrame(index=range(0,count),columns=['density_Group','age_Group','Count'])
tempDf['age_Group']=newData['age_Group'][index]
tempDf['density_Group']=newData['density_Group'][index]
tempDf['Count']=random.sample(list(newData['Count'][index]),count)
AnovaData=pd.concat([AnovaData,tempDf],axis=0)
检查数据中Count列的分布,并使用箱线图方法检查数据中是否存在异常值:
plt.hist(AnovaData['Count'])
plt.show() sns.kdeplot(AnovaData['Count'],cumulative=False,bw=2)
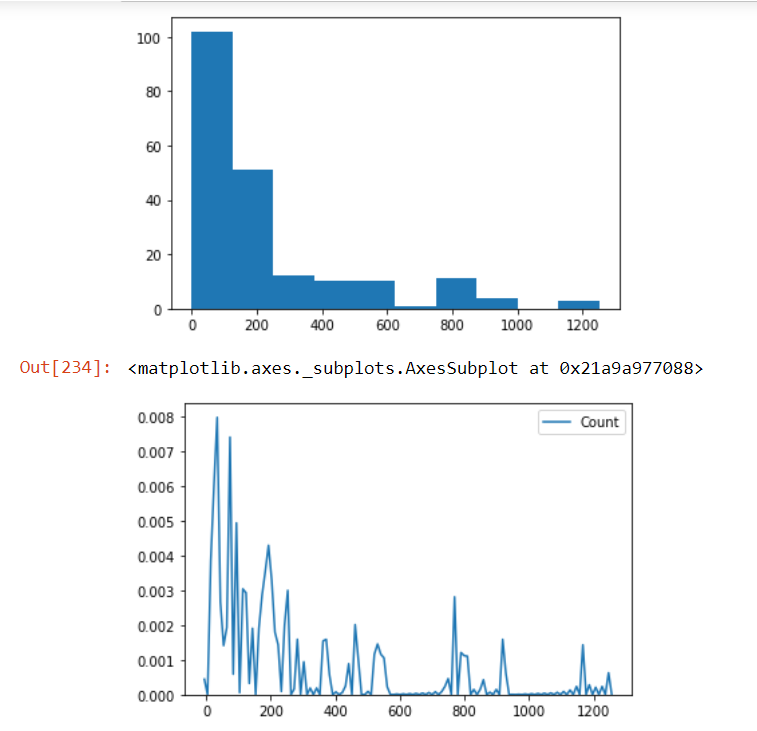
我们发现在我们的数据中有许多异常值。甚至计数变量的分布也不是高斯分布。因此,我们将使用Box-Cox变换方法来处理这种情况:
sns.boxplot(x='age_Group', y='Count',
data=AnovaData,
palette="colorblind")
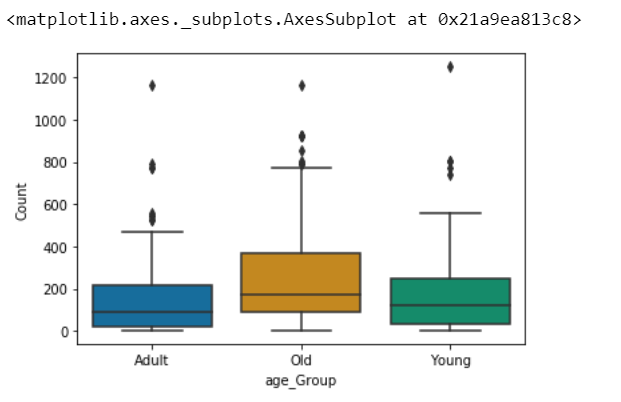
AnovaData['Count']=AnovaData['Count'].astype(int)
## 数据转换
AnovaData['newCount'],fitted_lambda = stats.boxcox(AnovaData['Count'])
import matplotlib.pyplot as plt
sns.kdeplot(AnovaData['newCount'],cumulative=False,bw=2)
现在让我们使用OLS模型来检验我们的假设:
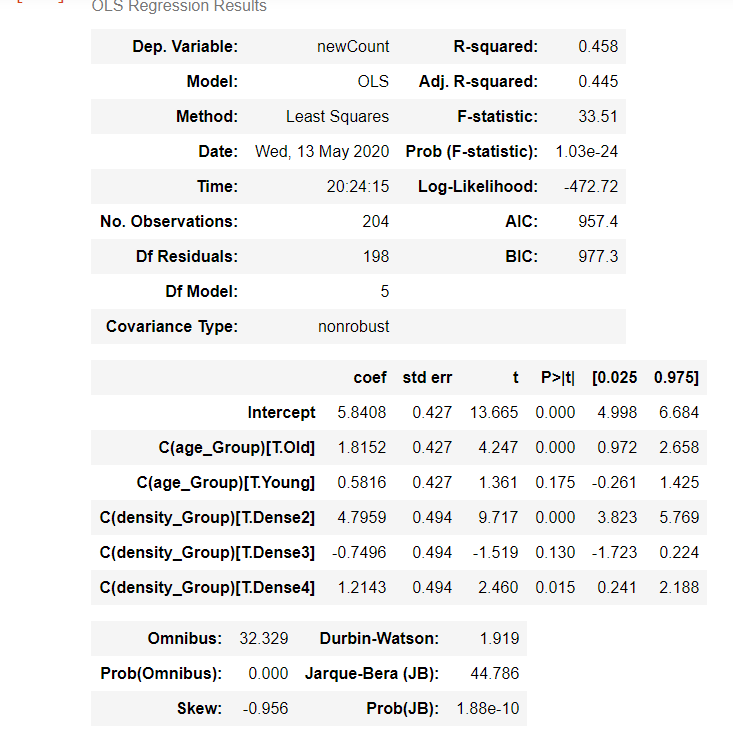
## 拟合OlS模型-方法1
model2 = ols('newCount ~ C(age_Group)+ C(density_Group)', AnovaData).fit()
print(f"Overall model F({model2.df_model: },{model2.df_resid: }) = {model2.fvalue: }, p = {model2.f_pvalue: }")
model2.summary()
## 创建方差分析表
res2 = sm.stats.anova_lm(model2, typ=2)
res2
#检验残差的正态分布
res = model2.resid
fig = sm.qqplot(res, line='s')
plt.show()
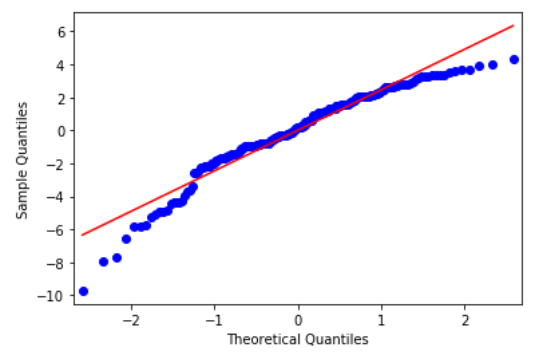
从上面的Q-Q图,我们可以看到残差几乎是正态分布的(尽管在最末端的点可以被贴现)。因此,我们可以得出结论,它满足方差分析检验的正态性假设。
#方法2-检查组之间的交互
formula = 'newCount ~ C(age_Group) *C(density_Group)'
model = ols(formula, AnovaData).fit()
model.summary()
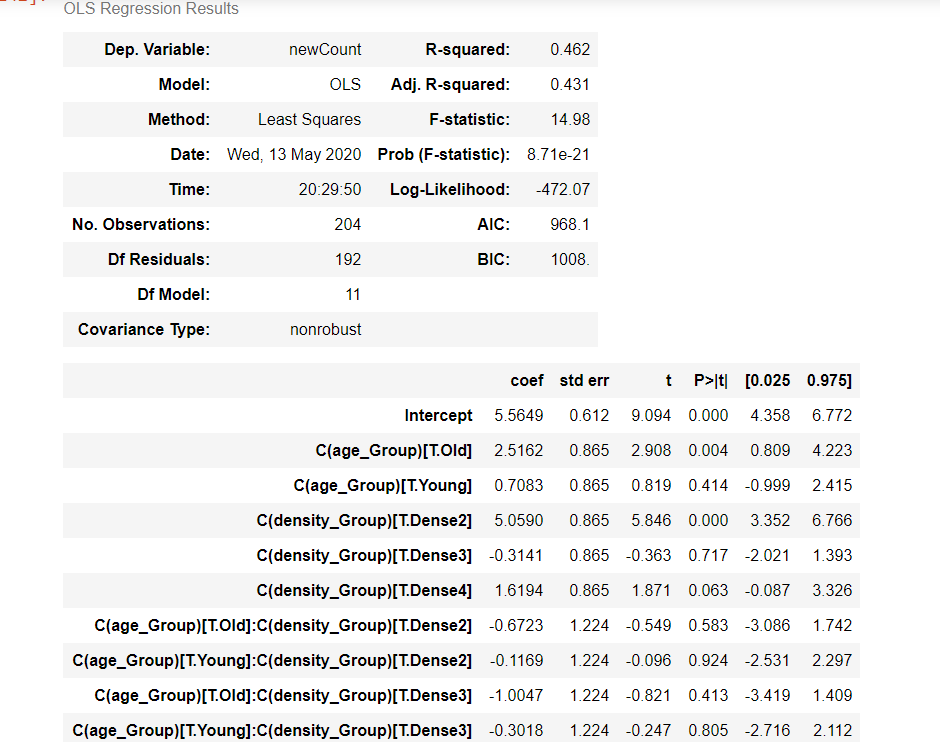
aov_table = anova_lm(model, typ=2)
print(aov_table.round(4))
结果的解释
通过ANOVA分析获得的日冕病例数,年龄组和密度组以及相互作用的P值具有统计学意义(P <0.05)。我们得出结论,density_Group的类型显着影响日冕的结果。
age_Group显着影响日冕病例的结果,age_Group和density_Group的相互作用也显着影响日冕病例的结果。
事后检验
最后,让我们确定哪些组在统计上是不同的。我们将使用Tuckey HSD方法:
mc = statsmodels.stats.multicomp.MultiComparison(AnovaData['newCount'],AnovaData['density_Group'])
mc_results = mc.tukeyhsd()
print(mc_results)
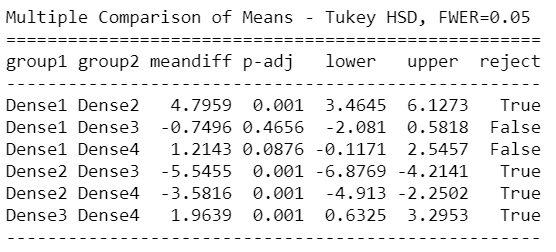
mc = statsmodels.stats.multicomp.MultiComparison(AnovaData['newCount'],AnovaData['age_Group'])
mc_results = mc.tukeyhsd()
print(mc_results)

从上面的Tuckey HSD测试结果中,我们可以清楚地看到,密度组中的Group1 – Group3,Group1 – Group4与年龄组中的Young – Adult&Young –old组之间也存在显着差异。
因此,Tukey HSD的上述结果表明,除上述组外,日冕病例数的所有其他成对比较均拒绝了原假设,并且表明没有统计学上的显着差异。
结尾
在病毒大流行时期,我试着用一个相关的案例来解释方差分析。你可以克隆我的Github存储库来下载全部代码和数据:https://github.com/Praveen76/ANOVA-Test-COVID-19
原文链接:https://www.analyticsvidhya.com/blog/2020/06/introduction-anova-statistics-data-science-covid-python/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/06/25/%e6%96%b9%e5%b7%ae%e5%88%86%e6%9e%90%e4%bb%8b%e7%bb%8d%e7%bb%93%e5%90%88covid-19%e6%a1%88%e4%be%8b/
