
作者|Irfan Alghani Khalid
编译|VK
来源|Towards Datas Science

假设你要根据给定的查询搜索某个内容。如果你只依靠一个字符串,你就得不到你想要的东西。那么,如何在海量信息中寻找你需要的东西呢?
当然,你需要一个模式来识别你想要查找的字符串。为此,我们可以使用正则表达式(Regular Expression,Regex)。
在本文中,我将向你展示它的概念和应用,以解决数据科学中的问题,特别是使用Python对文本进行预处理。
大纲
我将本文分为两个部分:
-
正则表达式的概念
-
正则表达式的应用
正则表达式的概念
正则表达式,或者我们称之为Regex或RE,是一种特殊类型的字符串,可用于匹配字符串中的术语或单词。
它由特殊字符序列组成,因此我们可以根据需要使用它来匹配任何术语。这里有几个你可以使用的特殊字符,
-
点符号(.)匹配字符串中的任何字符,
-
插入符号(^)与字符串的开头匹配,
-
美元符号($)与字符串的结尾匹配,
-
星号(*)与前一个字符的模式重复零次或多次匹配,
-
加号(+)匹配前一个字符的一个或多个重复,
-
问号(?)匹配上一个字符的0或1个重复,
-
花括号{m,n}将匹配前一个字符的m或n个重复,
-
如果要使用标点符号,可以使用反斜杠(\),但它也是一个特殊字符。例如,为了匹配$,你应该在“\$”这样的字符前面添加一个反斜杠,
-
方括号([])只能用于包含与字符串匹配的某些字符。假设你想找到包含a、i和r的单词,可以使用类似[air]的模式。
回想一下反斜杠有几个特殊的序列。如果你想包含所有的单词或数字而不把它们都写在方括号内,这是非常有用的。你可以使用这些序列,例如,
-
\d将匹配任何数字
-
\s将匹配空白字符
-
\w将匹配任何字符
-
\D匹配除数字外的字符
-
\S匹配除空格外的字符
-
\W匹配除字符外的字符
对于这些特殊字符,你可以根据要提取的术语组合它们。例如,你想要从tweet列表中检索hashtags,可以使用类似“#\w+”的模式。
模式的组合也是可以的,因为有一条规则说,
如果一个模式与一个模式结合,就会产生另一个模式。
正则表达式的应用
在你了解了Regex的概念之后,现在让我们看看如何将其应用于处理文本。
第一种方法是删除我们不用于处理文本的术语。假设你要对tweet集合进行文本挖掘。因此,在挖掘tweet之前,必须先对它们进行预处理,因为我们希望使我们的计算更有效,并避免其中任何无意义的信息。例如,你有这样一条微博,
#Nasional Wapres: Jumlah Orang Miskin Bertambah Gara-Gara Pandemi Covid-19 https://t.co/sJvig4w7LL有几个术语你想删除,比如提及,标签,链接等。在Python中,我们可以使用一个名为sub的方法从re库中删除这些术语。
我们可以将参数设置到函数中,例如regex格式的模式、用于替换术语的字符串,最后是要处理的字符串。
re.sub(pattern, replacement, data)
- pattern: 正则表达式的模式
- replacement: 要替换的字符串
- data: 要处理的变量或字符串通过使用这个函数,我们可以像这样使用它
import re
# 原始微博
tweet = "#Nasional Wapres: Jumlah Orang Miskin Bertambah Gara-Gara Pandemi Covid-19 https://t.co/sJvig4w7LL"
# 使用正则表达式进行预处理
tweet = re.sub("#\w+", "", tweet)
tweet = re.sub("https*.+", "", tweet)
print(tweet)
# 这是结果,
# Wapres: Jumlah Orang Miskin Bertambah Gara-Gara Pandemi Covid-19我想展示的另一个例子是搜索和检索字符串内部的子字符串。在本例中,我将从一个被称为数据科学的“hello world”的数据集中举一个例子。这是泰坦尼克号的数据集。
对于那些不知道的人来说,这是一个数据集,被用来作为Kaggle竞赛的介绍。这项竞赛的目标是根据与乘客相对应的数据来预测乘客是否幸存。数据集看起来像这样

它由几个列组成,描述乘客的人口统计、票价、姓名,以及描述乘客是否幸存的“Survived”列。在本例中,让我们关注“Name”列。让我们看几个例子,
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
5 Moran, Mr. James
6 McCarthy, Mr. Timothy J
7 Palsson, Master. Gosta Leonard
8 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)
9 Nasser, Mrs. Nicholas (Adele Achem)
10 Sandstrom, Miss. Marguerite Rut
11 Bonnell, Miss. Elizabeth
12 Saundercock, Mr. William Henry
13 Andersson, Mr. Anders Johan
14 Vestrom, Miss. Hulda Amanda Adolfina
15 Hewlett, Mrs. (Mary D Kingcome)
16 Rice, Master. Eugene
17 Williams, Mr. Charles Eugene
18 Vander Planke, Mrs. Julius (Emelia Maria Vande...
19 Masselmani, Mrs. Fatima
Name: Name, dtype: object根据上面的样本,你看到它有什么模式吗?如果你详细了解,每个名字都有自己的标题,例如Mr., Mrs., Miss., Master.等等。我们可以将这些名称提取为一个新的函数,称为“Title”。Title包括了.标点符号。因此,我们可以使用模式提取它。
如何从每个名字中提取标题?我们可以使用re库中的一个名为search的函数。使用该函数,我们可以根据给定的模式提取术语。它需要模式和字符串列表。代码是这样的
def get_title(x):
# 搜索匹配的模式
x = re.search('\w*\.', x).group()
# 删除点标点符号以简化分析过程
x = re.sub('\.', '', x)
return x
train['Title'] = train['Name'].apply(get_title)
train = train.drop('Name', axis=1)
train.head()确保在搜索字符串中的一个词之后,用一个名为group的方法链接函数。或者看起来像这样,
# 如果不使用group方法,它将显示
<_sre.SRE_Match object; span=(8, 11), match='Mr.'>如果你做得对,结果会是这样的,
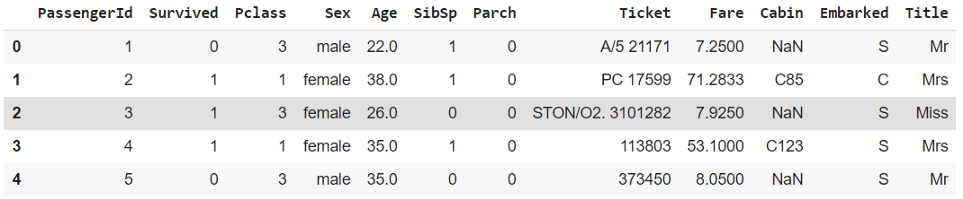
下面是搜索函数及其方法的摘要
re.search(pattern, data)
parameters:
- pattern: 适合我们想要的模式
- data: 我们使用的数据。它可以是字符串或字符串列表
methods:
- group: 它返回一个或更多个字符串。结论
以上是我们如何使用正则表达式来处理使用Python的文本,这样我们就可以通过删除无意义的信息来获得更有意义的结论解。我还向你展示了它的概念和一些应用。我希望这篇文章对你有用。
还有一件事,回想一下我上面的代码,我写的模式就像一个普通的字符串。但是为了确保你编写了一个regex模式,请在引用的模式之前添加’r’字符,如下所示
# 你可以这样写
re.sub("#\w+", "", tweet)
# 或者像这样
re.sub(r"#\w+", "", tweet)就这样,谢谢你。
参考引用
[1]https://docs.python.org/3/library/re.html
[2]https://www.kaggle.com/c/titanic
原文链接:https://towardsdatascience.com/regex-with-python-b4c5ca7c1eba
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/python%e6%ad%a3%e5%88%99%e8%a1%a8%e8%be%be%e5%bc%8f%e7%ae%80%e4%bb%8b/
