
作者|OngKoonHan
编译|Flin
来源|towardsdatascience
在我大学的Android开发课程的组项目部分中,我们的团队构建并部署了一个认证系统,通过说话人的语音配置文件进行认证。
在我上一篇文章(请参阅下一部分)描述了语音认证系统的高级体系结构之后,本文将深入探讨所使用的深度学习模型的开发过程。
我以前的文章可以在这里找到(一个带有移动部署的初级语音认证系统)。

在这篇简短的文章中,我将描述开发语音认证模型所涉及的不同阶段,并讨论在学习过程中遇到的一些问题。
这是文章的概述:
-
问题陈述
-
高级模型设计
-
数据预处理
-
对比学习语音编码器
-
身份验证的二进制分类器
-
模型表现
问题陈述
在开始之前,我们需要弄清楚我们是如何试图构建语音认证问题的。
语音认证主要有两种方式(广义地说):说话人识别和说话人验证。这两种方法虽然密切相关,但在比较两种系统的相关安全风险时,它们将导致两个系统具有截然不同的特性。
问题定义:
说话人识别:n分类任务:给定一个输入语音,从n个已知说话人(类)中找出正确的说话人。
说话人验证:二元分类任务:给定一个声明身份的说话者的输入话语,确定该声明身份是否正确。
我们可以看到,在说话人识别中,我们假设给定的输入话语属于我们已经认识的说话人(也许是办公环境),我们试图从n个已知的说话人(类)中选出最匹配的。
相反,在说话人验证中,我们假设我们不知道给定输入话语属于谁(事实上我们不需要知道)。我们关心的是给定的一对输入话语是否来自同一个人。
准确地说,从整个说话人验证系统的角度来看,系统“知道”说话人声称自己是“已知”的人,而从模型的角度来看,模型只接收一对语音样本并判断它们是否来自同一个人。
想象一下使用一个常规的用户名和密码认证系统。系统知道你声称是谁(用户名),并检索参考密码的存储副本。然而,密码检查器只检查参考密码是否与输入密码匹配,并将验证结果返回给验证系统。
在此项目中,语音身份验证问题被构造为说话者验证问题。
旁白:
在这一点上,值得注意的是,还有另一种类型的语音分析问题,称为说话人分类(Speaker Diarisation),它试图分离出多人同时讲话的源信号。
说话人分类涉及多人同时讲话的场景(想象一下在两张满是人的桌子之间放一个麦克风),我们试图分离出每一个独特的说话人的语音音频波形。这可能需要多个麦克风从不同的角度捕捉同一场景,或者只需要一个麦克风(最困难的问题)。
我们可以看到这会变得非常复杂。一个例子是识别在给定对话的录音中谁在讲话。在试图给说话人起名字(说话人识别)之前,必须先分离对话中每个人的语音信号(说话人分类)。当然,存在混合方法,这是一个活跃的研究领域。
高级模型设计
转换数据以进行迁移学习—对于这个任务,我希望尽可能地利用迁移学习,以避免自己构建一个复杂而高效的模型。
为了实现这一目标,语音音频信号被转换成类似某种图像的声谱图。将音频转换为声谱图后,我便可以使用PyTorch中可用的任何流行图像模型,例如MobileNetV2,DenseNet等。
其中一个演讲者的声谱图
事后,我意识到我可以使用基于小波变换(WT)的方法来代替基于傅立叶变换变换(FT)的Melspectrogram来获得“更清晰”的光谱图图像。
Youtube视频中的一个演示(https://youtu.be/g8MfWGibjT8) 比较了心脏心电信号的小波变换和傅立叶变换在“图像质量”上的差异,结果表明,小波变换得到的声谱图在视觉上比傅立叶变换更“清晰”。
对比学习的杠杆作用:大家都熟悉的对比学习的经典例子是使用三重态损失的设置。此设置每次编码3个样本:参考样本、正样本和负样本(2个候选样本)。目标是减小参考样本和正样本之间编码向量的距离,同时增加参考样本和负样本之间编码向量的距离。
在我的方法中,我不想将候选样本的数量限制在2个。相反,我使用了一种类似于SimCLR(Chen等人,2020)的方法,即使用多个候选样本,其中一个样本是正样本。然后“对比分类器”被迫从一堆候选样本中选出正样本。
两阶段迁移学习法:为了解决说话人验证问题,我们将分两个阶段训练模型。
首先,通过对比学习对说话人语音编码器进行训练。如前所述,对比学习将涉及多个候选样本,而不是通常的三重态损失设置的正负对。
其次,在预先训练好的语音编码器上训练二元分类器。这将允许语音编码器在用于此传输学习任务(二进制分类器)之前单独进行训练。
数据预处理
VoxCeleb1数据集:为了训练模型识别说话人的语音配置文件(无论他/她说了什么),我选择使用VoxCeleb1公共数据集。
VoxCeleb1数据集包含多个扬声器在野外的音频片段,也就是说,这些扬声器在“自然”或“常规”设置下讲话。对数据集中的演讲者进行访谈,并对数据集中的音频片段进行管理,使每个片段都包含演讲者正在谈话的访谈片段。
这个数据集包含了每个说话人在不同的访谈设置下的多个访谈,并且使用了不同类型的设备,这给了我希望语音认证系统配合使用的可变性。
对于这个项目,只使用音频数据(视频数据可用)。还有其他的认证系统试图合并多种数据模式(比如视频和音频结合起来,以检测语音是否在现场生成),但我认为这超出了我的项目范围。
音频波形到声谱图:为了能够利用流行的图像模型架构,语音音频信号被转换成类似某种图像的声谱图。
首先,将来自同一扬声器的多个短音频样本组合成一个长音频样本。由于mel谱图是基于短时傅里叶变换(STFT)的,因此可以将整个长音频样本一次性转换成mel谱图,并从长谱图中得到更小的谱片。
由于长音频样本是由单个唯一说话人的较小音频样本组成的,因此从长样本中提取片段应该会迫使模型专注于从每个单独说话的人的语音配置文件中找出独特的特征。
来自一个扬声器的串联音频样本:

接下来,使用LibROSA(Librosa)库将长音频样本转换为频谱图。以下是使用的关键参数:
-
Target sampling rate(目标采样率): 22050
-
STFT window: 2048
-
STFT hop length: 512
-
Mels: 128
然后将功率谱转换为对数级的分贝。因为我们是用图像网络分析的,所以我们希望光谱图中的“images”特征稍微均匀分布。
一个扬声器的混音谱图
创建“images”:采样是通过从长光谱图中分割较小的光谱图来完成的。
光谱图“images”创建为128x128x3阵列,格式为RGB图像。在长谱图上随机选取一个起始点,对每个新切片滑动半步(128/2=64),得到三个128×128的谱图切片。然后用[-1,1]之间的最大绝对值对“images”进行标准化。
最初,我复制同一个光谱片3次,将“灰度”图像转换为“RGB”图像。然而,我决定将更多的信息打包到每个光谱图“images”中,为每个“RGB”图像放入3个稍有不同的切片,因为这3个通道不像普通RGB图像那样具有通常的含义。使用这种滑动技术后,性能似乎略有改善。
对比学习语音编码器
数据采样 —— 以下是用于语音编码器对比学习的数据采样的一些详细信息。
[**频谱图切片将称为“图像”]
对于每个时期,将200个(总共1,000个)随机全长频谱图加载到内存中(“子样本”)(由于资源限制,并非所有1000个全长频谱图都可以一次加载)。
每行使用1个参考样本和5个候选样本。候选图像包含4个负样本和一个正样本(随机混洗),并且图像是从子样本中随机生成的。
每个时期有2,000行,批大小为15(MobileNetV2)和6(DenseNet121)。
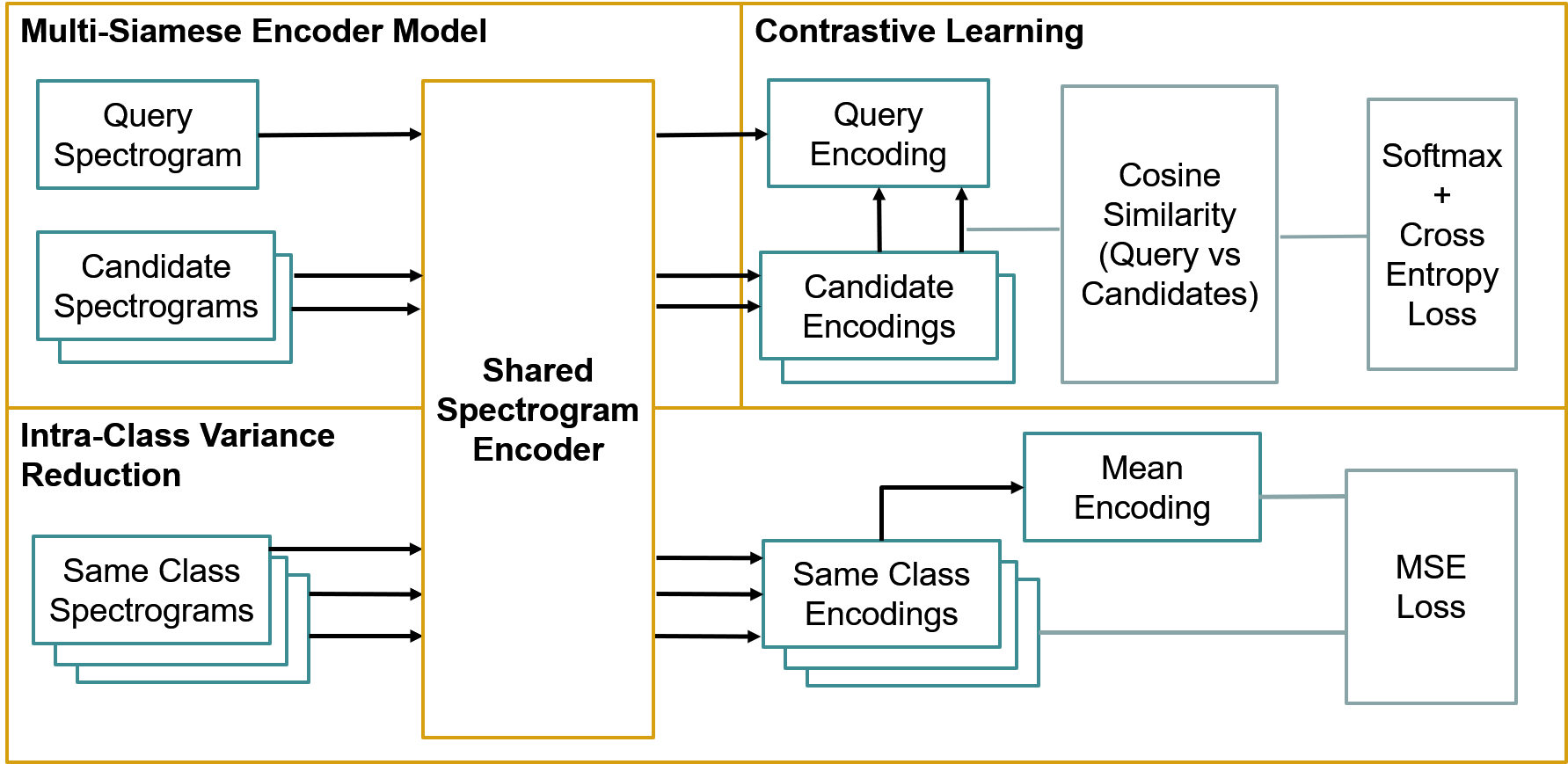
多暹罗编码器网络 — 对于编码器网络,使用的基本模型是MobileNetV2和DenseNet121。编码器层大小为128(取代基本模型中的Imagenet分类器)。
为了便于对比学习,建立了一个多连体编码器模型包装器作为torch模块。该包装器对每个图像使用相同的编码器,方便了参考图像和候选图像之间的余弦相似性计算。
对比损失+类内方差减少——两个目标,对比损失和方差减少,连续最小化(由于资源限制,理想情况下,两个目标的损失应相加并最小化)。每1批计算对比损失,每2批进行方差缩减(类内MSE)。
对于对比损失,该问题被描述为一个n分类问题,模型试图从所有候选对象中识别出正样本。针对参考编码计算所有候选编码的余弦相似度,并根据余弦相似度产生的概率计算一个softmax。根据一般的n-分类问题,交叉熵损失最小。
对于类内方差减少,目的是将来自同一类的图像在编码空间中推近。对来自同一类/同一说话人的图像进行采样,计算平均编码矢量。编码的MSE损失根据平均值(类内方差)计算,并且在反向传播之前,MSE损失按0.20进行缩放。
身份验证的二进制分类器
数据采样 —— 以下是用于说话人验证二进制分类器的数据采样的一些详细信息。
对于每个时期,将200个(总共1,000个)随机全长频谱图加载到内存中(“子样本”)(由于资源限制,并非可以一次加载所有1,000个全长频谱图)。
对于每个参考图像,将生成2张测试图像,其中1张为正图像,1张为负图像。对于每个参考图像,这将产生2对/行,真实对(正)和假冒者对(负)。
图像是从子样本中随机生成的。每个时期有4,000行,并且批大小为320(MobileNetV2和DenseNet121)。
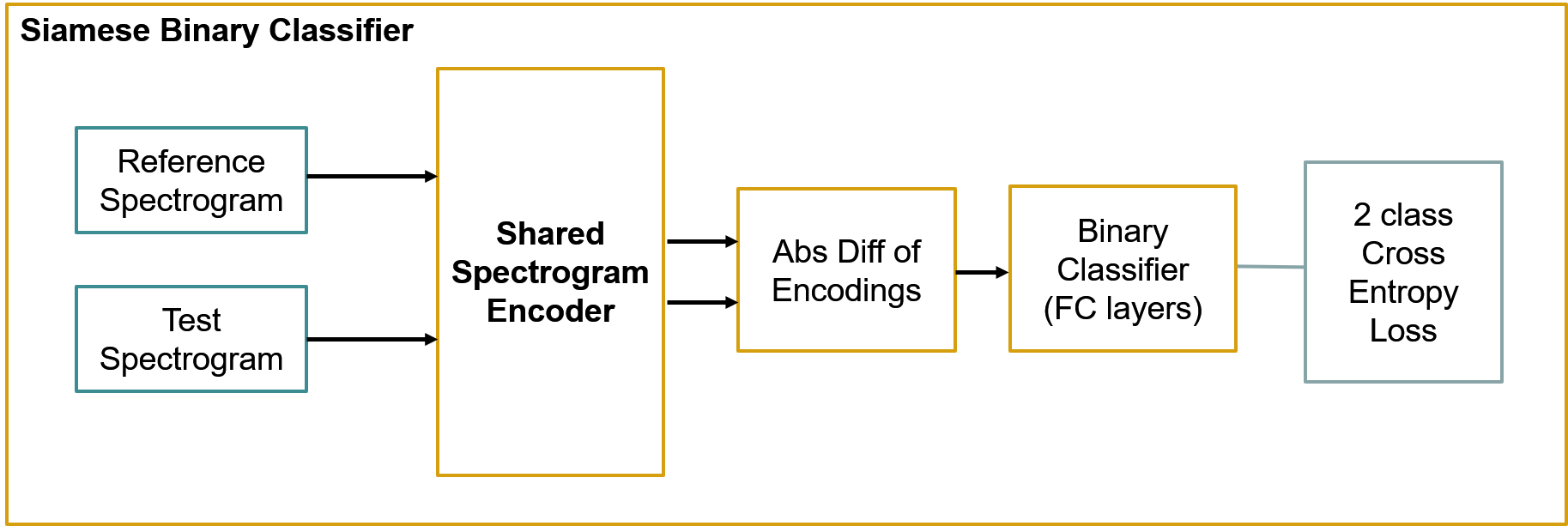
验证二进制分类器网络 —— 底层编码器网络是来自对比学习步骤的预训练编码器网络,在训练过程中权重被冻结。
二进制分类器设置为暹罗网络,其中计算了来自输入对的编码矢量的绝对差。然后,将二元分类器构建在绝对差异层之上。
模型训练
学习率循环:循环学习率可提高对比学习步骤和二元分类器步骤中的模型准确性。
使用了torch.optim.lr_scheduler.CyclicLR(),其步长(默认)为2000,循环模式(默认)为“Triangular”,没有动量循环(Adam优化器)。
学习率的范围如下:
-
具有对比学习功能的语音编码器: 0.0001至0.001
-
基本分类器: 0.0001至0.01
模型表现
不出所料,模型性能不如最新模型。我认为,促成因素是:
-
声谱图不是我本可以使用的最佳信号转换。基于小波变换的方法可能会产生更多高质量的声谱图“图像”。
-
使用的基本图像模型不是最新的模型,因为我无法在中等大小的GPU(3GB VRAM)上使用超大型模型。也许像ResNet或ResNeXt这样更强大的模型可能会产生更好的结果。
-
仅使用了一个语音数据集(VoxCeleb1)。肯定可以使用大量和各种各样的数据(但遗憾的是,最后期限迫在眉睫)。
以下是可比模型的均等错误率(EER):
-
我最好的模型EER 19.74%(VoxCeleb)
-
Le and Odobez (2018), Best model from scratch EER 10.31% (VoxCeleb)
-
Jung, et. al. (2017), EER 7.61% (RSR2015 dataset)
其他调查结果
基本模型大小:使用更大的基本模型提高了分类性能(MobileNetV2 vs DenseNet121)。
类内方差减少的效果:类内方差减少提高了两个基本模型的分类性能。事实上,经过方差缩减的mobilenetw2的性能提高到了与DenseNet121相当的水平。
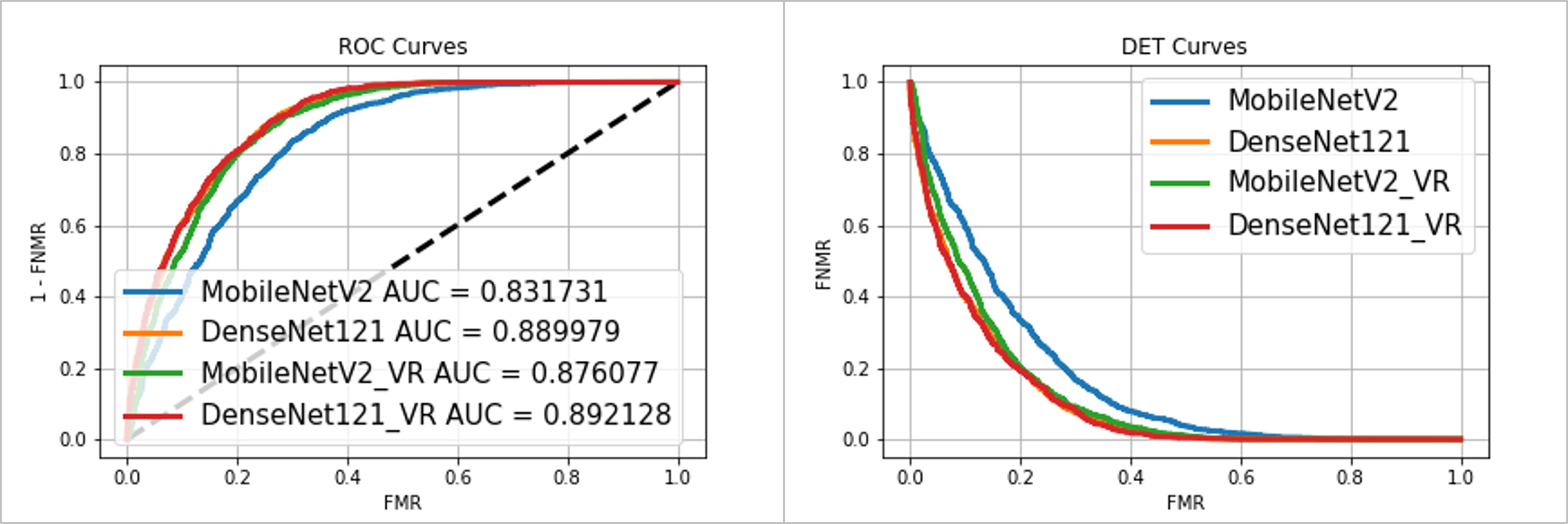
ROC(左)和DET(右)曲线
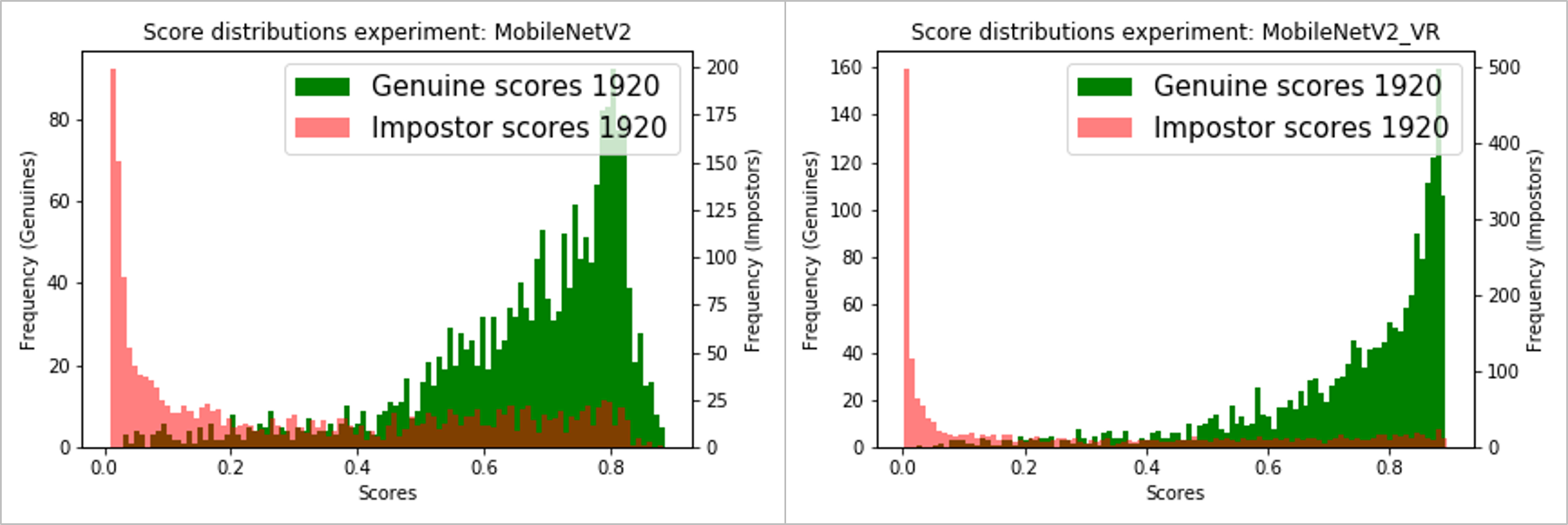
下面是使用MobileNetV2和DenseNet121的二元分类分数分布[P(is_genuine)],包括带/不带方差减少。
MobileNetV2基本模型-不带/带方差减少(左/右):
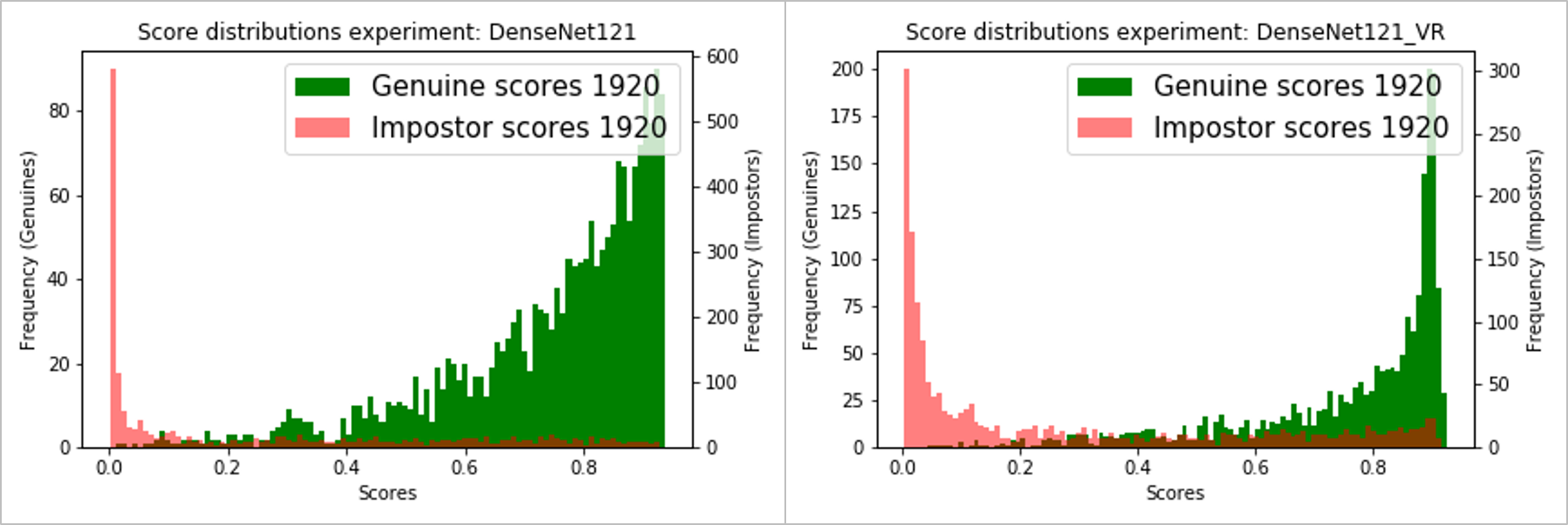
DenseNet121基本模型-不带/带方差减少(左/右):
参考文献
Chen, T., Kornblith, S., Norouzi, M. and Hinton, G., 2020. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709
Jung, J., Heo, H., Yang, I., Yoon, S., Shim, H. and Yu, H., 2017, December. D-vector based speaker verification system using Raw Waveform CNN. In 2017 International Seminar on Artificial Intelligence, Networking and Information Technology (ANIT 2017). Atlantis Press.
Le, N. and Odobez, J.M., 2018, September. Robust and Discriminative Speaker Embedding via Intra-Class Distance Variance Regularization. In Interspeech (pp. 2257–2261).
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e7%94%a8%e5%af%b9%e6%af%94%e5%ad%a6%e4%b9%a0%e8%ae%ad%e7%bb%83%e8%af%b4%e8%af%9d%e4%ba%ba%e5%88%9d%e6%ad%a5%e9%aa%8c%e8%af%81%e6%a8%a1%e5%9e%8b/
