
作者|Aparna Dhinakaran
编译|Flin
来源|towardsdatascience

部署健壮的、可扩展的机器学习解决方案仍然是一个非常复杂的过程,需要大量的人力参与,并做出很多努力。因此,新产品和服务需要很长时间才能上市,或者在原型状态下就被放弃,从而降低了行业内的对它的兴趣。那么,我们如何才能促进将机器学习模型投入生产的过程呢?
Cortex是一个将机器学习模型部署为生产网络服务的开源平台。它利用强大的AWS生态系统,根据需要部署、监视和扩展与框架无关的模型。其主要特点概括如下:
-
框架无关:Cortex支持任何python代码;与其他python脚本一样,TensorFlow、PyTorch、scikit-learn、XGBoost都是由该库支持的。
-
自动缩放:Cortex自动缩放你的api,以处理生产负载。
-
CPU / GPU支持:使用AWS IaaS作为底层基础架构,Cortex可以在CPU或GPU环境下运行。
-
Spot实例:Cortex支持EC2 Spot实例来降低成本。
-
滚动更新:Cortex对模型应用任何更新,没有任何停机时间。
-
日志流:Cortex使用类似docker的语法将部署模型中的日志保存下来,并将其流式传输到CLI。
-
预测监测:Cortex监测网络指标并跟踪预测。
-
最小配置:Cortex部署配置被定义为一个简单的YAML文件。
在本文中,我们使用Cortex将一个图像分类模型作为web服务部署到AWS上。那么,言归正传,让我们来介绍一下Cortex。
将模型部署为Web服务
在这个例子中,我们使用fast.ai库(https://pypi.org/project/fastai/) ,并从相关MOOC的第一个课程中(https://course.fast.ai/) 借用pets分类模型。以下各节介绍了Cortex的安装和pets分类模型作为web服务的部署。
安装
如果还没有安装,首先应该在AWS上创建一个具有编程访问权限的新用户帐户。为此,请选择IAM服务,然后从右侧面板中选择Users,最后按Add User按钮。为用户指定一个名称并选择Programmatic access。
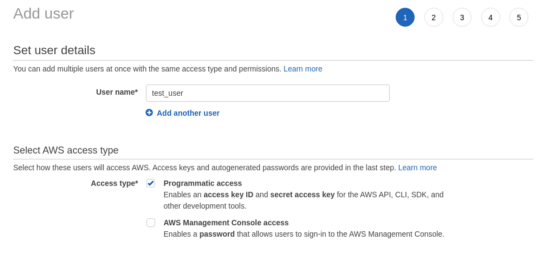
接下来,在Permissions 屏幕中,选择Attach existing policies directly选项卡,然后选择AdministratorAccess。
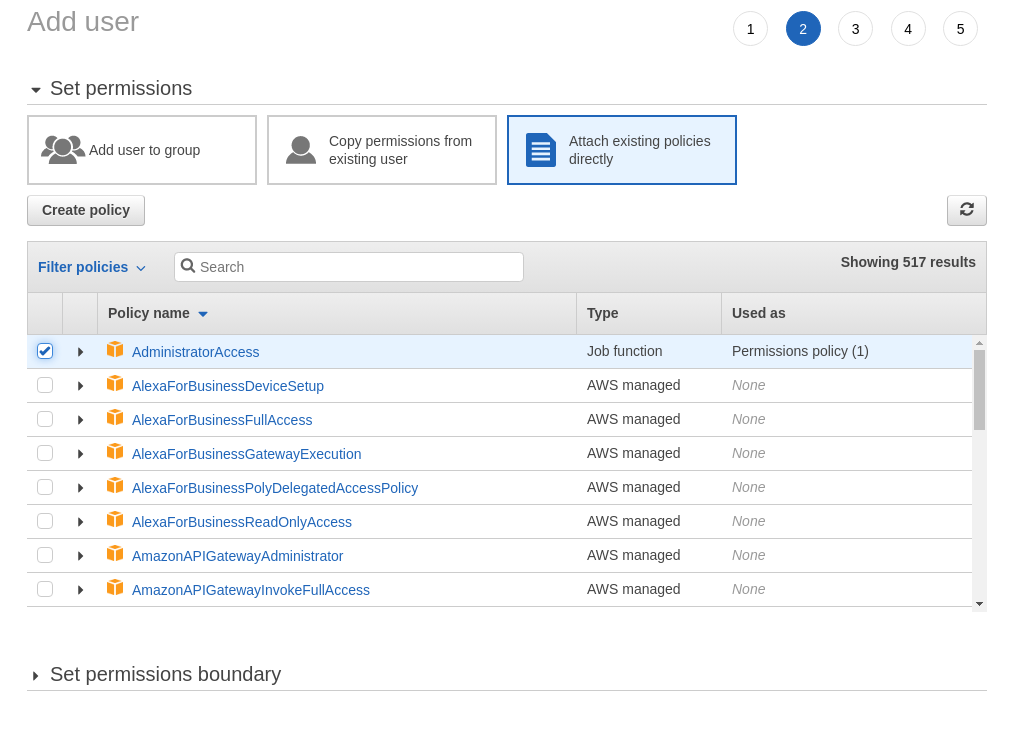
你可以将标记页留空,查看并创建用户。最后,注意访问密钥ID和密钥访问密钥。
在AWS控制台上,你还可以创建一个S3 bucket来存储经过训练的模型和代码可能生成的任何其他人工制品。你可以随意命名这个bucket,只要它是一个唯一的名字。在这里,我们创建了一个名为cortex-pets-model的bucket。
下一步,我们必须在系统上安装Cortex CLI并启动Kubernetes集群。要安装Cortex CLI,请运行以下命令:
bash -c “$(curl -sS https://raw.githubusercontent.com/cortexlabs/cortex/0.14/get-cli.sh)"通过访问相应的文档部分(https://www.cortex.dev/) ,检查你是否正在安装最新版本的Cortex CLI。
我们现在准备建立集群。使用Cortex创建Kubernetes集群是很简单的。只需执行以下命令:
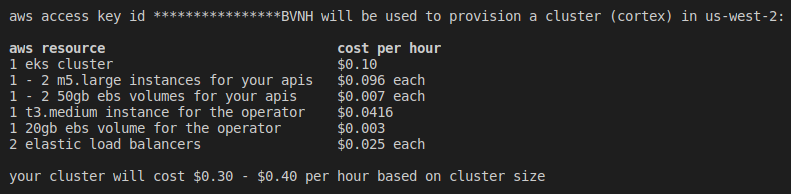
cortex cluster upCortex会要求你提供一些信息,比如你的AWS密钥、你想使用的区域、你想启动的计算实例以及它们的数量。Cortex也会让你知道你会花多少钱来使用你选择的服务。整个过程可能需要20分钟。
训练你的模型
Cortex并不关心你如何创建或训练你的模型。在本例中,我们使用fast.ai库和Oxford IIIT Pet数据集。这个数据集包含37种不同的狗和猫。因此,我们的模型应该将每个图像分为这37类。
创建一个类似下面的trainer.py文件
import boto3
import pickle
from fastai.vision import *
# initialize boto session
session = boto3.Session(
aws_access_key_id=<your_accress_key_id>,
aws_secret_access_key='<your_secret_access_key>',
)
# get the data
path = untar_data(URLs.PETS, dest='sample_data')
path_img = path/'images'
fnames = get_image_files(path_img)
# process the data
bs = 64
pat = r'/([^/]+)_\d+.jpg$'
data = ImageDataBunch.from_name_re(path_img, fnames, pat,
ds_tfms=get_transforms(), size=224, bs=bs) \
.normalize(imagenet_stats)
# create, fit and save the model
learn = cnn_learner(data, models.resnet18, metrics=accuracy)
learn.fit_one_cycle(4)
with open('model.pkl', 'wb') as handle:
pickle.dump(learn.model, handle)
# upload the model to s3
s3 = session.client('s3')
s3.upload_file('model.pkl', 'cortex-pets-model', 'model.pkl')与其他python脚本一样,在本地运行该脚本:python trainer.py
但是,请确保提供你的AWS凭据和S3 bucket名称。这个脚本获取数据,处理它们,适合一个预先训练好的ResNet模型并将其上传到S3。当然,你可以使用几种技术(更复杂的体系结构、有区别的学习率、面向更多时代的训练)来扩展此脚本以使模型更精确,但是这与我们的目标无关。如果你想进一步了解ResNet体系结构,请参阅下面的文章。
https://towardsdatascience.com/xresnet-from-scratch-in-pytorch-e64e309af722
部署模型
现在我们已经训练了模型并将其存储在S3中,下一步是将其作为web服务部署到生产环境中。为此,我们创建了一个名为predictor.py的python脚本,像下图:
import torch
import boto3
import pickle
import requests
from PIL import Image
from io import BytesIO
from torchvision import transforms
# initialize boto session
session = boto3.Session(
aws_access_key_id='<your_access_key_id>',
aws_secret_access_key='<your_secret_access_key>',
)
# define the predictor
class PythonPredictor:
def __init__(self, config):
s3 = session.client('s3')
s3.download_file(config['bucket'], config['key'], 'model.pkl')
self.model = pickle.load(open('model.pkl', 'rb'))
self.model.eval()
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.preprocess = transforms.Compose(
[transforms.Resize(224), transforms.ToTensor(), normalize]
)
self.labels = ['Abyssinian', 'Bengal', 'Birman', 'Bombay', 'British_Shorthair',
'Egyptian_Mau', 'Maine_Coon', 'Persian', 'Ragdoll', 'Russian_Blue',
'Siamese', 'Sphynx', 'american_bulldog', 'american_pit_bull_terrier',
'basset_hound', 'beagle', 'boxer', 'chihuahua', 'english_cocker_spaniel',
'english_setter', 'german_shorthaired', 'great_pyrenees', 'havanese',
'japanese_chin', 'keeshond', 'leonberger', 'miniature_pinscher', 'newfoundland',
'pomeranian', 'pug', 'saint_bernard', 'samoyed', 'scottish_terrier', 'shiba_inu',
'staffordshire_bull_terrier', 'wheaten_terrier', 'yorkshire_terrier']
self.device = config['device']
def predict(self, payload):
image = requests.get(payload["url"]).content
img_pil = Image.open(BytesIO(image))
img_tensor = self.preprocess(img_pil)
img_tensor.unsqueeze_(0)
img_tensor = img_tensor.to(self.device)
with torch.no_grad():
prediction = self.model(img_tensor)
_, index = prediction[0].max(0)
return self.labels[index]这个文件定义了一个预测器类。在实例化它时,它从S3中检索模型,将其加载到内存中,并定义一些必要的转换和参数。在推理期间,它从给定的URL中读取图像并返回预测的类的名称。一个用于初始化的方法__init__和一个用于接收有效负载并返回结果的预测方法predict。
预测器脚本有两个附带的文件。一个记录库依赖项的requirements.txt文件(如pytorch、fastai、boto3等)和一个YAML配置文件。最小配置如下:
- name: pets-classifier
predictor:
type: python
path: predictor.py
config:
bucket: cortex-pets-model
key: model.pkl
device: cpu 在这个YAML文件中,我们定义了运行哪个脚本进行推理,在哪个设备(例如CPU)上运行,以及在哪里找到训练好的模型。文档中提供了更多的选项。
最后,项目的结构应该遵循下面的层次结构。请注意,这是最低限度的要求,但是如果你有一个可以部署的模型,那么你可以提交train .py。
- Project name
|----trainer.py
|----predictor.py
|----requirements.txt
|----cortex.yaml有了所有这些,你只需运行cortex deploy,几秒钟之内,你的新端点就可以接受请求了。执行corted get pets-classifier来监视端点并查看其他详细信息。
status up-to-date requested last update avg request 2XX
live 1 1 13m - -
endpoint: http://a984d095c6d3a11ea83cc0acfc96419b-1937254434.us-west-2.elb.amazonaws.com/pets-classifier
curl: curl http://a984d095c6d3a11ea83cc0acfc96419b-1937254434.us-west-2.elb.amazonaws.com/pets-classifier?debug=true -X POST -H "Content-Type: application/json" -d @sample.json
configuration
name: pets-classifier
endpoint: /pets-classifier
predictor:
type: python
path: predictor.py
config:
bucket: cortex-pets-model
device: cpu
key: model.pkl
compute:
cpu: 200m
autoscaling:
min_replicas: 1
max_replicas: 100
init_replicas: 1
workers_per_replica: 1
threads_per_worker: 1
target_replica_concurrency: 1.0
max_replica_concurrency: 1024
window: 1m0s
downscale_stabilization_period: 5m0s
upscale_stabilization_period: 0s
max_downscale_factor: 0.5
max_upscale_factor: 10.0
downscale_tolerance: 0.1
upscale_tolerance: 0.1
update_strategy:
max_surge: 25%
max_unavailable: 25%剩下的就是用curl和pomeranian的图像来测试它:
curl http://a984d095c6d3a11ea83cc0acfc96419b-1937254434.us-west-2.elb.amazonaws.com/pets-classifier -X POST -H "Content-Type: application/json" -d '{"url": "https://i.imgur.com/HPRQ28l.jpeg"}'释放资源
当我们完成服务和集群时,我们应该释放资源以避免额外的成本。Cortex很容易做到:
cortex delete pets-classifier
cortex cluster down结论
在这篇文章中,我们看到了如何使用Cortex,一个开源平台,来将机器学习模型部署为生产web服务。我们训练了一个图像分类器,将其部署到AWS上,监控其性能并进行测试。
有关更高级的概念,如预测监视、滚动更新、集群配置、自动缩放等,请访问官方文档站点(https://www.cortex.dev/) 和项目的GitHub页面(https://github.com/cortexlabs/cortex)。
原文链接:https://towardsdatascience.com/deploy-monitor-and-scale-machine-learning-models-on-aws-408dfd397422
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/09/01/%e5%9c%a8aws%e4%b8%8a%e9%83%a8%e7%bd%b2%e3%80%81%e7%9b%91%e6%8e%a7%e5%92%8c%e6%89%a9%e5%b1%95%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a0%e6%a8%a1%e5%9e%8b/
