
作者|Nouman
编译|VK
来源|Towards Data Science
在这篇文章中,我将教你建立你自己的网页应用程序,它将接受你的狗的图片,并输出其品种。准确率超过80%!

我们将使用深度学习来训练一个模型的数据集的狗图像与他们的品种,以学习的特征来区分每一个品种。
数据分析
数据集可以从这里下载(https://s3-us-west-1.amazonaws.com/udacity-aind/dog-project/dogImages.zip)。在成功加载和浏览数据集后,以下是关于数据的一些介绍:
-
犬种总数:133
-
狗图片总数:8351(训练集:6680,验证集:835,测试集:836)
-
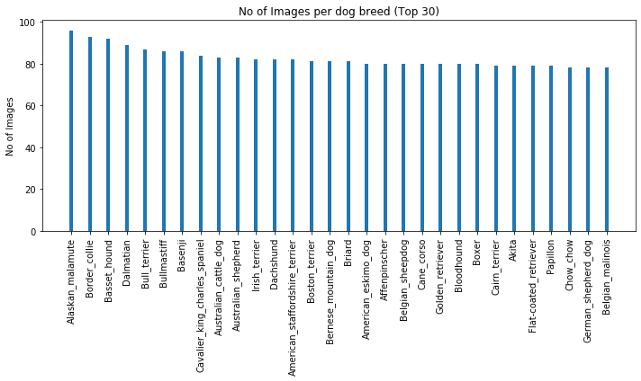
最受欢迎的品种:阿拉斯加:96,博德牧羊犬:93
按图片数量排序的前30个品种如下:
我们还可以在这里看到一些狗的图片和它们的品种:

数据预处理
经过分析,为机器学习算法准备数据。我们将把每个图像作为一个numpy数组加载,并将它们的大小调整为224×224,因为这是大多数传统神经网络接受图像的默认大小。我们还将为图像的数量添加另一个维度
from keras.preprocessing import image
from tqdm import tqdm
def path_to_tensor(img_path):
'''将给定路径下的图像转换为张量'''
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
'''将给定路径中的所有图像转换为张量'''
list_of_tensors = [path_to_tensor(img_path) for img_path in tqdm(img_paths)]
return np.vstack(list_of_tensors)最后,我们将使用ImageDataGenerator对图像进行动态缩放和增强
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
vertical_flip=True,
rotation_range=20)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255.)
test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255.)
train_generator = train_datagen.flow(train_tensors, train_targets, batch_size=32)
valid_generator = train_datagen.flow(valid_tensors, valid_targets, batch_size=32)
test_generator = train_datagen.flow(test_tensors, test_targets, batch_size=32)CNN
我们将在预处理数据集上从头开始训练卷积神经网络(CNN),如下所示:
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(224, 224, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(256, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(2048, activation='softmax'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1024, activation='softmax'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(133, activation='softmax')
])
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
checkpointer = tf.keras.callbacks.ModelCheckpoint(filepath='../saved_models/weights_best_custom.hdf5',
verbose=1, save_best_only=True)
model.fit(train_generator, epochs=5, validation_data=valid_generator, callbacks=[checkpointer])我们使用一个ModelCheckpoint回调来保存基于验证分数的模型。测试这个模型,我们得到的准确率只有1%左右
使用迁移学习
现在,我们将看到如何使用预训练的特征可以产生巨大的不同。下载ResNet-50。你可以通过运行下面的代码单元来提取相应的训练集、测试和验证集:
bottleneck_features = np.load('Data/bottleneck_features/DogResnet50Data.npz')
train_Resnet50 = bottleneck_features['train']
valid_Resnet50 = bottleneck_features['valid']
test_Resnet50 = bottleneck_features['test']我们现在将再次定义模型,并对提取的特征使用GlobalAveragePooling2D,它将一组特征平均为一个值。最后,如果验证损失在两个连续的epoch内没有增加,我们使用额外的回调来降低学习率,降低平台,并且如果验证损失在连续的5个epoch内没有增加,也可以提前停止训练。
Resnet50_model = tf.keras.models.Sequential()
Resnet50_model.add(tf.keras.layers.GlobalAveragePooling2D(input_shape=train_Resnet50.shape[1:]))
Resnet50_model.add(tf.keras.layers.Dense(1024, activation='relu'))
Resnet50_model.add(tf.keras.layers.Dense(133, activation='softmax'))
Resnet50_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
checkpointer = tf.keras.callbacks.ModelCheckpoint(filepath='saved_models/weights_best_Resnet50.hdf5',
verbose=1, save_best_only=True)
early_stopping = tf.keras.callbacks.EarlyStopping(patience=5, monitor='val_loss')
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(patience=2, monitor='val_loss')
Resnet50_model.fit(train_Resnet50, train_targets,
validation_data=(valid_Resnet50, valid_targets),
epochs=50, batch_size=20, callbacks=[checkpointer, early_stopping, reduce_lr], verbose=1)### 训练模型在测试集上的准确率为82.65%。与我们白手起家训练的模型相比,这是一个巨大的进步。
构建web应用程序
对于web应用程序,我们将首先编写一个helper函数,该函数接受图像路径并返回品种。label_to_cat字典将每个数字标签映射到它的狗品种。
def predict_breed(img_path):
'''预测给定图像的品种'''
# 提取特征
bottleneck_feature = extract_Resnet50(path_to_tensor(img_path))
bottleneck_feature = tf.keras.models.Sequential([
tf.keras.layers.GlobalAveragePooling2D(input_shape=bottleneck_feature.shape[1:])
]).predict(bottleneck_feature).reshape(1, 1, 1, 2048)
# 获得预测向量
predicted_vector = Resnet50_model.predict(bottleneck_feature)
# 模型预测的犬种
return label_to_cat[np.argmax(predicted_vector)]对于web应用程序,我们将使用flaskweb框架来帮助我们用最少的代码创建web应用程序。我们将定义一个接受图像的路由,并用狗的品种呈现一个输出模板
@app.route('/upload', methods=['POST','GET'])
def upload_file():
if request.method == 'GET':
return render_template('index.html')
else:
file = request.files['image']
full_name = os.path.join(UPLOAD_FOLDER, file.filename)
file.save(full_name)
dog_breed = dog_breed_classifier(full_name)
return render_template('predict.html', image_file_name = file.filename, label = dog_breed)predict.html是分别显示图像及其犬种的模板。
结论
祝贺 你!你已经成功地实现了一个狗品种分类器,并且可以自信地分辨出狗的品种。让我们总结一下我们在这里学到的:
-
我们对数据集进行了分析和预处理。机器学习算法需要单独的训练集、测试集和验证集来进行置信预测。
-
我们从零开始使用CNN,由于未能提取特征,所以表现不佳。
-
然后我们使用迁移学习,准确度大大提高
-
最后,我们构建了一个Flask web应用程序来准备我们的项目产品
我们确实学到了很多东西,但还有很多其他的事情你可以尝试。你可以在heroku上部署web应用程序,也可以尝试使用不同的层(如Dropout层)来提高准确性。
要获得更多信息和详细分析,请查看我的GitHub上的代码:https://github.com/nouman-10/Dog-Breed-Classifier
原文链接:https://towardsdatascience.com/dont-know-the-breed-of-your-dog-ml-can-help-6558eb5f7f05
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e4%bd%bf%e7%94%a8%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e8%af%86%e5%88%ab%e7%8b%97%e7%9a%84%e5%93%81%e7%a7%8d/
