
作者|Maria Malitckaya
编译|VK
来源|Towards Data Science
改进机器学习模型的一个有效方法是使用词嵌入。使用词嵌入,你可以捕获文档中单词的上下文,然后找到语义和语法上的相似之处。
在这篇文章中,我们将讨论词嵌入技术的一个不寻常的应用。我们将尝试使用OpenAPI的规范作为数据集在其中找到最好的词嵌入技术。作为OpenAPI规范的一个例子,我们将使用OpenAPI specifications(https://swagger.io/specification/)提供的OpenAPI规范数据集。
最大的挑战是,OpenAPI规范既不是自然语言,也不是代码。但这也意味着我们可以自由使用任何可用的嵌入模型。在这个实验中,我们将研究三种可能可行的候选方案:code2vec、glow和spaCy。
code2vec是一个神经模型,可以学习与源代码相关的类比。该模型是在Java代码数据库上训练的,但是你可以将其应用于任何代码。
还有GloVe。GloVe是一种常用的自然语言处理算法。它是在维基百科和Gigawords上训练的。
最后,我们有了spaCy。虽然spaCy是最近才发展起来的,但该算法已经以世界上最快的词嵌入而闻名。
让我们看看这些算法中哪一种更适合OpenAPI数据集,哪种算法对于OpenAPI规范的运行速度更快. 我把这篇文章分为六个部分,每个部分都包含代码示例和一些将来使用的提示,外加一个结论。
-
下载数据集
-
下载词汇表
-
提取字段名称
-
标识化
-
创建字段名称的数据集
-
测试嵌入
-
结论
现在,我们可以开始了。
1.下载数据集
首先,我们需要下载整个apis-guru数据库:https://apis.guru/。
你会注意到,大多数apis-guru规范都是Swagger 2.0格式。但是,OpenAPI规范的最新版本是OpenAPI 3.0。
因此,让我们使用Unmock脚本将整个数据集转换为这种格式!你可以按照Unmock openapi脚本的README文件中的说明完成此操作:https://github.com/meeshkan/unmock-openapi-scripts/blob/master/README.md。
这可能需要一段时间,最后,你将得到一个大数据集。
2.下载词汇表
code2vec
-
从code2vec GitHub页面下载模型,按照快速入门部分中的说明进行操作。
-
使用gensim库加载。
model = word2vec.load_word2vec_format(vectors_text_path, binary=False)GloVe
-
从网站下载一个GloVe词汇表。我们选了最大的一个,因为这样它就更有可能找到我们所有的单词。你可以选择下载它的位置,但为了方便起见,最好将其存储在工作目录中。
-
手动加载GloVe词汇表。
embeddings_dict = {}
with open("../glove/glove.6B.300d.txt", 'r', encoding="utf-8") as f:
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], "float32")
embeddings_dict[word] = vectorspaCy
加载spaCy的词汇表:
nlp = spacy.load(‘en_core_web_lg’).3.提取字段名
OpenAPI规范名称的整个列表可以从scripts/fetch-list.sh文件或使用以下函数(对于Windows)获取:
def getListOfFiles(dirName):
listOfFile = os.listdir(dirName)
allFiles = list()
for entry in listOfFile:
fullPath = posixpath.join(dirName, entry)
if posixpath.isdir(fullPath):
allFiles = allFiles + getListOfFiles(fullPath)
else:
allFiles.append(fullPath)
return allFiles另一个大问题是从我们的OpenAPI规范中获取字段名。为此,我们将使用openapi-typed库。让我们定义一个get_fields函数,该函数接受OpenAPI规范并返回字段名列表:
def get_fields_from_schema(o: Schema) -> Sequence[str]:
return [
*(o['properties'].keys() if ('properties' in o) and (type(o['properties']) == type({})) else []),
*(sum([
get_fields_from_schema(schema) for schema in o['properties'].values() if not ('$ref' in schema) and type(schema) == type({})], []) if ('properties' in o) and ($ *(get_fields_from_schema(o['additionalProperties']) if ('additionalProperties' in o) and (type(o['additionalProperties']) == type({})) else []),
*(get_fields_from_schema(o['items']) if ('items' in o) and (type(o['items'] == type({}))) else []),
]
def get_fields_from_schemas(o: Mapping[str, Union[Schema, Reference]]) -> Sequence[str]:
return sum([get_fields_from_schema(cast(Schema, maybe_schema)) for maybe_schema in o.values() if not ('$ref' in maybe_schema) and (type(maybe_schema) == type({}))], [])
def get_fields_from_components(o: Components) -> Sequence[str]:
return [
*(get_fields_from_schemas(o['schemas']) if 'schemas' in o else []),
]
def get_fields(o: OpenAPIObject) -> Sequence[str]:
return [
*(get_fields_from_components(o['components']) if 'components' in o else []),
]恭喜!现在我们的数据集准备好了。
4.标识化
字段名可能包含标点符号,如_和-符号,或大小写为驼峰的单词。我们可以把这些单词切分,称为标识。
下面的camel_case函数检查驼峰命名。首先,它检查是否有标点符号。如果是,那就不是驼峰命名。然后,它检查单词内部是否有大写字母(不包括第一个和最后一个字符)。
def camel_case(example):
if any(x in example for x in string.punctuation)==True:
return False
else:
if any(list(map(str.isupper, example[1:-1])))==True:
return True
else:
return False下一个函数camel_case_split将驼峰单词拆分为多个部分。为此,我们应该识别大写字母并标记大小写更改的位置。函数返回拆分后的单词列表。例如,字段名BodyAsJson转换为一个列表[‘Body’,’As’,’Json’]。
def camel_case_split(word):
idx = list(map(str.isupper, word))
case_change = [0]
for (i, (x, y)) in enumerate(zip(idx, idx[1:])):
if x and not y:
case_change.append(i)
elif not x and y:
case_change.append(i+1)
case_change.append(len(word))
return [word[x:y] for x, y in zip(case_change, case_change[1:]) if x < y]这个camel_case_split函数随后用于以下标记化算法。在这里,我们首先检查单词中是否有标点符号。然后,我们把这个词分成几部分。这些词有可能是驼峰词。如果是这样的话,我们可以把它分成小块。最后,拆分每个元素后,整个列表将转换为小写。
def tokenizer(mylist):
tokenized_list=[]
for word in mylist:
if '_' in word:
splitted_word=word.split('_')
for elem in splitted_word:
if camel_case(elem):
elem=camel_case_split(elem)
for el1 in elem:
tokenized_list.append(el1.lower())
else:
tokenized_list.append(elem.lower())
elif '-' in word:
hyp_word=word.split('-')
for i in hyp_word:
if camel_case(i):
i=camel_case_split(i)
for el2 in i:
tokenized_list.append(el2.lower())
else:
tokenized_list.append(i.lower())
elif camel_case(word):
word=camel_case_split(word)
for el in word:
tokenized_list.append(el.lower())
else:
tokenized_list.append(word.lower())
return(tokenized_list)
tokenizer(my_word)5.创建字段名的数据集
现在,让我们用所有规范中的字段名创建一个大数据集。
下面的dict_dataset函数获取文件名和路径的列表,并打开每个规范文件。对于每个文件,get_field函数返回字段名的列表。某些字段名称可能在一个规范中重复。为了避免这种重复,让我们使用list(dict.fromkeys(col))将列表中的字段名列表转换为字典,然后再返回。然后我们可以将列表标识化。最后,我们创建一个以文件名为键,以字段名列表为值的字典。
def dict_dataset(datasets):
dataset_dict={}
for i in datasets:
with open(i, 'r') as foo:
col=algo.get_fields(yaml.safe_load(foo.read()))
if col:
mylist = list(dict.fromkeys(col))
tokenized_list=tokenizer(mylist)
dataset_dict.update({i: tokenized_list})
else:
continue
return (dataset_dict)6.测试嵌入
code2vec和GloVe
现在我们可以找出词汇表外的单词(未识别的单词)并计算这些单词在code2vec词汇表中所占的百分比。以下代码也适用于GloVe。
not_identified_c2v=[]
count_not_indent=[]
total_number=[]
for ds in test1:
count=0
for i in data[ds]:
if not i in model:
not_identified_c2v.append(i)
count+=1
count_not_indent.append(count)
total_number.append(len(data[ds]))
total_code2vec=sum(count_not_indent)/sum(total_number)*100spaCy
spaCy词汇表不同,因此我们需要相应地修改代码:
not_identified_sp=[]
count_not_indent=[]
total_number=[]
for ds in test1:
count=0
for i in data[ds]:
f not i in nlp.vocab:
count+=1
not_identified_sp.append(i)
count_not_indent.append(count)
total_number.append(len(data[ds]))
total_spacy=sum(count_not_indent)/sum(total_number)*100对于code2vec、glow和spaCy,未识别单词的百分比分别为3.39、2.33和2.09。由于每个算法的百分比相对较小且相似,因此我们可以进行另一个测试。
首先,让我们创建一个测试字典,其中的单词应该在所有API规范中都是相似的:
test_dictionary={'host': 'server',
'pragma': 'cache',
'id': 'uuid',
'user': 'client',
'limit': 'control',
'balance': 'amount',
'published': 'date',
'limit': 'dailylimit',
'ratelimit': 'rate',
'start': 'display',
'data': 'categories'}对于GloVe和code2vec,我们可以使用gensim库提供的similar_by_vector方法。spaCy还没有实现这个方法,但是通过这个我们可以自己找到最相似的单词。
为此,我们需要格式化输入向量,以便在距离函数中使用。我们将在字典中创建每个键,并检查对应的值是否在100个最相似的单词中。
首先,我们将格式化词汇表以便使用distance.cdist函数。这个函数计算词汇表中每对向量之间的距离。然后,我们将从最小距离到最大距离对列表进行排序,并取前100个单词。
from scipy.spatial import distance
for k, v in test_dictionary.items():
input_word = k
p = np.array([nlp.vocab[input_word].vector])
closest_index = distance.cdist(p, vectors)[0].argsort()[::-1][-100:]
word_id = [ids[closest_ind] for closest_ind in closest_index]
output_word = [nlp.vocab[i].text for i in word_id]
#output_word
list1=[j.lower() for j in output_word]
mylist = list(dict.fromkeys(list1))[:50]
count=0
if test_dictionary[k] in mylist:
count+=1
print(k,count, 'yes')
else:
print(k, 'no')下表总结了结果。spaCy显示单词“client”位于单词“user”的前100个最相似的单词中。它对几乎所有的OpenAPI规范都是有用的,并且可以用于将来OpenAPI规范相似性的分析。单词“balance”的向量接近单词“amount”的向量。我们发现它对支付API特别有用。
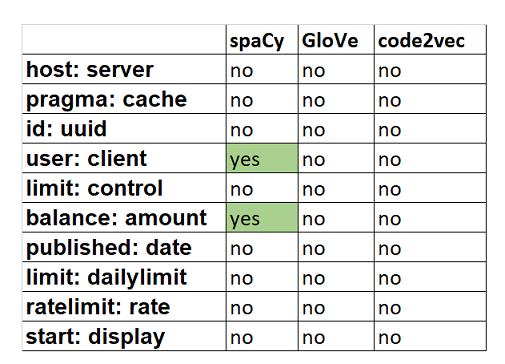
结论
我们已经为OpenAPI规范尝试了三种不同的词嵌入算法。尽管这三个词在这个数据集上都表现得很好,但是对最相似的单词进行额外的比较表明spaCy对我们的情况更好。
spaCy比其他算法更快。spaCy词汇表的读取速度比glow或code2vec词汇表快5倍。然而,在使用该算法时,缺少内置函数(如similar_by_vector和similar_word)是一个障碍。
另外,spaCy与我们的数据集很好地工作,这并不意味着spaCy对世界上的每个数据集都会更好。所以,请随意尝试为你自己的数据集嵌入不同的单词,感谢你的阅读!
原文链接:https://towardsdatascience.com/word-embeddings-with-code2vec-glove-and-spacy-5b26420bf632
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/09/01/%e7%94%a8code2vec%e3%80%81glow%e5%92%8cspacy%e8%bf%9b%e8%a1%8c%e8%af%8d%e5%b5%8c%e5%85%a5/
