
作者|ALAKH SETHI
编译|VK
来源|Analytics Vidhya
介绍
我喜欢使用C++。C++是我学习过的第一种编程语言,我喜欢在机器学习中使用它。
我在之前写过关于构建机器学习模型的文章。我收到了一个回复,问我C++有没有机器学习的库?
这是个公平的问题。像Python和R这样的语言有大量的包和库来满足不同的机器学习任务。那么C++有没有这样的产品呢?

是的,是的!在本文中,我将重点介绍两个这样的C++库,我们也将看到它们都可以运行。
目录
-
为什么我们要使用机器学习库?
-
C++中的机器学习库
-
SHARK 图书馆
-
MLPACK库
-
为什么我们要使用机器学习库?
这是很多新来者都会遇到的问题。库在机器学习中的重要性是什么?让我试着在这一节解释一下。
比如说,经验丰富的专业人士和行业老手已经付出了艰辛的努力,并想出了解决问题的办法。你更愿意使用它,还是愿意花几个小时从头开始重新创建相同的东西?后一种方法通常没有什么意义,尤其是当你在DDL前的工作或学习。
我们的机器学习社区最大的优点是已经有很多解决方案以库和包的形式存在。其他一些人,从专家到爱好者,已经做了艰苦的工作,并将解决方案很好地打包在一个库中。
这些机器学习库是有效的和优化的,它们经过了多个用例的彻底测试。依靠这些库,我们的学习能力和编写代码,无论是在C++或Python,都是如此的简单和直观。
C++中的机器学习库
在本节中,我们将介绍C+中两个最流行的机器学习库:
- SHARK库
- MLPACK库
让我们逐一查看并查看他们的C++代码。
1.SHARK库
Shark是一个快速的模块库,它对监督学习算法(如线性回归、神经网络、聚类、k-means等)提供了强大的支持。它还包括线性代数和数值优化的功能。这些是在执行机器学习任务时非常重要的关键数学函数。
我们将首先了解如何安装Shark并设置环境。然后我们将用Shark实现线性回归。
安装Shark和安装环境(Linux)
- Shark依赖于Boost和cmake。幸运的是,可以使用以下命令安装所有依赖项:
sudo apt-get install cmake cmake-curses-gui libatlas-base-dev libboost-all-dev- 要安装Shark,请在终端中逐行运行以下命令:
gitt clone https://github.com/Shark-ML/Shark.git (you can download the zip file and extract as well)
cd Shark
mkdir build
cd build
cmake ..
make如果你没见到错误,那就没问题了。如果你遇到麻烦,网上有很多信息。对于Windows和其他操作系统,你可以在Google上快速搜索如何安装Shark。这有一份安装指南:http://www.shark-ml.org/sphinx_pages/build/html/rest_sources/tutorials/tutorials.html
使用Shark编译程序
- 包括相关的头文件。假设我们要实现线性回归,那么额外的头文件包括:
用Shark编译程序
包括相关的头文件。假设我们要实现线性回归,那么包含的额外头文件是:
#include <shark/ObjectiveFunctions/Loss/SquaredLoss.h>
#include <shark/Algorithms/Trainers/LinearRegression.h>要编译,我们需要链接到以下库:
-std=c++11 -lboost_serialization -lshark -lcblas用Shark实现线性回归
初始化阶段
我们将从包含线性回归的库和头函数开始:
#include <bits/stdc++.h> //所有c++标准库的头文件
#include <shark/Data/Csv.h> //导入csv数据的头文件
#include <shark/ObjectiveFunctions/Loss/SquaredLoss.h> //用于实现平方损失函数的头文件
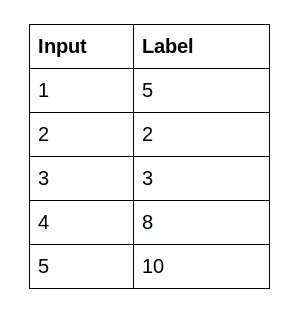
#include <shark/Algorithms/Trainers/LinearRegression.h>// 实现线性回归的头文件接下来是数据集。我已经创建了两个CSV文件。这个输入.csv文件包含x值和标签.csv文件包含y值。以下是数据的快照:
你可以在github仓库得到这2个文件:https://github.com/Alakhator/Machine-Learning-With-C-。
首先,我们将制作用于存储CSV文件中的值的数据容器:
Data<RealVector> inputs; //存储x值的容器
Data<RealVector> labels; //存储y值的容器接下来,我们需要导入它们。Shark提供了一个很好的导入CSV函数,我们指定了要初始化的数据容器,以及CSV的路径文件的位置:
importCSV(inputs, "input.csv"); // 通过指定csv的路径将值存储在特定的容器中
importCSV(labels, "label.csv");然后,我们需要实例化一个回归数据集类型。现在,这只是一个一般的回归对象,我们在构造函数中要做的是传递我们的输入以及数据的标签。
接下来,我们需要训练线性回归模型。我们怎么做呢?我们需要实例化一个训练器,并定义一个线性模型:
RegressionDataset data(inputs, labels);
LinearRegression trainer;// 线性回归模型训练器
LinearModel<> model; // 线性模型训练阶段
接下来是我们实际训练模型的关键步骤。在这里,trainer有一个名为train的成员函数。我们用函数训练这个模型
//训练模型
trainer.train(model, data);// train function ro training the model.预测阶段
最后,输出模型参数:
// 显示模型参数
cout << "intercept: " << model.offset() << endl;
cout << "matrix: " << model.matrix() << endl;线性模型有一个名为offset的成员函数,输出最佳拟合线的截距。接下来,我们输出一个矩阵。
我们通过最小化最小平方来计算最佳拟合线,也就是最小化平方损失。
幸运的是,模型允许我们输出这些信息。Shark库非常有助于说明模型的适用性:
SquaredLoss<> loss; //初始化square loss对象
Data<RealVector> prediction = model(data.inputs()); //根据数据输入预测
cout << "squared loss: " << loss(data.labels(), prediction) << endl; // 最后我们计算损失首先,我们需要初始化一个平方损失对象,然后我们需要实例化一个数据容器。然后,根据系统的输入计算预测,然后我们只需通过传递标签和预测值来计算输出损失。
最后,我们需要编译。在终端中,键入以下命令(确保正确设置了目录):
g++ -o lr linear_regression.cpp -std=c++11 -lboost_serialization -lshark -lcblas一旦编译,它就会创建一个lr对象。现在只需运行程序。我们得到的结果是:
b : [1](-0.749091)
A :[1,1]((2.00731))
Loss: 7.83109b的值离0有点远,但这是因为标签中存在噪声。乘数的值接近于2,与数据非常相似。这就是如何使用c++中的Shark库来构建线性回归模型!
MLPACK C++库
mlpack是一个用c++编写的快速灵活的机器学习库。它的目标是提供快速和可扩展的机器学习算法的实现。mlpack可以将这些算法作为简单的命令行程序、或绑定Python、Julia和c++,然后可以将这些类集成到更大规模的机器学习解决方案中。
我们将首先了解如何安装mlpack和环境。然后我们将使用mlpack实现k-means算法。
安装mlpack和安装环境(Linux)
mlpack依赖于以下库,这些库需要安装在系统上:
- Armadillo >= 8.400.0 (with LAPACK support)
- Boost (math_c99, program_options, serialization, unit_test_framework, heap, spirit) >= 1.49
- ensmallen >= 2.10.0
在Ubuntu和Debian中,你可以通过apt获得所有这些依赖项:
sudo apt-get install libboost-math-dev libboost-program-options-dev libboost-test-dev libboost-serialization-dev binutils-dev python-pandas python-numpy cython python-setuptools现在所有依赖项都已安装在系统中,可以直接运行以下命令来生成和安装mlpack:
wget
tar -xvzpf mlpack-3.2.2.tar.gz
mkdir mlpack-3.2.2/build && cd mlpack-3.2.2/build
cmake ../
make -j4 # The -j is the number of cores you want to use for a build
sudo make install在许多Linux系统上,mlpack默认安装为/usr/local/lib,你可能需要设置LD_LIBRARY_PATH环境变量:
export LD_LIBRARY_PATH=/usr/local/lib上面的说明是获取、构建和安装mlpack的最简单方法。
用mlpack编译程序
- 在你的程序中设置相关的头文件(实现k-means):
#include <mlpack/methods/kmeans/kmeans.hpp>
#include <armadillo>- 要编译,我们需要链接以下库:
std=c++11 -larmadillo -lmlpack -lboost_serialization
用mlpack实现K-Means
K-means是一个基于质心的算法,或者是一个基于距离的算法,在这里我们计算距离以将一个点分配给一个簇。在K-Means中,每个簇都与一个质心相关联。
K-Means算法的主要目标是最小化点与它们各自的簇质心之间的距离之和。
K-means是一个有效的迭代过程,我们希望将数据分割成特定的簇。首先,我们指定一些初始质心,所以这些质心是完全随机的。
接下来,对于每个数据点,我们找到最近的质心。然后我们将数据点指定给那个质心。所以每个质心代表一个类。一旦我们把所有的数据点分配给每个质心,我们就会计算出这些质心的平均值。
这里,我们将使用C++中的MLPACK库来实现k-均值。
初始化阶段
我们将首先导入k-means的库和头函数:
#include <bits/stdc++.h>
#include <mlpack/methods/kmeans/kmeans.hpp>
#include <armadillo>
Using namespace std;接下来,我们将创建一些基本变量来设置簇的数量、程序的维度、样本的数量以及我们要执行的最大迭代次数。因为K-均值是一个迭代过程。
int k = 2; //簇的数量
int dim = 2;//维度
int samples = 50;
int max_iter = 10;//最大迭代次数接下来,我们将创建数据。所以这是我们第一次使用Armadillo库。我们将创建一个映射类,它实际上是一个数据容器:
arma::mat data(dim, samples, arma::fill::zeros);这个mat类,我们给它2维,50个样本,它初始化所有这些数据值为0。
接下来,我们将向这个数据类分配一些随机数据,然后在其上有效地运行K-means。我将在位置1 1周围创建25个点,我们可以通过有效地说每个数据点是1 1或者在X = 1,y = 1的位置。然后我们要为这25个数据点中的每一个加一些随机噪声。
// 创建数据
int i = 0;
for(; i < samples / 2; ++i)
{
data.col(i) = arma::vec({1, 1}) + 0.25*arma::randn<arma::vec>(dim);
}
for(; i < samples; ++i)
{
data.col(i) = arma::vec({2, 3}) + 0.25*arma::randn<arma::vec>(dim);
}这里,对于从0到25的i,基本位置是X = 1,y = 1,然后我们要添加一定数量的维度为2的随机噪声。然后我们对点x=2,y=3做同样的操作。
我们的数据已经准备好了!是时候进入训练阶段了。
训练阶段
首先,我们实例化一个arma mat行类型来保存簇,然后实例化一个arma mat来保存质心:
//对数据进行聚类
arma::Row<size_t> clusters;
arma::mat centroids;现在,我们需要实例化K-means类:
mlpack::kmeans::KMeans<> mlpack_kmeans(max_iter);我们实例化了K-means类,并指定了传递给构造函数的最大迭代次数。现在,我们可以进行聚类了。
我们将调用这个K-means类的Cluster成员函数。我们需要传入数据、簇的数量,然后还要传入簇对象和质心对象。
mlpack_kmeans.Cluster(data, k, clusters, centroids);现在,这个Cluster函数将使用指定数量的簇对这个数据运行K-means
生成结果
我们可以使用centroids.print函数简单地显示结果。这将给出质心的位置:
centroids.print("Centroids:");接下来,我们需要编译。在终端中,键入以下命令(再次确认目录设置正确):
g++ k_means.cpp -o kmeans_test -O3 -std=c++11 -larmadillo -lmlpack -lboost_serialization && ./kmeans_test一旦编译,它就会创建一个kmeans对象。现在只需运行程序。我们得到的结果是:
Centroids:
0.9497 1.9625
0.9689 3.0652结尾
在本文中,我们看到了两个流行的机器学习库,它们帮助我们在c++中实现机器学习模型。
原文链接:https://www.analyticsvidhya.com/blog/2020/05/introduction-machine-learning-libraries-c/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/09/01/c%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a0%e5%ba%93%e4%bb%8b%e7%bb%8d/
