
作者|Angel Das
编译|VK
来源|Towards Datas Science

介绍
人工神经网络(ANNs)是机器学习技术的高级版本,是深度学习的核心。人工神经网络涉及以下概念。输入输出层、隐藏层、隐藏层下的神经元、正向传播和反向传播。
简单地说,输入层是一组自变量,输出层代表最终的输出(因变量),隐藏层由神经元组成,在那里应用方程和激活函数。前向传播讨论方程的具体形式以获得最终输出,而反向传播则计算梯度下降以相应地更新参数。有关操作流程的更多信息,请参阅下面的文章。
https://towardsdatascience.com/introduction-to-artificial-neural-networks-for-beginners-2d92a2fb9984
深层神经网络
当一个ANN包含一个很深的隐藏层时,它被称为深度神经网络(DNN)。DNN具有多个权重和偏差项,每一个都需要训练。反向传播可以确定如何调整所有神经元的每个权重和每个偏差项,以减少误差。除非网络收敛到最小误差,否则该过程将重复。
算法步骤如下:
- 得到训练和测试数据以训练和验证模型的输出。所有涉及相关性、离群值处理的统计假设仍然有效,必须加以处理。
- 输入层由自变量及其各自的值组成。训练集分为多个batch。训练集完整的训练完称为一个epoch。epoch越多,训练时间越长
- 每个batch被传递到输入层,输入层将其发送到第一个隐藏层。计算该层中所有神经元的输出(对于每一个小批量)。结果被传递到下一层,这个过程重复,直到我们得到最后一层的输出,即输出层。这是前向传播:就像做预测一样,除了所有中间结果都会被保留,因为它们是反向传播所需要的
- 然后使用损失函数测量网络的输出误差,该函数将期望输出与网络的实际输出进行比较
- 计算了每个参数对误差项的贡献
- 该算法根据学习速率(反向传播)执行梯度下降来调整权重和参数,并且该过程会重复进行
重要的是随机初始化所有隐藏层的权重,否则训练将失败。
例如,如果将所有权重和偏移初始化为零,则给定层中的所有神经元将完全相同,因此反向传播将以完全相同的方式影响它们,因此它们将保持相同。换句话说,尽管每层有数百个神经元,但你的模型将表现得好像每层只有一个神经元:它不会太聪明。相反,如果你随机初始化权重,你就打破了对称性,允许反向传播来训练不同的神经元
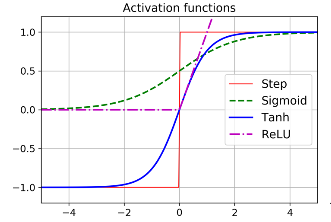
激活函数
激活函数是梯度下降的关键。梯度下降不能在平面上移动,因此有一个定义良好的非零导数是很重要的,以使梯度下降在每一步都取得进展。Sigmoid通常用于logistic回归问题,但是,也有其他流行的选择。
双曲正切函数
这个函数是S形的,连续的,输出范围在-1到+1之间。在训练开始时,每一层的输出或多或少都以0为中心,因此有助于更快地收敛。
整流线性单元
对于小于0的输入,它是不可微的。对于其他情况,它产生良好的输出,更重要的是具有更快的计算速度。函数没有最大输出,因此在梯度下降过程中可能出现的一些问题得到了很好的处理。
为什么我们需要激活函数?
假设f(x)=2x+5和g(x)=3x-1。两个输入项的权重是不同的。在链接这些函数时,我们得到的是,f(g(x))=2(3x-1)+5=6x+3,这又是一个线性方程。非线性的缺失表现为深层神经网络中等价于一个线性方程。这种情况下的复杂问题空间无法处理。
损失函数
在处理回归问题时,我们不需要为输出层使用任何激活函数。在训练回归问题时使用的损失函数是均方误差。然而,训练集中的异常值可以用平均绝对误差来处理。Huber损失也是基于回归的任务中广泛使用的误差函数。
当误差小于阈值t(大多为1)时,Huber损失是二次的,但当误差大于t时,Huber损失是线性的。与均方误差相比,线性部分使其对异常值不太敏感,并且二次部分比平均绝对误差更快地收敛和更精确的数字。
分类问题通常使用二分类交叉熵、多分类交叉熵或稀疏分类交叉熵。二分类交叉熵用于二分类,而多分类或稀疏分类交叉熵用于多类分类问题。你可以在下面的链接中找到有关损失函数的更多详细信息。
注:分类交叉熵用于因变量的one-hot表示,当标签作为整数提供时,使用稀疏分类交叉熵。
用Python开发ANN
我们将使用Kaggle的信用数据开发一个使用Jupyter Notebook的欺诈检测模型。同样的方法也可以在google colab中实现。
数据集包含2013年9月欧洲持卡人通过信用卡进行的交易。此数据集显示两天内发生的交易,其中284807笔交易中有492宗欺诈。数据集高度不平衡,正类(欺诈)占所有交易的0.172%。
https://www.kaggle.com/mlg-ulb/creditcardfraud
import tensorflow as tf
print(tf.__version__)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
from sklearn import preprocessing
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, BatchNormalization
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score, precision_recall_curve, auc
import matplotlib.pyplot as plt
from tensorflow.keras import optimizers
import seaborn as sns
from tensorflow import keras
import random as rn
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
PYTHONHASHSEED=0
tf.random.set_seed(1234)
np.random.seed(1234)
rn.seed(1254)数据集由以下属性组成。时间、主要成分、金额和类别。更多信息请访问Kaggle网站。
file = tf.keras.utils
raw_df = pd.read_csv(‘https://storage.googleapis.com/download.tensorflow.org/data/creditcard.csv')
raw_df.head()由于大多数属性都是主成分,所以相关性总是0。唯一可能出现异常值的列是amount。下面简要介绍一下这方面的统计数据。
count 284807.00
mean 88.35
std 250.12
min 0.00
25% 5.60
50% 22.00
75% 77.16
max 25691.16
Name: Amount, dtype: float64
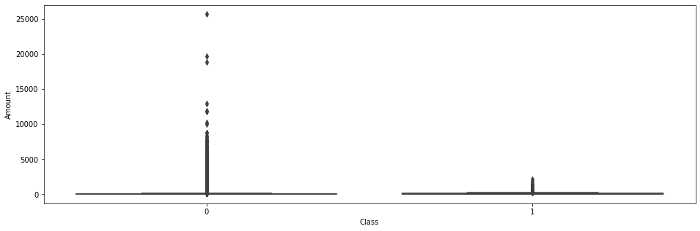
异常值对于检测欺诈行为至关重要,因为基本假设是,较高的交易量可能是欺诈活动的迹象。然而,箱线图并没有揭示任何具体的趋势来验证上述假设。
准备输入输出和训练测试数据
X_data = credit_data.iloc[:, :-1]
y_data = credit_data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size = 0.2, random_state = 7)
X_train = preprocessing.normalize(X_train)数量和主成分分析变量使用不同的尺度,因此数据集是标准化的。标准化在梯度下降中起着重要作用。标准化数据的收敛速度要快得多。
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)输出:
(227845, 29) #记录数x列数
(56962, 29)
(227845,)
(56962,)开发神经网络层
上面的输出表明我们有29个自变量要处理,因此输入层的形状是29。任何人工神经网络架构的一般结构概述如下。
+----------------------------+----------------------------+
| Hyper Parameter | Binary Classification |
+----------------------------+----------------------------+
| # input neurons | One per input feature |
| # hidden layers | Typically 1 to 5 |
| # neurons per hidden layer | Typically 10 to 100 |
| # output neurons | 1 per prediction dimension |
| Hidden activation | ReLU, Tanh, sigmoid |
| Output layer activation | Sigmoid |
| Loss function | Binary Cross Entropy |
+----------------------------+----------------------------+
+-----------------------------------+----------------------------+
| Hyper Parameter | Multiclass Classification |
+-----------------------------------+----------------------------+
| # input neurons | One per input feature |
| # hidden layers | Typically 1 to 5 |
| # neurons per hidden layer | Typically 10 to 100 |
| # output neurons | 1 per prediction dimension |
| Hidden activation | ReLU, Tanh, sigmoid |
| Output layer activation | Softmax |
| Loss function | "Categorical Cross Entropy |
| Sparse Categorical Cross Entropy" | |
+-----------------------------------+----------------------------+Dense函数的输入
- units — 输出尺寸
- activation — 激活函数,如果未指定,则不使用任何内容
- use_bias — 布尔值,如果使用偏置项
- kernel_initializer — 核权重的初始值设定项
- bias_initializer —偏置向量的初始值设定项。
model = Sequential(layers=None, name=None)
model.add(Dense(10, input_shape = (29,), activation = 'tanh'))
model.add(Dense(5, activation = 'tanh'))
model.add(Dense(1, activation = 'sigmoid'))
sgd = optimizers.Adam(lr = 0.001)
model.compile(optimizer = sgd, loss = 'binary_crossentropy', metrics=['accuracy'])体系结构摘要
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 300
_________________________________________________________________
dense_1 (Dense) (None, 5) 55
_________________________________________________________________
dense_2 (Dense) (None, 1) 6
=================================================================
Total params: 361
Trainable params: 361
Non-trainable params: 0
_________________________________________________________________让我们试着理解上面的输出(输出说明使用两个隐藏层提供):
- 我们创建了一个具有一个输入、两个隐藏和一个输出层的神经网络
- 输入层有29个变量和10个神经元。所以权重矩阵的形状是10 x 29,而偏置矩阵的形状是10 x 1
- 第1层参数总数=10 x 29+10 x 1=300
- 第一层有10个输出值,使用tanh作为激活函数。第二层有5个神经元和10个输入,因此权重矩阵为5×10,偏置矩阵为5×1
- 第2层总参数=5 x 10+5 x 1=55
- 最后,输出层有一个神经元,但是它有5个不同于隐藏层2的输入,并且有一个偏置项,因此神经元的数量=5+1=6
model.fit(X_train, y_train.values, batch_size = 2000, epochs = 20, verbose = 1)
Epoch 1/20
114/114 [==============================] - 0s 2ms/step - loss: 0.3434 - accuracy: 0.9847
Epoch 2/20
114/114 [==============================] - 0s 2ms/step - loss: 0.1029 - accuracy: 0.9981
Epoch 3/20
114/114 [==============================] - 0s 2ms/step - loss: 0.0518 - accuracy: 0.9983
Epoch 4/20
114/114 [==============================] - 0s 2ms/step - loss: 0.0341 - accuracy: 0.9986
Epoch 5/20
114/114 [==============================] - 0s 2ms/step - loss: 0.0255 - accuracy: 0.9987
Epoch 6/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0206 - accuracy: 0.9988
Epoch 7/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0174 - accuracy: 0.9988
Epoch 8/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0152 - accuracy: 0.9988
Epoch 9/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0137 - accuracy: 0.9989
Epoch 10/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0125 - accuracy: 0.9989
Epoch 11/20
114/114 [==============================] - 0s 2ms/step - loss: 0.0117 - accuracy: 0.9989
Epoch 12/20
114/114 [==============================] - 0s 2ms/step - loss: 0.0110 - accuracy: 0.9989
Epoch 13/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0104 - accuracy: 0.9989
Epoch 14/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0099 - accuracy: 0.9989
Epoch 15/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0095 - accuracy: 0.9989
Epoch 16/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0092 - accuracy: 0.9989
Epoch 17/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0089 - accuracy: 0.9989
Epoch 18/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0087 - accuracy: 0.9989
Epoch 19/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0084 - accuracy: 0.9989
Epoch 20/20
114/114 [==============================] - 0s 1ms/step - loss: 0.0082 - accuracy: 0.9989评估输出
X_test = preprocessing.normalize(X_test)
results = model.evaluate(X_test, y_test.values)
1781/1781 [==============================] - 1s 614us/step - loss: 0.0086 - accuracy: 0.9989用Tensor Board分析学习曲线
TensorBoard是一个很好的交互式可视化工具,可用于查看训练期间的学习曲线、比较多个运行的学习曲线、分析训练指标等。此工具随TensorFlow自动安装。
import os
root_logdir = os.path.join(os.curdir, “my_logs”)
def get_run_logdir():
import time
run_id = time.strftime(“run_%Y_%m_%d-%H_%M_%S”)
return os.path.join(root_logdir, run_id)
run_logdir = get_run_logdir()
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
model.fit(X_train, y_train.values, batch_size = 2000, epochs = 20, verbose = 1, callbacks=[tensorboard_cb])
%load_ext tensorboard
%tensorboard --logdir=./my_logs --port=6006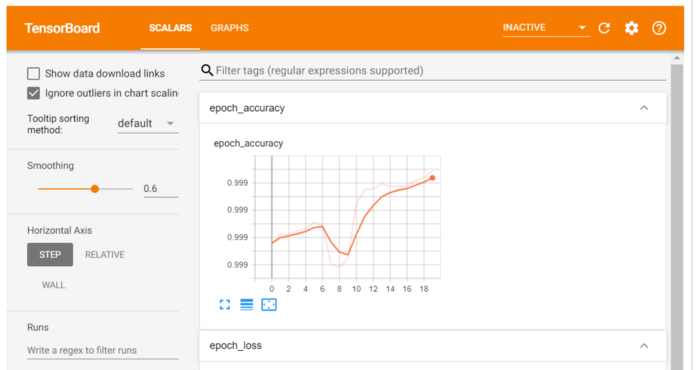
超参调节
如前所述,对于一个问题空间,有多少隐藏层或多少神经元最适合,并没有预定义的规则。我们可以使用随机化searchcv或GridSearchCV来超调一些参数。可微调的参数概述如下:
- 隐藏层数
- 隐藏层神经元
- 优化器
- 学习率
- epoch
声明函数以开发模型
def build_model(n_hidden_layer=1, n_neurons=10, input_shape=29):
# 创建模型
model = Sequential()
model.add(Dense(10, input_shape = (29,), activation = 'tanh'))
for layer in range(n_hidden_layer):
model.add(Dense(n_neurons, activation="tanh"))
model.add(Dense(1, activation = 'sigmoid'))
# 编译模型
model.compile(optimizer ='Adam', loss = 'binary_crossentropy', metrics=['accuracy'])
return model使用包装类克隆模型
from sklearn.base import clone
keras_class = tf.keras.wrappers.scikit_learn.KerasClassifier(build_fn = build_model,nb_epoch = 100,
batch_size=10)
clone(keras_class)
keras_class.fit(X_train, y_train.values)创建随机搜索网格
from scipy.stats import reciprocal
from sklearn.model_selection import RandomizedSearchCV
param_distribs = {
“n_hidden_layer”: [1, 2, 3],
“n_neurons”: [20, 30],
# “learning_rate”: reciprocal(3e-4, 3e-2),
# “opt”:[‘Adam’]
}
rnd_search_cv = RandomizedSearchCV(keras_class, param_distribs, n_iter=10, cv=3)
rnd_search_cv.fit(X_train, y_train.values, epochs=5)检查最佳参数
rnd_search_cv.best_params_
{'n_neurons': 30, 'n_hidden_layer': 3}
rnd_search_cv.best_score_
model = rnd_search_cv.best_estimator_.model优化器也应该微调,因为它们影响梯度下降、收敛和学习速率的自动调整。
- Adadelta -Adadelta是Adagrad的一个更健壮的扩展,它基于梯度更新的移动窗口来调整学习速率,而不是累积所有过去的梯度
- 随机梯度下降-常用。需要使用搜索网格微调学习率
- Adagrad-对于所有参数和其他优化器的每个周期,学习速率都是恒定的。然而,Adagrad在处理误差函数导数时,会改变每个参数的学习速率“η”,并在每个时间步长“t”处改变
- ADAM-ADAM(自适应矩估计)利用一阶和二阶动量来防止跳越局部极小值,保持了过去梯度的指数衰减平均值
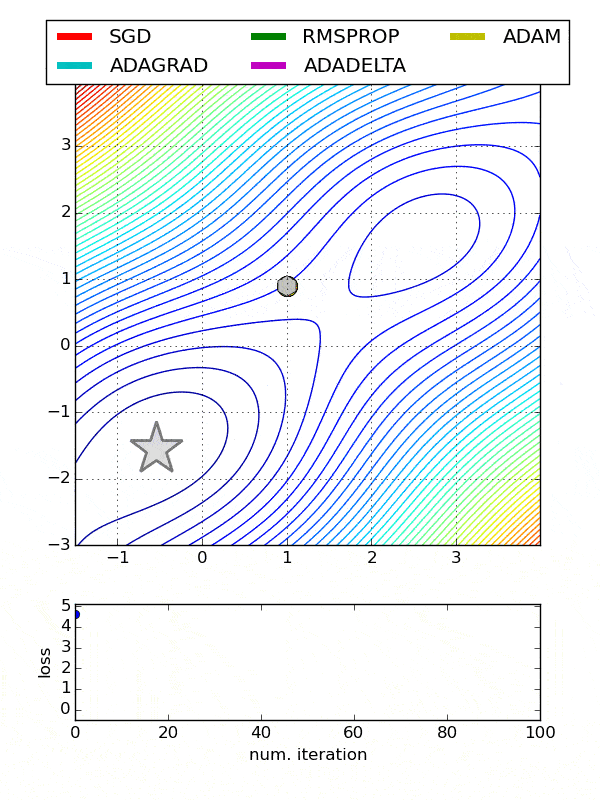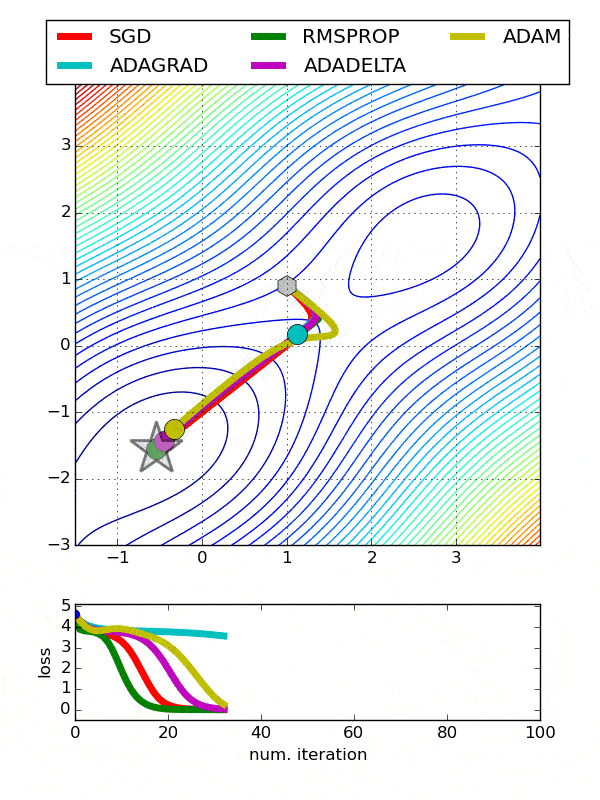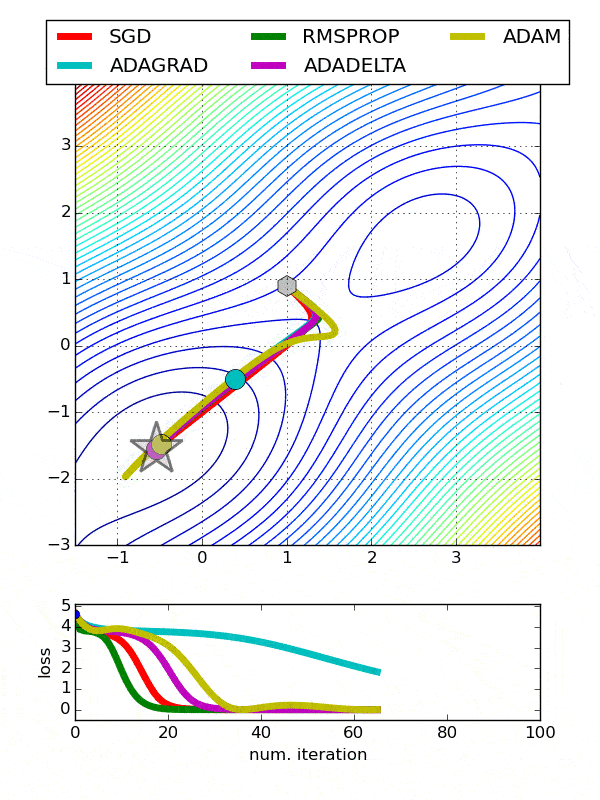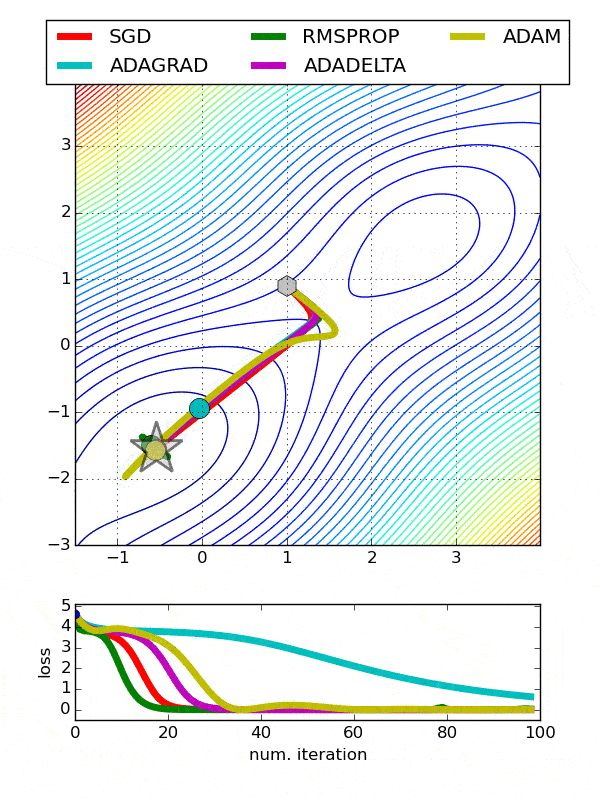
一般来说,通过增加层的数量而不是每层神经元的数量,可以获得更好的输出。
参考文献
Aurélien Géron (2017). Hands-on machine learning with Scikit-Learn and TensorFlow : concepts, tools, and techniques to build intelligent systems. Sebastopol, Ca: O’reilly Media
原文链接:https://towardsdatascience.com/a-beginners-guide-to-artificial-neural-network-using-tensor-flow-keras-41ccd575a876
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e4%bd%bf%e7%94%a8tensorflow%e5%92%8ckeras%e7%9a%84%e5%88%9d%e7%ba%a7%e6%95%99%e7%a8%8b/
