
作者|Renu Khandelwal
编译|VK
来源|Towards Data Science

在这篇文章中,我们将讨论以下有关Transformer的问题
- 为什么我们需要Transformer,Sequence2Sequence模型的挑战是什么?
- 详细介绍了Transformer及其架构
- 深入研究Transformer中使用的术语,如位置编码、自注意力、多头注意力、掩码多头注意力
- 可以使用Transformer的NLP任务
Sequence2Sequence (Seq2Seq)的缺点
- 顺序计算:在Seq2Seq中,我们以顺序的方式在每个步骤中向编码器输入一个单词,以便在解码器中每次生成一个单词的输出。在Seq2Seq架构中我们做不到通过并行化操作来提高计算效率。
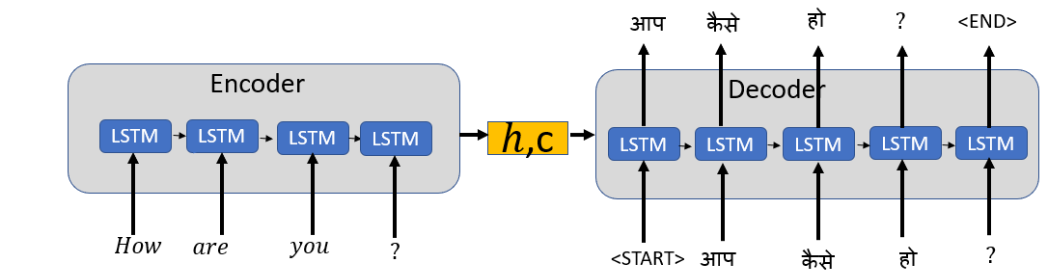
- 长期依赖关系:长期依赖关系是Seq2Seq的一个问题,这是由于需要为长句执行大量操作造成的,如下所示。

这里的“it”指的是“Coronavirus”还是“countries”?。
让我们深入了解Transformer的体系结构和Transformer的关键概念,以了解Transformer如何应对这些挑战
Transformer架构
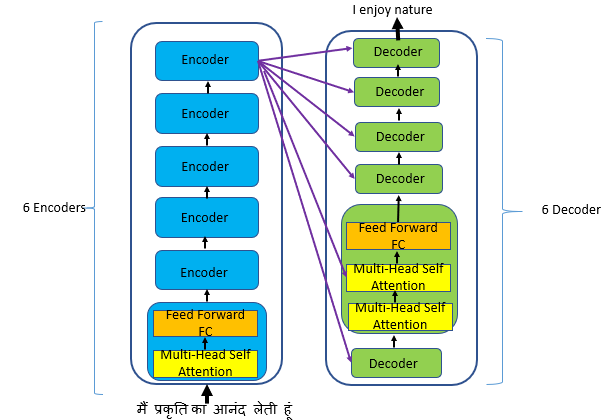
Transformer有6个编码器和6个解码器,不像Seq2Seq,该编码器包含两个子层:多头自注意层和一个全连接层。
该解码器包含三个子层,一个多头自注意层,一个能够执行编码器输出的多头自注意的附加层,以及一个全连接层。
编码器和解码器中的每个子层都有一个残差连接,然后进行layer normalization(层标准化)。
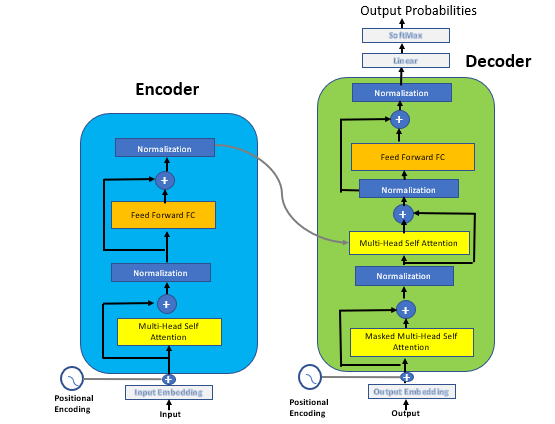
编码器和解码器的输入
所有编码器/解码器的输入和输出标记都使用学习过的嵌入转换成向量。然后将这些输入嵌入传入进行位置编码。
位置编码
Transformer的架构不包含任何递归或卷积,因此没有词序的概念。输入序列中的所有单词都被输入到网络中,没有特殊的顺序或位置,因为它们都同时流经编码器和解码器堆栈。
要理解一个句子的意思,理解单词的位置和顺序是很重要的。
位置编码被添加到模型中,以帮助注入关于句子中单词的相对或绝对位置的信息
位置编码与输入嵌入具有相同的维数,因此可以将二者相加。
自注意(self attention)
注意力是为了更好地理解句子中单词的含义和上下文。
自注意,有时也称为内注意,是一种将单个序列的不同位置联系起来以计算序列表示的注意力机制
一个自注意层用一个常数数量的连续执行的操作连接所有的位置,因此比重复的层更快
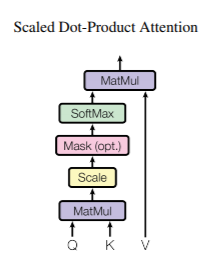
Transformer中的注意函数被描述为将查询和一组键值对映射到输出。查询、键和值都是向量。注意力权值是通过计算句子中每个单词的点积注意力来计算的。最后的分数是这些值的加权和。
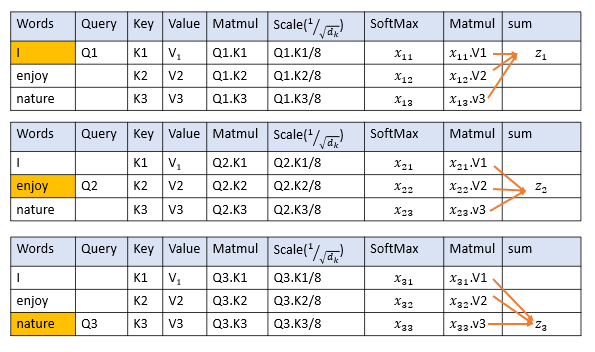
让我们用一句话来理解:“I enjoy nature.。”
输入是查询、键和值。向量的维数是64,因为这导致了更稳定的梯度。
步骤1:点积
取查询和句子中每个单词的键的点积。点积决定了谁更关注输入句子中的其他单词。
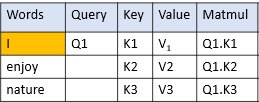
步骤2:缩放
通过除以键向量维数的平方根来缩放点积。大小是64;因此,我们将点积除以8。
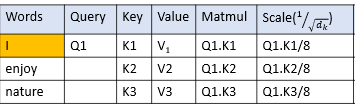
步骤3:使用softmax
Softmax使比例值归一。应用Softmax后,所有值均为正,加起来为1
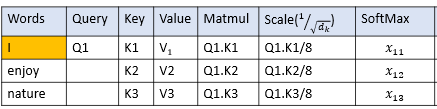
步骤4:计算各值的加权和
我们应用归一后的分数和值向量之间的点积,然后计算总和

自注意的完整公式
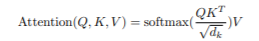
对句子中的每个单词重复这些步骤。
多头注意
Transformer使用多个注意力头,而不是单一的注意力函数,即由实际的单词本身来控制注意力。
每个注意头都有一个不同的线性变换应用于相同的输入表示。该Transformer使用8个不同的注意头,这些注意头是并行独立计算的。有了8个不同的注意头,我们就有了8个不同的查询、键和值集,还有8个编码器和解码器集,每个集都是随机初始化的
“多头注意力允许模型在不同的位置共同关注来自不同表示子空间的信息。”
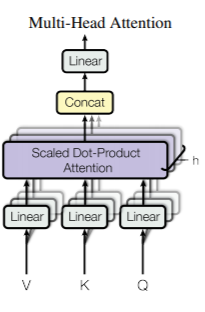
在一个多头注意头中,输入表示的每一部分都与输入表示的其他部分进行交互,以获得更好的含义和上下文。当多头注意力在不同的位置观察不同的表示子空间时,它也有助于学习长期的依赖关系。
利用多头注意,我们得知上面句子中的“it”指的是“Coronavirus”。
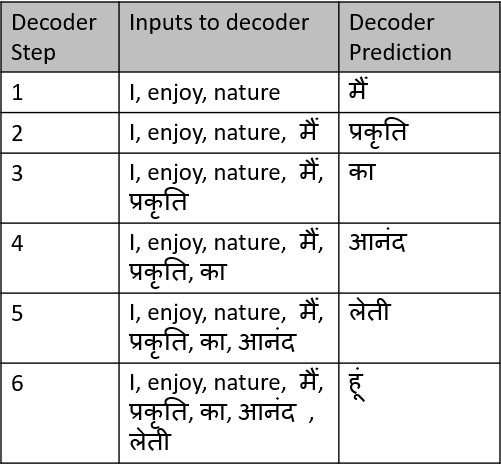
掩码多头注意
解码器对多头注意力进行掩码,在此掩蔽或阻止了解码器对未来步骤的输入。在训练过程中,解码器的多头注意力隐藏了未来的解码器输入。
在机器翻译任务中,使用Transformer将一个句子“I enjoy nature”从英语翻译成印地语,解码器将考虑所有输入的单词“I, enjoy, nature”来预测第一个单词。
下表显示了解码器将如何阻止来自未来步骤的输入
编码器和解码器中的每个子层都有一个残差连接,然后进行层标准化。
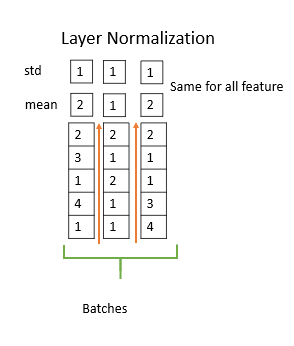
残差连接和层标准化
残差连接是“跳过连接”,允许梯度通过网络而不通过非线性激活函数。残差连接有助于避免消失或爆炸的梯度问题。为了使剩余的连接起作用,模型中每个子层的输出应该是相同的。Transformer中的所有子层,产生维度大小512的输出。
层标准化:对每个特征的输入进层标准化,并且与其他示例无关,如下所示。层标准化减少了前馈神经网络的训练时间。在层标准化中,我们在一个单一的训练案例中,计算所有层神经元的累加输入的平均值和方差。
全连接层
Transformer中的编码器和解码器都有一个全连接网络,它有两个线性变换,其中包含一个ReLU激活。
线性和softmax的解码器
译码器的最后一层利用线性变换和softmax函数对译码器输出进行转换,预测输出的概率
Transformer的特点
利用Transformer解决了seq2seq模型的不足
-
并行计算:Transformer的体系结构去掉了Seq2Seq模型中使用的自回归模型,完全依赖于自注意来理解输入和输出之间的全局依赖关系。自注意极大地帮助并行化计算
-
减少操作次数:Transformer的操作次数是恒定的,因为在多头注意中,注意权值是平均的
-
长依赖关系:影响远程依赖学习的因素是基于信号必须在网络中通过的前向和后向路径的长度。输入和输出序列中任意位置组合之间的路径越短,就越容易学习长期依赖关系。自注意层通过一系列连续执行的操作连接所有位置,学习长期依赖关系。
由Transformer处理的NLP任务
- 文本摘要
- 机器翻译
结论:
Transformer有一个简单的网络结构,基于自注意机制,不依赖于递归和卷积完全。计算是并行执行的,使Transformer效率高,需要更少的训练时间
原文链接:https://towardsdatascience.com/simple-explanation-of-transformers-in-nlp-da1adfc5d64f
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/09/01/nlp%e4%b8%ad%e7%9a%84transformer-%e7%ae%80%e4%bb%8b/
