
作者|Ali Aryan
编译|VK
来源|Towards Data Science
随着机器学习的兴起,我们看到了许多伟大的框架和库的兴起,比如scikit learn、Tensorflow、Pytorch。这些框架使得用户更容易创建机器学习模型。但仍然需要遵循包括数据准备、建模、评估在内的整个过程。
数据准备包括数据清理和预处理。建模接受预处理的数据并使用算法来预测结果。评估为我们的算法的性能提供了一个度量。由于这些库和框架,我们编写所有东西的时间减少了,但是我们仍然需要编写少量的代码。

“机器智能是人类最后一个需要创造的发明。”—尼克·博斯特罗姆
在惊人的开源社区的帮助下,这个领域的进步与日俱增,这些社区催生了现有的框架。考虑一个在一行中完成所有上述过程的框架。
是的,你读对了,现在你也可以这么做了。Libra是一个框架,它一条龙式为你工作。即使对于非技术人员来说,它也很容易使用。Libra需要最少的平均代码行数来训练模型。
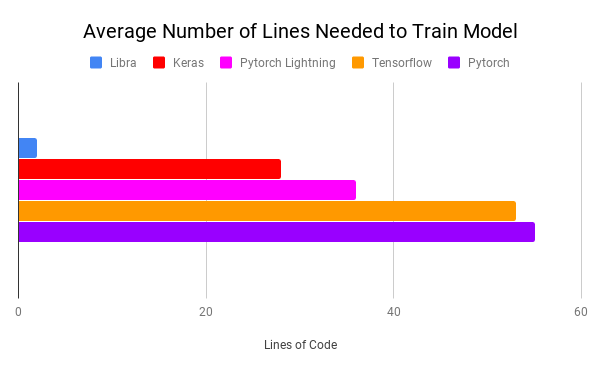
在这个博客里,我将给出如何使用Libra的完整指导。我将采取不同的数据集为不同的问题,并将向你展示一步一步的方法。
利用Libra进行信用卡欺诈检测
我使用了Kaggle数据集来预测信用卡欺诈。数据已经经过主成分分析,因此与原始数据相比,它现在被简化为更小维的数据。
在解决这个问题时,需要遵循一种系统的方法。一般来说,你将遵循第一段中提到的顺序。但有了Libra,你就不用担心了。
数据集链接:https://www.kaggle.com/mlg-ulb/creditcardfraud
此数据中的大多数交易在时间上是非欺诈性的(99.83%),而欺诈性交易在数据集中发生的时间(0.17%)。这意味着数据是高度不平衡的。让我们看看Libra对数据的预处理和结果。
安装Libra
pip install -U libra从libra导入客户端(client)
from libra import client使用Libra
一切都是围绕client构建的。你可以对它调用不同的查询,所有的内容都将存储在对象的models字段下。
我们在client对象中传递文件的位置,并将其命名为newClient。现在要访问各种查询,请参阅文档。
我用的是决策树。例如,预测房屋价值中位数,或估计住户数量。否则,该代码应与数据集中的列相对应。Libra会自动检测到目标列,但为了确保它选择了正确的列,我已经传递了目标列的名称。
newClient = client('creditcard.csv')
newClient.decision_tree_query('Class')
只需两行代码,我们就得到了大约0.99的分数,这是我们能得到的最好成绩。如果你检查其他人的成功,你会发现只有少数人获得了0.99的准确率,他们花了数小时来预处理数据并为其编写代码。
在这种情况下,Libra为你节省了很多时间,给你最好的结果。Libra使用智能预处理,这样你就不需要自己去预处理数据了。
你不必担心分析结果
newClient.analyze()为所有分类问题创建混淆矩阵和ROC曲线。它还计算召回率,精确度,f1和f2分数。
newClient.analyze()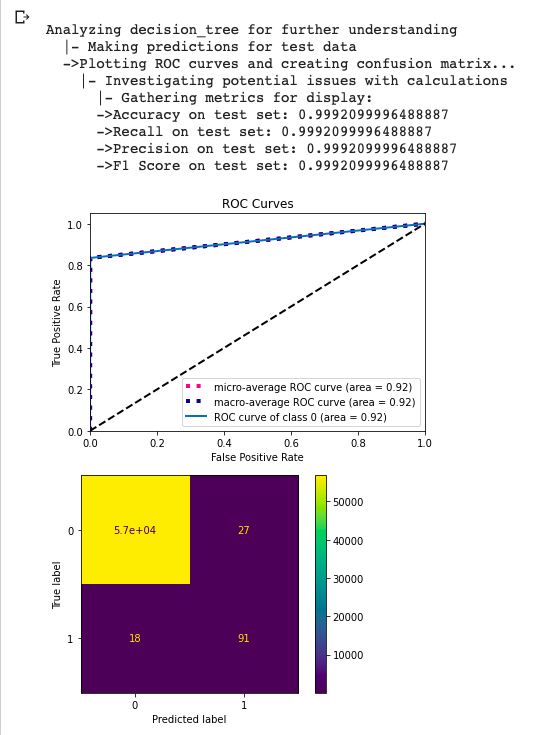
newClient.info()返回所有键,表示为数据集生成的每种数据类别。
newClient.info()
newClient.model() 返回该模型的字典。它包括从准确度,精确度,召回率,F1分数到所有的预处理技术。对于那些已经了解这些概念并能够编写代码的人来说,这会更有帮助。非技术用户不必为此担心。
newClient.model()
访问模型
newClient.model()返回字典,如果要访问模型,则可以直接使用newClient.model()[‘model’]
newClient.model()['model']
基于Libra的卷积神经网络
在colab Notebook使用下面的代码下载石头剪刀布数据集。我本可以直接向你展示使用Libra创建CNN的代码,但是我想创建一个例子,你可以自己在colab Notebook中尝试,以便更好地理解。你不需要担心下面的代码。
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/rps.zip \
-O /tmp/rps.zip
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/rps-test-set.zip \
-O /tmp/rps-test-set.zip使用下面的代码提取下载的文件。
import os
import zipfile
local_zip = '/tmp/rps.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/')
zip_ref.close()
local_zip = '/tmp/rps-test-set.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/')
zip_ref.close()我们用下面的代码创建文件夹,并将提取的图像放入其中。
rock_dir = os.path.join('/tmp/rps/rock')
paper_dir = os.path.join('/tmp/rps/paper')
scissors_dir = os.path.join('/tmp/rps/scissors')
print('total training rock images:', len(os.listdir(rock_dir)))
print('total training paper images:', len(os.listdir(paper_dir)))
print('total training scissors images:', len(os.listdir(scissors_dir)))
rock_files = os.listdir(rock_dir)
print(rock_files[:10])
paper_files = os.listdir(paper_dir)
print(paper_files[:10])
scissors_files = os.listdir(scissors_dir)
print(scissors_files[:10])下图显示了有关数据集的信息

使用下面的代码,你可以创建CNN。数据将通过缩放、剪切、翻转和重新缩放自动增加。然后选择最佳的图像大小。你还将注意到每个类中的图像数量以及与之关联的类的数量。最后,还要观察训练精度和测试精度。
你还可以在convolutional_query内部传递read_mode超参数,在其中你可以指定读取模式。允许有三种读取模式。我将逐一描述它们。默认情况下,read_mode=distinguisher()自动检测数据类型。允许的三种读取模式是:
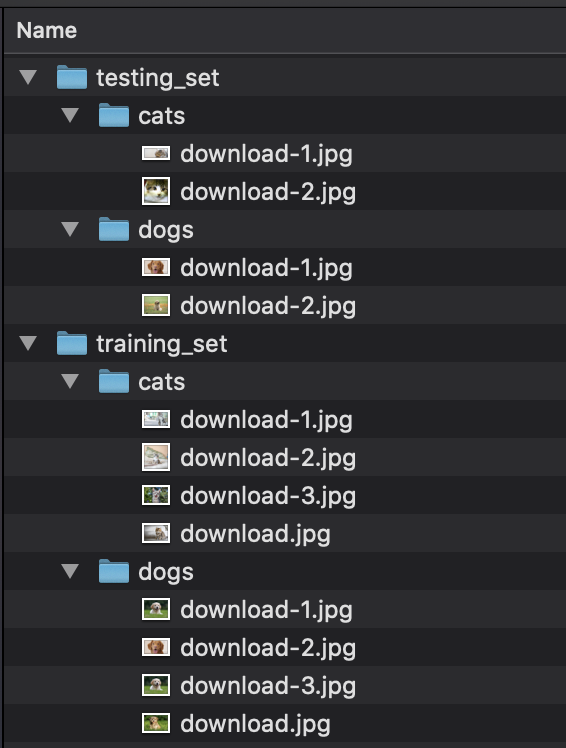
1.Setwise
目录由“training_set”和“testing_set”文件夹组成,这两个文件夹都包含带有图像的分类文件夹。
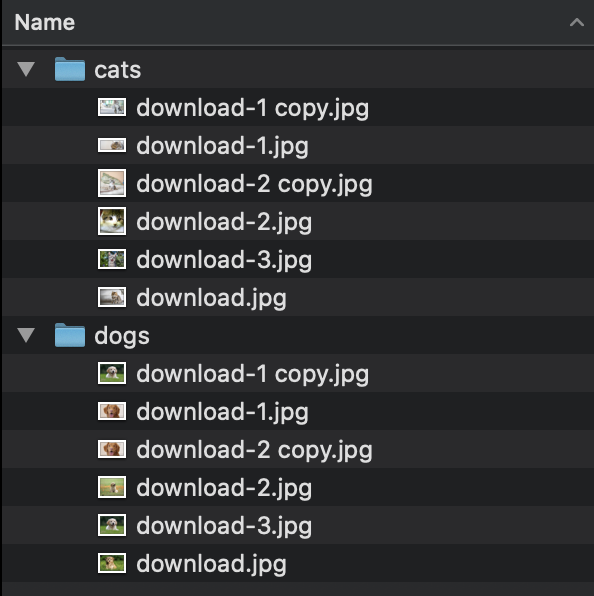
2.Classwise
目录由包含图像的分类文件夹组成。
3.CSV Wise
目录由图像文件夹和包含图像列的CSV文件组成。
newClient = client('/tmp/rps')
newClient.convolutional_query("Please classify my images")
基于Libra的NLP文本分类
我使用垃圾邮件分类数据集来解决这个问题。
链接:https://www.kaggle.com/team-ai/spam-text-message-classification
new_client = client('SPAM text message 20170820 - Data.csv')
new_client.text_classification_query('sentiment')
new_client.classify_text('new text to classify')
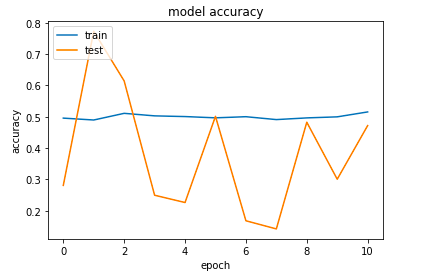
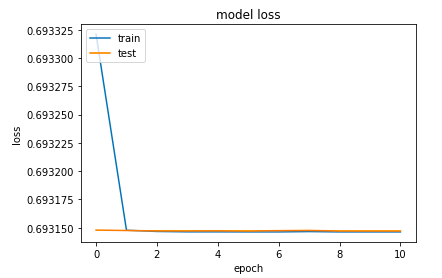
new_client.classify_text()将对其中输入的文本进行分类。在上面的输出中,你可以看到它将我的文本分类为“ham”。
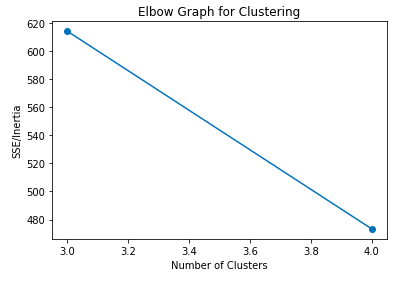
使用Libra进行均值聚类
我使用商场客户划分数据来解决这个问题:https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python
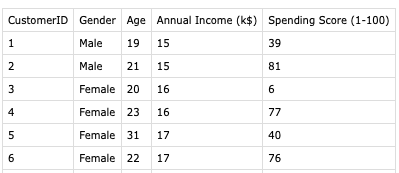
Libra将创建一个K均值聚类模型,并将确定最佳簇中心,优化准确度,以及最佳聚类数。

基于Libra的神经网络分类
在本节中,我将使用神经网络查询进行分类。为此,我使用了一个私人数据集来预测大脑信号的行为。让我们检查一下它在那个数据集上的执行情况。
new_client = client('Mood_classification.csv')
new_client.neural_network_query('Predict the behavior')
从上面的代码中,你可以注意到模型使用的初始层数是3。然后,它还测试了不同层数的精度,这些层数根据前一层的性能而变化。
它可以预测找到的最佳层数以及训练和测试的准确性。看来我需要为我的数据集收集更多的数据。
你可以用new_client.model()[‘model’]访问模型,并可以使用Keras的summary()函数获取神经网络模型的摘要。
new_client.model()['model'].summary()
结论
Libra是一个非常有趣的框架,每天都在进步。这个框架为我们提供了数据科学领域发展速度的概述,也让我们看到了这个领域中可能存在的变化类型。他们还为现有的数据科学家添加了一些功能,以修改现有的神经网络,并在指定的索引处添加类似LSTM的层。我对这个框架带来的概念感到兴奋。
参考文献:
[1] Libra, Documentation(2020), http://libradocs.github.io/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e5%88%a9%e7%94%a8libra%e8%bf%9b%e8%a1%8c%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a0%e5%92%8c%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0/
