
作者|Christopher Tao
编译|VK
来源|Towards Datas Science
作为一个使用Python作为主要编程语言的数据科学家或分析师,我相信你一定经常使用Pandas。在Jupyter Notebook上输出pandas DataFrame是非常频繁的。
然而,你有没有想过,我们可以让DataFrame本身可视化?换句话说,对于一些简单的可视化目的,我们不需要Matplotlib或其他可视化库。
Pandas DataFrame输出可以像Excel电子表格一样可视化,并且支持复杂样式,代码非常简单。
在这篇文章中,我将介绍Pandas库中的样式包,与它的数据处理方法相比,知道它的人相对较少。此外,还有一些有趣的库,它们支持Pandas DataFrame的更多在线可视化。在最后一节中,我还将介绍其中的一个Sparklines。
关于Pandas库

众所周知,Pandas DataFrame可以输出到iPython/Jupyter Notebook中,该 Notebook自动以HTML格式呈现CSS样式。这绝对是一个惊人的功能,因为即使我们只是简单地打印它,演示文稿也非常漂亮。
它使用“HTML+CSS”。Pandas还允许我们定制CSS样式,使它看起来更漂亮。这是通过“style”API实现的。
https://pandas.pydata.org/docs/reference/style.html
我们可以直接调用df.style获取 DataFrame的Styler对象,然后添加所需的样式。现在,让我们看看我们能做些什么。
格式化输出
当然,我们总是可以格式化数据本身,比df.round(2))将所有数值四舍五入到2位小数。然而,使用Pandas style也有一些好处。例如,我们实际上不更改值,而只更改表示形式,这样就不会丢失精度。
让我们先创建一个随机DataFrame。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10, 2)*100)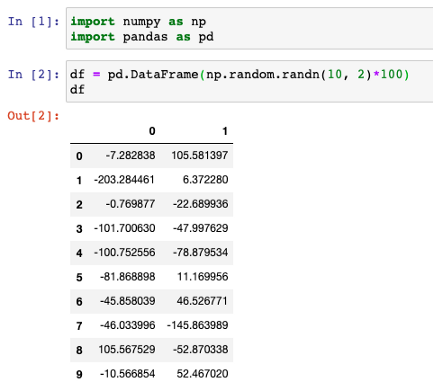
然后,让我们以特定格式输出 DataFrame。
df.style.format("{:.2f}")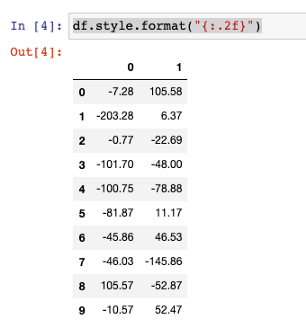
顺便说一句,如果你不太熟悉Python格式化语言,例如表达式{:.2f},那么你可以在这里查看官方文档):https://docs.python.org/3/library/string.html#formatspec
用背景和文本颜色突出显示单元格

我知道,格式化还不够酷。有了CSS,我们可以轻松地做很多事情,比如改变背景颜色和文本颜色。
例如,对于上面显示的同一个 DataFrame,我们希望分别突出显示正数和自然数。如果你对CSS有一些基本的了解,或者只是简单的Google一下,你就会知道下面的属性来设置HTML表格单元格的背景颜色和文本颜色。
background-color: red; color: white让我们编写一个函数来给表格单元格着色。
def highlight_number(row):
return [
'background-color: red; color: white' if cell <= 0
else 'background-color: green; color: white'
for cell in row
]如果单元格的值为负数,我们使用红色作为背景,否则如果是正值,则使用绿色。由于颜色可能有点暗,我们还想将文本颜色改为白色。
然后,我们可以将函数应用于 DataFrame。
df.style.apply(highlight_number)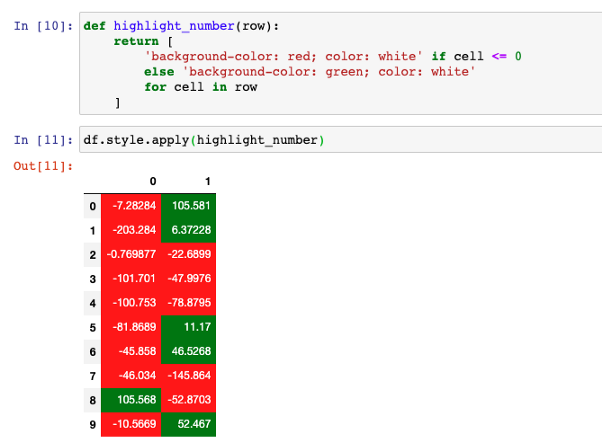
超级酷!现在很明显,我们得到了负数和正数,它们很好地区分开来。
链接样式函数

到目前为止,我们每次只添加一种样式。事实上,我们调用df.style,返回 DataFrame的Styler对象。Styler对象支持链接样式函数。让我们看看另一个更复杂的例子。
比方说,我们想在原始数据框中添加以下样式。
-
用红色突出显示负数,用绿色突出显示正数。
-
格式化数字。
-
使用set_caption()向表添加标题。
-
使表格间隙变大,这样看起来就不会那么挤了。
-
在单元格之间添加白色边框以改善显示效果。
是的,我们可以通过使用链表达式一次性完成所有这些操作。
df.style \
.apply(highlight_number) \
.format('${0:,.2f}') \
.set_caption('A Sample Table') \
.set_properties(padding="20px", border='2px solid white')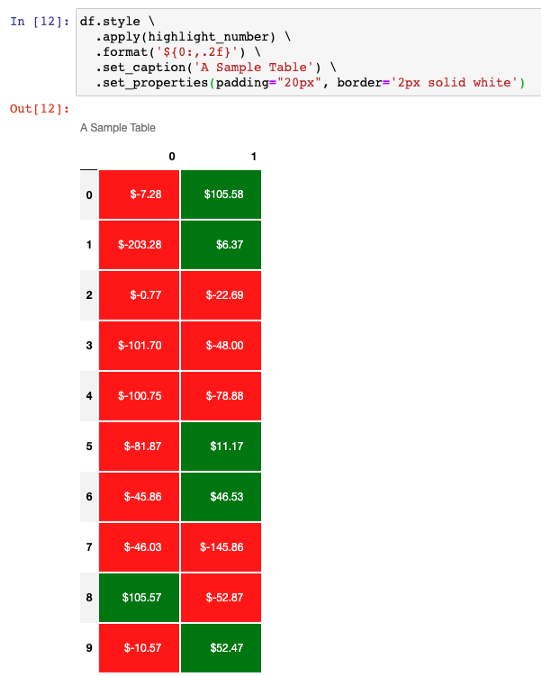
感觉该表可以直接用于某些业务报表
内置突出显示功能

不懂CSS,但还是想炫耀一下?是的,Pandas风格还提供了一些内置的函数,这些函数很酷,但很容易使用。
突出显示函数
让我们使用相同的 DataFrame进行演示。
# 为演示目的生成一个nan值
df.at[1, 1] = None
# 添加样式
df.style \
.highlight_null('lightgray') \
.highlight_max(color='lightgreen') \
.highlight_min(color='pink')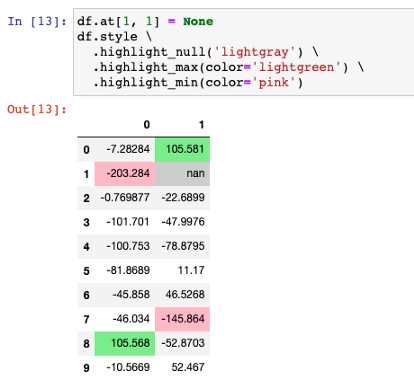
看,用你喜欢的颜色来突出显示空值、最小值和最大值是很容易的。我建议使用浅色,因为文本颜色总是黑色的。
渐变色背景
Pandas风格还支持使用cmap为表格背景着色。当我们想将数值数据可视化时,这是非常有用的。
df = pd.DataFrame(np.random.randn(10, 2))
df.style \
.background_gradient(cmap='Blues')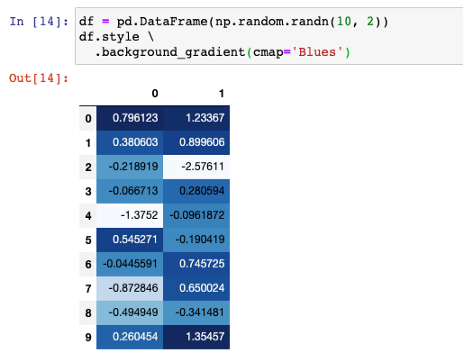
所以,背景色是渐变色的取决于数值。请注意,“蓝调”是Pandas支持的cmap之一。如果你想知道其他支持什么,那么下面的Matplotlib文档页是一个很好的参考。
https://matplotlib.org/3.1.0/tutorials/colors/colormaps.html#sequential
折线条形图
这是另一个内置的超级酷的函数。它可以在每个单元格的背景中生成条形图,以指示它们的值。让我们使用上面的 DataFrame。
df.style.bar()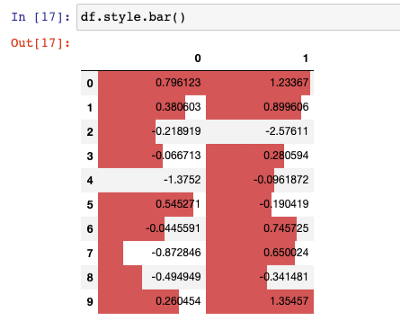
当然,我们对条形图的默认样式并不满意。让我们改进一下演示。
df.style \
.format('{:.2f}') \
.bar(align='mid', color=['#FCC0CB', '#90EE90']) \
.set_caption('A Sample Table with Bar Chart') \
.set_properties(padding="15px", border='2px solid white', width='300px')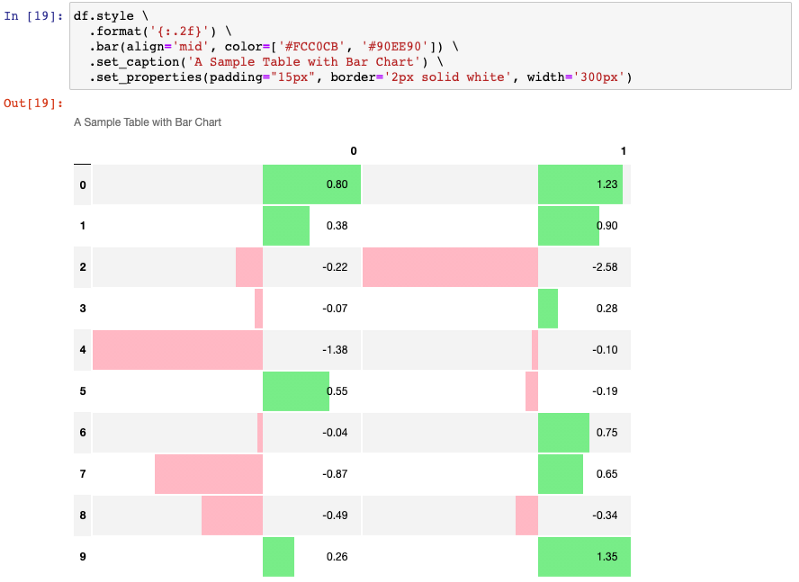
你能相信这仍然是你熟悉的“Pandas DataFrame"吗?
让我简单地解释一下bar()方法中的参数。color参数支持单个字符串或元组,当它是元组时,第一种颜色将用于为负值着色,第二种颜色用于为正值着色。因为我们使用两种颜色,所以我们需要将条形图设置为在单元格中间对齐。
Sparklines-一个直线柱状图

我可以到此为止,但我想展示我发现的另一个非常有趣的库,叫做Sparklines。
你可以使用pip安装库。
pip install sparklines然后,让我们导入这个库并创建另一个示例 DataFrame以供演示。
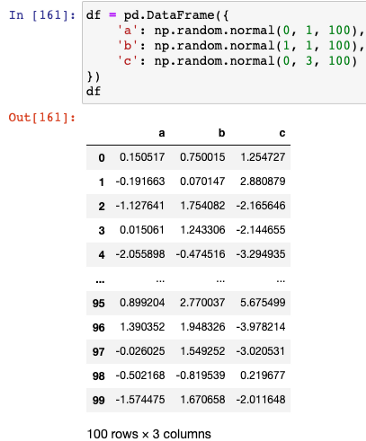
from sparklines import sparklines
df = pd.DataFrame({
'a': np.random.normal(0, 1, 100),
'b': np.random.normal(1, 1, 100),
'c': np.random.normal(0, 3, 100)
})
Sparklines的功能很简单。它可以使用Unicode字符串生成条形图,例如▁、▂、▃。为了确保条形图的顺序正确,并使其成为一个柱状图,我们需要先使用NumPy来准备值来生成直方图值。
def sparkline_dist(data):
hist = np.histogram(data, bins=10)[0]
dist_strings = ''.join(sparklines(hist))
return dist_strings对于每一列,我们可以使用迷你图生成直方图。
[sparkline_dist(df[col]) for col in df.columns]
最后,我们可以将字符串与其他统计数据放在一起,以生成更好的报告。
df_stats = df.agg(['mean', 'std']).transpose()
df_stats['histogram'] = sl_list
df_stats.style \
.format('{:.2f}', subset=['mean', 'std']) \
.set_caption('A Sample Table with Sparklines Distributions') \
.set_properties(padding="15px", border='2px solid white')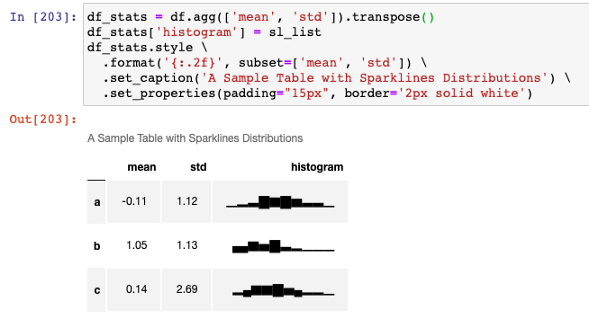
总结

在本文中,我向你演示了Pandas样式包中的所有主要方法。我们可以设置值的格式,给背景着色,用定制的CSS属性来改进演示。
原文链接:https://towardsdatascience.com/make-your-pandas-dataframe-output-report-ready-a9440f6045c6
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e4%bd%bf%e7%94%a8pandas-dataframe%e8%be%93%e5%87%ba%e6%8a%a5%e5%91%8a/
