
作者|Samrat Saha
编译|VK
来源|Towards Datas Science
Supervised Contrastive Learning这篇论文在有监督学习、交叉熵损失与有监督对比损失之间进行了大量的讨论,以更好地实现图像表示和分类任务。让我们深入了解一下这篇论文的内容。
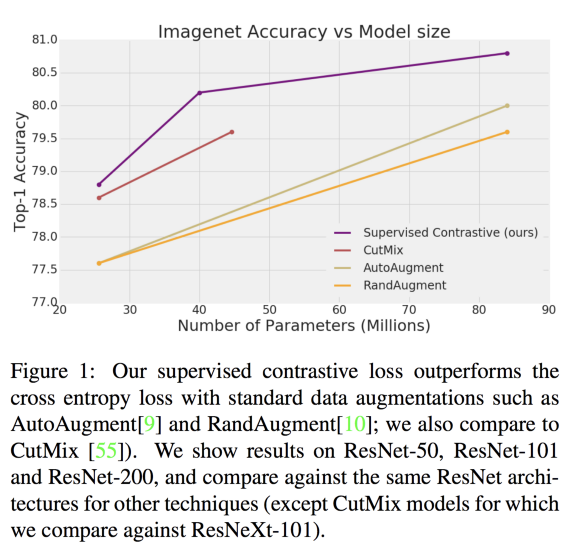
论文指出可以在image net数据集有1%的改进。
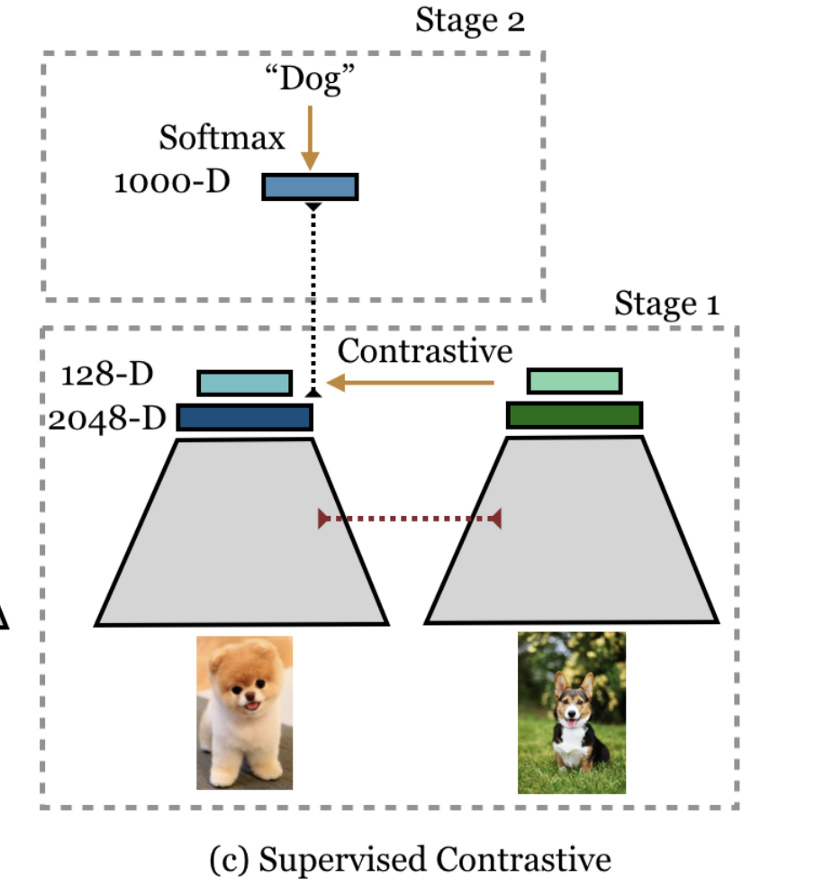
就架构而言,它是一个非常简单的网络resnet 50,具有128维的头部。如果你想,你也可以多加几层。
Code
self.encoder = resnet50()
self.head = nn.Linear(2048, 128)
def forward(self, x):
feat = self.encoder(x)
#需要对128向量进行标准化
feat = F.normalize(self.head(feat), dim=1)
return feat如图所示,训练分两个阶段进行。
-
使用对比损失的训练集(两种变化)
-
冻结参数,然后使用softmax损失在线性层上学习分类器。(来自论文的做法)
以上是不言自明的。
本文的主要内容是了解自监督的对比损失和监督的对比损失。
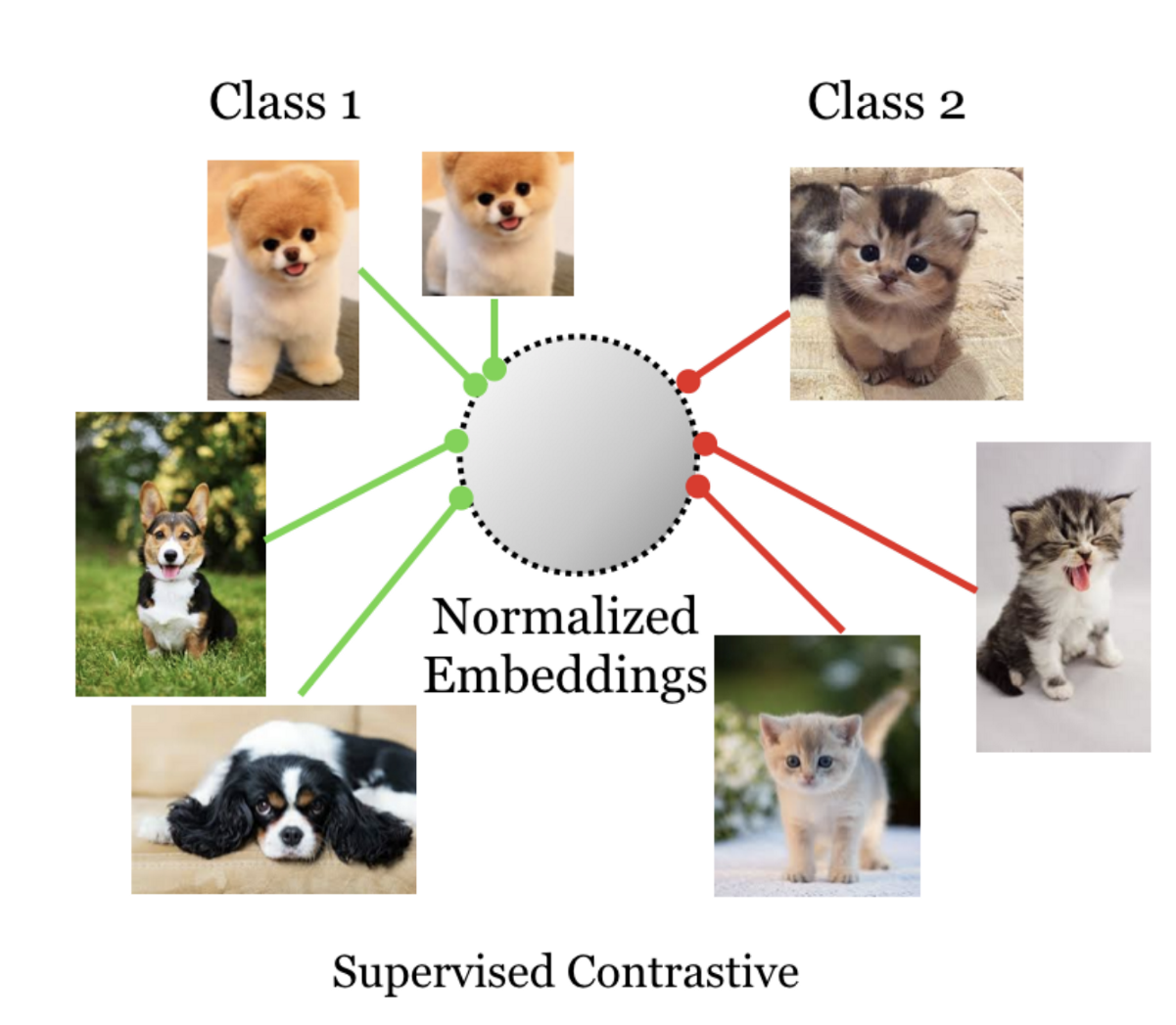
从上面的SCL(监督对比损失)图中可以看出,猫与任何非猫进行对比。这意味着所有的猫都属于同一个标签,都是正数对,任何非猫都是负的。这与三元组数据以及triplet loss的工作原理非常相似。
每一张猫的图片都会被放大,所以即使是从一张猫的图片中,我们也会有很多猫。
监督对比损失的损失函数,虽然看起来很可怕,但其实很简单。
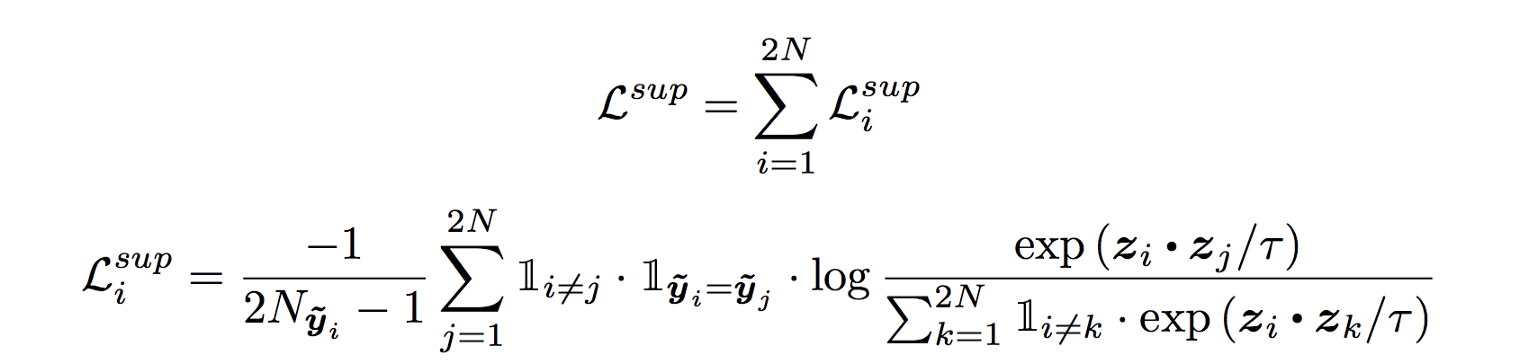
稍后我们将看到一些代码,但首先是非常简单的解释。每个z是标准化的128维向量。
也就是说||z||=1
重申一下线性代数中的事实,如果u和v两个向量正规化,意味着u.v=cos(u和v之间的夹角)
这意味着如果两个标准化向量相同,它们之间的点乘=1
#尝试理解下面的代码
import numpy as np
v = np.random.randn(128)
v = v/np.linalg.norm(v)
print(np.dot(v,v))
print(np.linalg.norm(v))损失函数假设每幅图像都有一个增强版本,每批有N幅图像,生成的batch大小= 2*N
在i!=j,yi=yj时,分子exp(zi.zj)/tau表示一批中所有的猫。将i个第128个dim向量zi与所有的j个第128个dim向量点积。
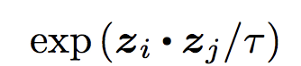
分母是i个猫的图像点乘其他不是猫的图像。取zi和zk的点,使i!=k表示它点乘除它自己以外的所有图像。
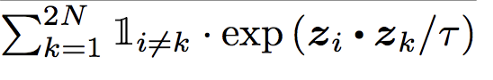
最后,我们取对数概率,并将其与批处理中除自身外的所有猫图像相加,然后除以2*N-1
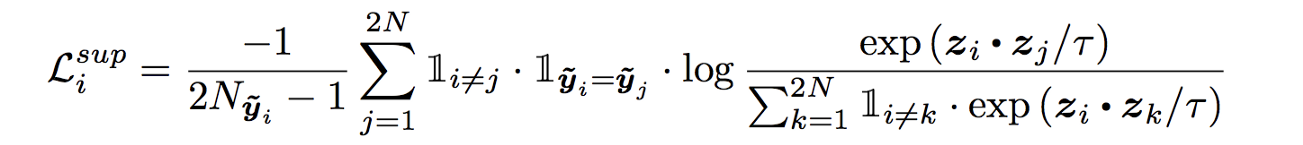
所有图像的总损失和
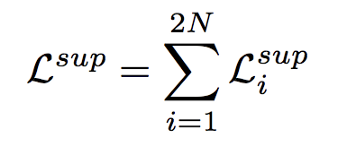
我们使用一些torch代码可以理解上面的内容。
假设我们的批量大小是4,让我们看看如何计算单个批次的损失。
如果批量大小为4,你在网络上的输入将是8x3x224x224,在这里图像的宽度和高度为224。
8=4×2的原因是我们对每个图像总是有一个对比度,因此需要相应地编写一个数据加载程序。
对比损失resnet将输出8×128维的矩阵,你可以分割这些维度以计算批量损失。
#batch大小
bs = 4这个部分可以计算分子
temperature = 0.07
anchor_feature = contrast_feature
anchor_dot_contrast = torch.div(
torch.matmul(anchor_feature, contrast_feature.T),
temperature)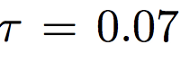
我们的特征形状是8×128,让我们采取3×128矩阵和转置,下面是可视化后的图片。

anchor_feature=3×128和contrast_feature=128×3,结果为3×3,如下所示

如果你注意到所有的对角线元素都是点本身,这实际上我们不想要,我们将删除他们。
线性代数有个性质:如果u和v是两个向量,那么当u=v时,u.v是最大的。因此,在每一行中,如果我们取锚点对比度的最大值,并且取相同值,则所有对角线将变为0。
让我们把维度从128降到2
#bs 1 和 dim 2 意味着 2*1x2
features = torch.randn(2, 2)
temperature = 0.07
contrast_feature = features
anchor_feature = contrast_feature
anchor_dot_contrast = torch.div(
torch.matmul(anchor_feature, contrast_feature.T),
temperature)
print('anchor_dot_contrast=\n{}'.format(anchor_dot_contrast))
logits_max, _ = torch.max(anchor_dot_contrast, dim=1, keepdim=True)
print('logits_max = {}'.format(logits_max))
logits = anchor_dot_contrast - logits_max.detach()
print(' logits = {}'.format(logits))
#输出看看对角线发生了什么
anchor_dot_contrast=
tensor([[128.8697, -12.0467],
[-12.0467, 50.5816]])
logits_max = tensor([[128.8697],
[ 50.5816]])
logits = tensor([[ 0.0000, -140.9164],
[ -62.6283, 0.0000]])创建人工标签和创建适当的掩码进行对比计算。这段代码有点复杂,所以要仔细检查输出。
bs = 4
print('batch size', bs)
temperature = 0.07
labels = torch.randint(4, (1,4))
print('labels', labels)
mask = torch.eq(labels, labels.T).float()
print('mask = \n{}'.format(logits_mask))
#对它进行硬编码,以使其更容易理解
contrast_count = 2
anchor_count = contrast_count
mask = mask.repeat(anchor_count, contrast_count)
#屏蔽self-contrast的情况
logits_mask = torch.scatter(
torch.ones_like(mask),
1,
torch.arange(bs * anchor_count).view(-1, 1),
0
)
mask = mask * logits_mask
print('mask * logits_mask = \n{}'.format(mask))让我们理解输出。
batch size 4
labels tensor([[3, 0, 2, 3]])
#以上的意思是在这批4个品种的葡萄中,我们有3,0,2,3个标签。以防你们忘了我们在这里只做了一次对比所以我们会有3_c 0_c 2_c 3_c作为输入批处理中的对比。
mask =
tensor([[0., 1., 1., 1., 1., 1., 1., 1.],
[1., 0., 1., 1., 1., 1., 1., 1.],
[1., 1., 0., 1., 1., 1., 1., 1.],
[1., 1., 1., 0., 1., 1., 1., 1.],
[1., 1., 1., 1., 0., 1., 1., 1.],
[1., 1., 1., 1., 1., 0., 1., 1.],
[1., 1., 1., 1., 1., 1., 0., 1.],
[1., 1., 1., 1., 1., 1., 1., 0.]])
#这是非常重要的,所以我们创建了mask = mask * logits_mask,它告诉我们在第0个图像表示中,它应该与哪个图像进行对比。
# 所以我们的标签就是标签张量([[3,0,2,3]])
# 我重新命名它们是为了更好地理解张量([[3_1,0_1,2_1,3_2]])
mask * logits_mask =
tensor([[0., 0., 0., 1., 1., 0., 0., 1.],
[0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0.],
[1., 0., 0., 0., 1., 0., 0., 1.],
[1., 0., 0., 1., 0., 0., 0., 1.],
[0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0.],
[1., 0., 0., 1., 1., 0., 0., 0.]])
锚点对比代码
logits = anchor_dot_contrast — logits_max.detach()损失函数
数学回顾
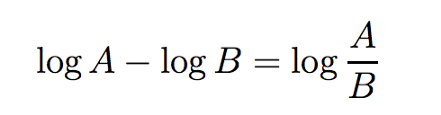
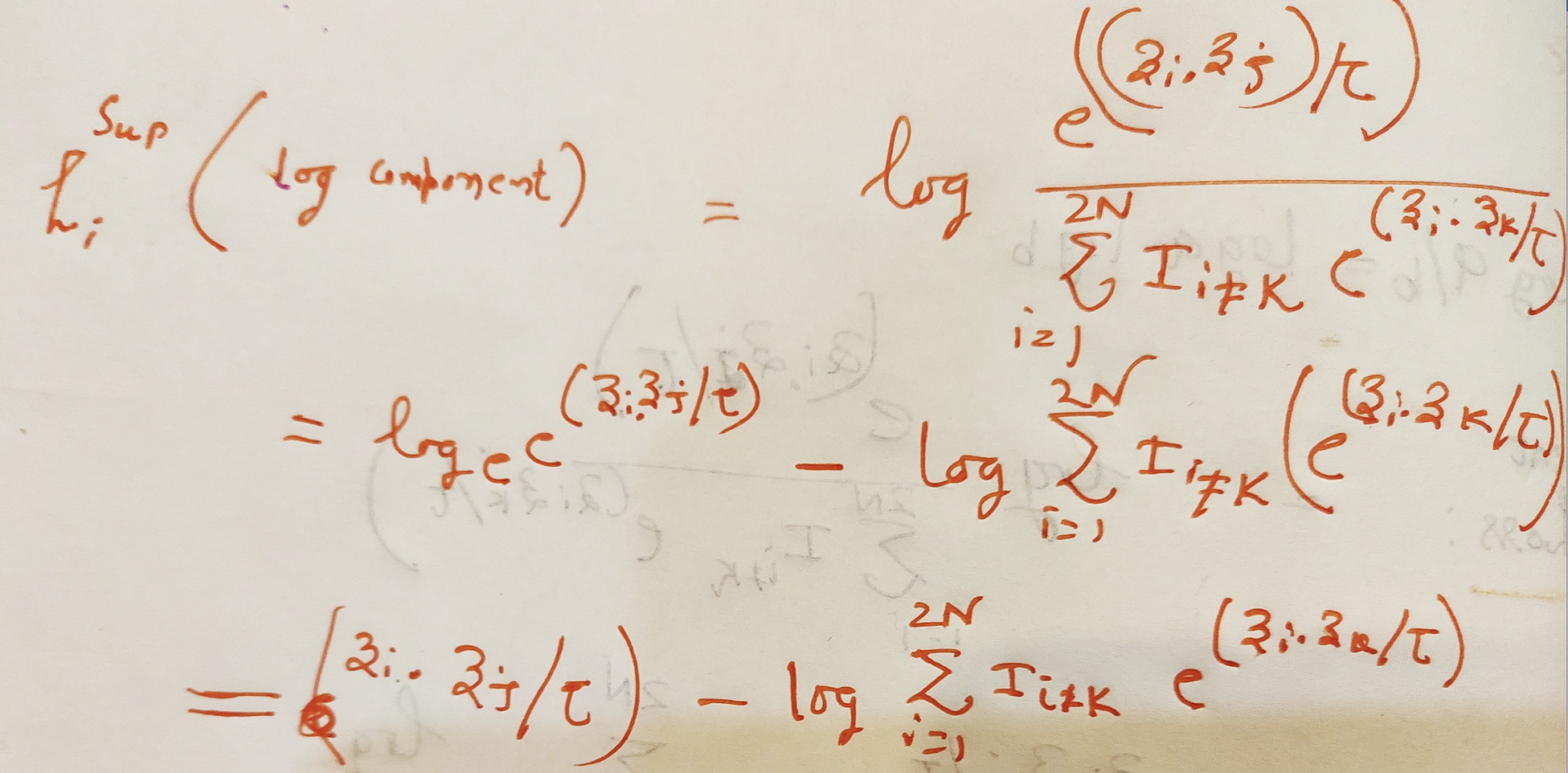
我们已经有了第一部分的点积除以tau作为logits。
#上述等式的第二部分等于torch.log(exp_logits.sum(1, keepdim=True))
exp_logits = torch.exp(logits) * logits_mask
log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))
# 计算对数似然的均值
mean_log_prob_pos = (mask * log_prob).sum(1) / mask.sum(1)
# 损失
loss = - mean_log_prob_pos
loss = loss.view(anchor_count, 4).mean()
print('19. loss {}'.format(loss))我认为这是监督下的对比损失。我认为现在很容易理解自监督的对比损失,因为它比这更简单。
根据本文的研究结果,contrast_count越大,模型越清晰。需要修改contrast_count为2以上,希望你能在上述说明的帮助下尝试。
参考引用
- [1] : Supervised Contrastive Learning
- [2] : Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015.
- [3] : A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen, Simon Kornblith Mohammad Norouzi, Geoffrey Hinton
- [4] : https://github.com/google-research/simclr
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e8%87%aa%e7%9b%91%e7%9d%a3%e5%af%b9%e6%af%94%e6%8d%9f%e5%a4%b1%e5%92%8c%e7%9b%91%e7%9d%a3%e5%af%b9%e6%af%94%e6%8d%9f%e5%a4%b1%e7%9a%84%e5%af%b9%e6%af%94/
