
作者|Mate Pocs
编译|VK
来源|Towards Data Science
Word2vec绝对是我在自然语言处理研究中遇到的最有趣的概念。想象一下,有一种算法可以成功地模拟理解单词的含义及其在语言中的功能,它可以在不同的主题内来衡量单词之间的接近程度。
我认为可视化地表示word2vec向量会很有趣:本质上,我们可以获取国家或城市的向量,应用主成分分析来减少维度,并将它们放在二维图表上。然后,我们可以观察可视化的结果。
在本文中,我们将:
-
从广义上讨论word2vec理论;
-
下载原始的预训练向量;
-
看看一些有趣的应用程序:比如对一些单词进行算术运算,比如著名的king-man+woman=queen等式
-
根据word2vec向量看看我们能多精确地来绘制欧洲的首都。
word2vec的原始研究论文和预训练模型来自2013年,考虑到NLP文献的扩展速度,目前它是老技术。较新的方法包括GloVe(更快,可以在较小的语料库上训练)和fastText(能够处理字符级的n-gram)。
Quick Word2Vec简介
自然语言处理的核心概念之一是如何量化单词和表达式,以便能够在模型环境中使用它们。语言元素到数值表示的这种映射称为词嵌入。
Word2vec是一个词嵌入过程。这个概念相对简单:通过一个句子一个句子地在语料库中循环去拟合一个模型,根据预先定义的窗口中的相邻单词预测当前单词。
为此,它使用了一个神经网络,但实际上最后我们并不使用预测的结果。一旦模型被保存,我们只保存隐藏层的权重。在我们将要使用的原始模型中,有300个权重,因此每个单词都由一个300维向量表示。
请注意,两个单词不必彼此接近的地方才被认为是相似的。如果两个词从来没有出现在同一个句子中,但它们通常被相同的包围,那么可以肯定它们有相似的意思。
word2vec中有两种建模方法:skip-gram和continuous bag of words,这两种方法都有各自的优点和对某些超参数的敏感性……但是你知道吗?我们将不拟合我们自己的模型,所以我不会花时间在它上面。
当然,你得到的词向量取决于你训练模型的语料库。一般来说,你确实需要一个庞大的语料库,有维基百科上训练过的版本,或者来自不同来源的新闻文章。我们将要使用的结果是在Google新闻上训练出来的。
如何下载和安装
首先,你需要下载预训练word2vec向量。你可以从各种各样的模型中进行选择,这些模型是针对不同类型的文档进行训练的。
我用的是最初的模型,在Google新闻上受过训练,你可以从很多来源下载,只需搜索“Google News vectors negative 300”。或者, 在这里下载:https://github.com/mmihaltz/word2vec-GoogleNews-vectors。
注意,这个文件是1.66gb,但它包含了30亿字的300维表示。
当谈到在Python中使用word2vec时,再一次,你有很多包可供选择,我们将使用gensim库。假设文件保存在word2vec_pretrained文件夹中,可以用Python加载,代码如下所示:
from gensim.models.keyedvectors import KeyedVectors
word_vectors = KeyedVectors.load_word2vec_format(\
'./word2vec_pretrained/GoogleNews-vectors-negative300.bin.gz', \
binary = True, limit = 1000000)limit参数定义了要导入的单词数,100万对于我来说已经足够了。
探索Word2vec
现在我们已经有了word2vec向量,我们可以查看它的一些相关有趣的用法。
首先,你可以实际检查任何单词的向量表示:
word_vectors['dog']结果,正如我们预期的,是一个300维的向量,并且这个向量很难解释。我们通过对这些向量的加和减来计算新向量,然后计算余弦相似度来找到最接近的匹配词。
你可以使用most_similar函数找到同义词,topn参数定义要列出的单词数:
word_vectors.most_similar(positive = ['nice'], topn = 5)结果
[('good', 0.6836092472076416),
('lovely', 0.6676311492919922),
('neat', 0.6616737246513367),
('fantastic', 0.6569241285324097),
('wonderful', 0.6561347246170044)]现在,你可能认为用类似的方法,你也可以找到反义词,你可能认为只需要把“nice”这个词作为negative输入。但结果却是
[('J.Gordon_###-###', 0.38660115003585815),
('M.Kenseth_###-###', 0.35581791400909424),
('D.Earnhardt_Jr._###-###', 0.34227001667022705),
('G.Biffle_###-###', 0.3420777916908264),
('HuMax_TAC_TM', 0.3141660690307617)]这些词实际上表示离“nice”这个词最远的词。
使用doesnt_match函数可以找出异常词:
word_vectors.doesnt_match(
['Hitler', 'Churchill', 'Stalin', 'Beethoven'])返回Beethoven。我想这很方便。
最后,让我们看看一些操作的例子,这些操作通过赋予算法一种虚假的智能感而出名。如果我们想合并father和woman这两个词的向量,并且减去man这个词的向量,代码如下
word_vectors.most_similar(
positive = ['father', 'woman'], negative = ['man'], topn = 1)我们得到:
[('mother', 0.8462507128715515)]脑子先转一转,想象一下我们只有两个维度:亲子关系和性别。“女人”这个词可以用这个向量来表示:[0,1],“男人”是[0,-1],“父亲”是[1,-1],“母亲”是[1,1]。现在,如果我们做同样的运算,我们得到同样的结果。当然,区别在于我们有300个维度,而不是示例中仅有的2个维度,维度的含义几乎无法解释。
在word2vec操作中,有一个著名的性别偏见例子,“doctor”这个词的女性版本过去被计算为“nurse”。我试着复制,但没有得到同样的结果:
word_vectors.most_similar(
positive = ['doctor', 'woman'], negative = ['man'], topn = 1)
[('gynecologist', 0.7093892097473145)]我们得到了妇科医生,所以,我想这可能是进步吧?
好吧,现在我们已经检查了一些基本的函数,让我们来研究我们的可视化吧!
Map函数
首先,我们需要一个Map函数。假设我们有一个要可视化的字符串列表和一个词嵌入,我们希望:
-
找到列表中每个单词的词向量表示;
-
利用主成分分析法将维数降到2;
-
创建散点图,将单词作为每个数据点的标签;
-
另外一个额外的好处是,可以从任何维度“旋转”结果——主成分分析的向量是任意方向的,当我们绘制地理单词时,我们可能想要改变这个方向,看是否可以与现实世界的方向一致。
我们需要以下库:
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
import adjustText列表中不常用的一个库是adjustText,这是一个非常方便的包,它使得在散点图中编写图例变得简单,而不会重叠。对于我来说,找到这个解决方案非常困难,而且据我所知,在matplotlib或seaborn中没有办法做到这一点。
无需进一步说明,此函数将完全满足我们的需要:
def plot_2d_representation_of_words(
word_list,
word_vectors,
flip_x_axis = False,
flip_y_axis = False,
label_x_axis = "x",
label_y_axis = "y",
label_label = "city"):
pca = PCA(n_components = 2)
word_plus_coordinates=[]
for word in word_list:
current_row = []
current_row.append(word)
current_row.extend(word_vectors[word])
word_plus_coordinates.append(current_row)
word_plus_coordinates = pd.DataFrame(word_plus_coordinates)
coordinates_2d = pca.fit_transform(
word_plus_coordinates.iloc[:,1:300])
coordinates_2d = pd.DataFrame(
coordinates_2d, columns=[label_x_axis, label_y_axis])
coordinates_2d[label_label] = word_plus_coordinates.iloc[:,0]
if flip_x_axis:
coordinates_2d[label_x_axis] = \
coordinates_2d[label_x_axis] * (-1)
if flip_y_axis:
coordinates_2d[label_y_axis] = \
coordinates_2d[label_y_axis] * (-1)
plt.figure(figsize = (15,10))
p1=sns.scatterplot(
data=coordinates_2d, x=label_x_axis, y=label_y_axis)
x = coordinates_2d[label_x_axis]
y = coordinates_2d[label_y_axis]
label = coordinates_2d[label_label]
texts = [plt.text(x[i], y[i], label[i]) for i in range(len(x))]
adjustText.adjust_text(texts)现在是测试函数的时候了。我画出了欧洲国家的首都。你可以使用任何列表,例如总统或其他历史人物的名字,汽车品牌,烹饪原料,摇滚乐队等等,只要在word_list参数中传递它。很有意思的是看到一堆堆的东西在两个轴后面形成一个意思。
如果你想重现结果,以下是城市:
capitals = [
'Amsterdam', 'Athens', 'Belgrade', 'Berlin', 'Bern',
'Bratislava', 'Brussels', 'Bucharest', 'Budapest',
'Chisinau', 'Copenhagen','Dublin', 'Helsinki', 'Kiev',
'Lisbon', 'Ljubljana', 'London', 'Luxembourg','Madrid',
'Minsk', 'Monaco', 'Moscow', 'Nicosia', 'Nuuk', 'Oslo',
'Paris','Podgorica', 'Prague', 'Reykjavik', 'Riga',
'Rome', 'San_Marino', 'Sarajevo','Skopje', 'Sofia',
'Stockholm', 'Tallinn', 'Tirana', 'Vaduz', 'Valletta',
'Vatican', 'Vienna', 'Vilnius', 'Warsaw', 'Zagreb']假设你仍然有我们在上一节中创建的word_vectors对象,可以这样调用函数:
plot_2d_representation_of_words(
word_list = capitals,
word_vectors = word_vectors,
flip_y_axis = True)(翻转y轴是为了创建更像真实贴图的表示。)
结果是:
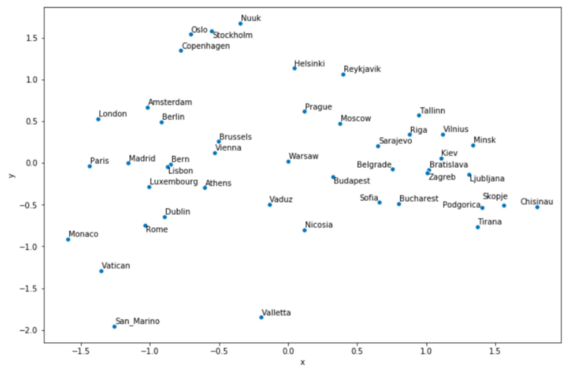
我不知道你的感受,当我第一次看到地图的时候,我真不敢相信结果会有多好!是的,当然,你看得越久,你发现的“错误”就越多,一个不好的结果就是莫斯科离东方的距离并不像它应该的那么远……尽管如此,东西方几乎完全分离,斯堪的纳维亚和波罗的海国家被很好地组合在一起,意大利周围的首都也是如此。
需要强调的是,这绝不是纯粹的地理位置,例如,雅典离西方很远,但这是有原因的。让我们回顾一下上面的地图是如何导出的,这样我们就可以充分理解它了:
-
谷歌的一组研究人员训练了一个庞大的神经网络,根据上下文预测单词;
-
他们将每个单词的权重保存在一个300维的向量表示中;
-
我们计算欧洲各国首都的向量;
-
利用主成分分析法将维数降到2;
-
把计算出的成分放在图表上。
所以,语义的信息不能代表真实地理信息。但我觉得这个尝试很有趣。
参考引用
-
Hobson, L. & Cole, H. & Hannes, H. (2019). Natural Language Processing in Action: Understanding, Analyzing, and Generating Text with Python. Manning Publications, 2019.
原文链接:https://towardsdatascience.com/how-to-draw-a-map-using-python-and-word2vec-e9627b4eae34
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e4%bd%bf%e7%94%a8python%e5%8f%af%e8%a7%86%e5%8c%96word2vec%e7%9a%84%e7%bb%93%e6%9e%9c/
