
作者|PRATEEK JOSHI
编译|VK
来源|Analytics Vidhya
介绍
机器学习框架或库有时会更改该领域的格局。今天,Facebook开源了一个这样的框架,DETR(DEtection TRansformer)

在本文中,我们将快速了解目标检测的概念,然后直接研究DETR及其带来的好处。
目标检测
在计算机视觉中,目标检测是一项任务,我们希望我们的模型将对象与背景区分开,并预测图像中存在的对象的位置和类别。当前的深度学习方法试图解决作为分类问题或回归问题或综合两者的目标检测任务。
例如,在RCNN算法中,从输入图像中识别出几个感兴趣的区域。然后将这些区域分类为对象或背景,最后,使用回归模型为所标识的对象生成边界框。
另一方面,YOLO框架(只看一次)以不同的方式处理目标检测。它在单个实例中获取整个图像,并预测这些框的边界框坐标和类概率。
要了解有关目标检测的更多信息,请参阅以下文章:
-
基本目标检测算法的分步介绍
-
使用流行的YOLO框架进行目标检测的实用指南
Facebook AI引入DETR
如上一节所述,当前的深度学习算法以多步方式执行目标检测。他们还遭受了几乎重复的问题,即误报。为简化起见,Facebook AI的研究人员提出了DETR,这是一种解决物体检测问题的创新高效方法。
论文:https://arxiv.org/pdf/2005.12872.pdf
开放源代码:https://github.com/facebookresearch/detr
Colab Notebook:https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_demo.ipynb
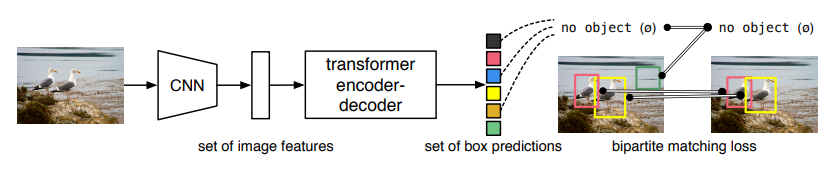
这个新模型非常简单,你无需安装任何库即可使用它。DETR借助基于Transformer的编码器-解码器体系结构将目标检测问题视为集合预测问题。所谓集合,是指边界框的集合。Transformer是在NLP领域中表现出色的新型深度学习模型。
本文的作者已经对比了Faster R-CNN,并且在最流行的物体检测数据集之一COCO上评估了DETR 。
结果,DETR取得了可比的性能。更准确地说,DETR在大型物体上表现出明显更好的性能。但是,它在小型物体上的效果不佳。我相信研究人员很快就会解决这个问题。
DETR的体系结构
实际上,整个DETR架构很容易理解。它包含三个主要组件:
- CNN骨干网
- 编码器-解码器transformer
- 一个简单的前馈网络
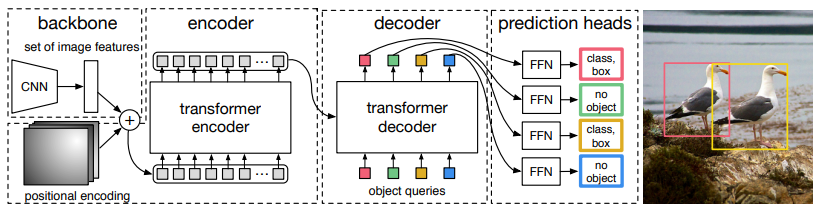
首先,CNN骨干网从输入图像生成特征图。
然后,将CNN骨干网的输出转换为一维特征图,并将其作为输入传递到Transformer编码器。该编码器的输出是N个固定长度的嵌入(向量),其中N是模型假设的图像中的对象数。
Transformer解码器借助自身和编码器-解码器注意机制将这些嵌入解码为边界框坐标。
最后,前馈神经网络预测边界框的标准化中心坐标,高度和宽度,而线性层使用softmax函数预测类别标签。
想法
对于所有深度学习和计算机视觉爱好者来说,这是一个非常令人兴奋的框架。非常感谢Facebook与社区分享其方法。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/08/30/facebook-ai%e7%9a%84detr%ef%bc%8c%e4%b8%80%e7%a7%8d%e5%9f%ba%e4%ba%8etransformer%e7%9a%84%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b%e6%96%b9%e6%b3%95-2/
