

深度估计在现实世界中有许多用途,在机器人、计算机视觉和沉浸式显示中具有实际意义(请参见上图)。我们将把深度估计看作一个多图像问题。多视图(或图像)问题跨越不同的问题域。例如,
虽然作为一个整体,它们在虚拟现实(VR)、机器人和计算机视觉问题上都很重要,但在这个由多部分组成的系列中,我们将重点放在(1)立体视觉上。具体地说,立体视觉技术中深度学习的进展。
人工神经网络在计算机视觉领域有着悠久的历史,为目标检测和分类提供了一个强大的框架。最近,深度学习通过提供网络学习的图像的更深层次的表示,使该领域发生了革命性的变化。最近这一成功的关键组成部分包括简化的网络体系结构,它具有更多的参数和更少的规则,以及新的培训技术,如辍学[3]和L2正则化[4]。
在我们钻研具体的深度学习解决方案之前,让我们首先激发问题并证明为什么使用立体图像对来估计深度。
基于二维信号的三维重建
我们如何从图像中自动计算3D几何图形?图像中的哪些线索提供3D信息?在研究双目(即立体或双目)之前,让我们先考虑一些单视图(也称为单目特性)。
嗯,我们人类是很自然地这么做的。以下是我们用来推断深度信息的几个线索:
- 明暗处理
- 纹理

- 焦点

- 动议
- 透视

- 遮挡

- 其他:
-高光-阴影-轮廓-相互反射-对称-光偏振-…
尽管如此,从单一的视角来看,结构和深度本质上是模棱两可的。让我们直观地看到这一点。
描述我们从光学中心(即,相机位置)看到的P1和P2的模糊性,其作为P1‘和P2’被投影到图像平面上是等价的。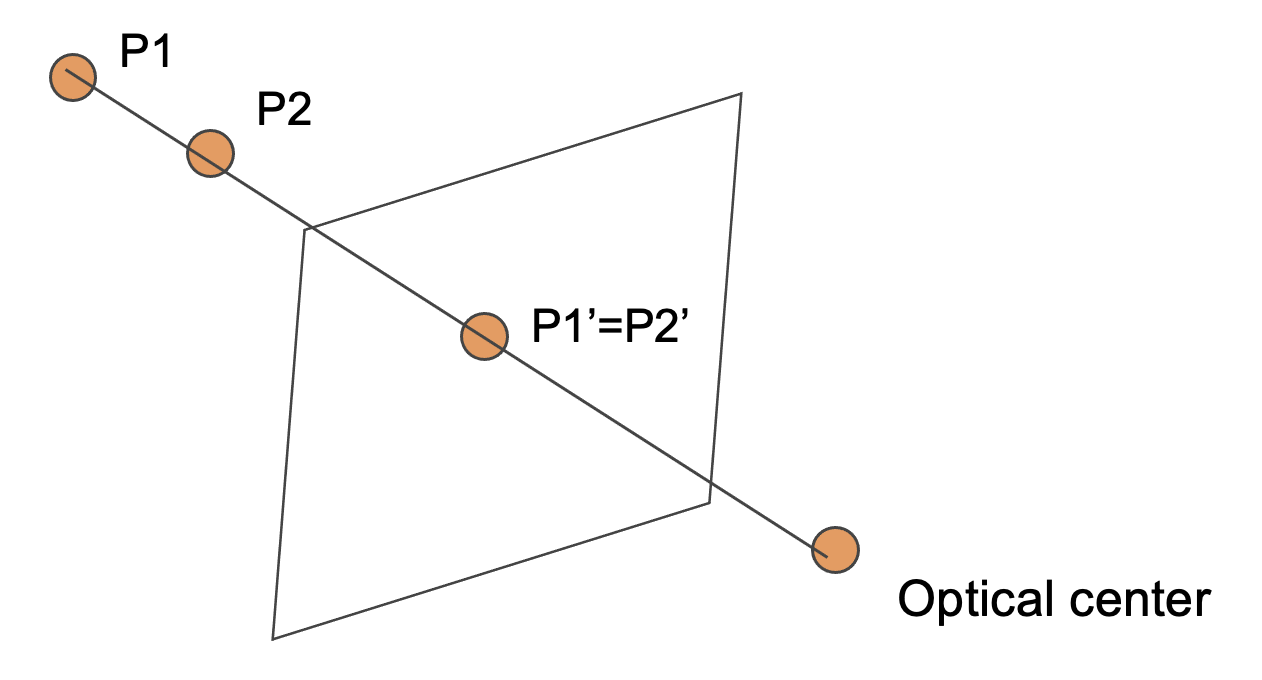
立体声问题
立体视觉系统参考从一对摄像机(即,左和右)同时捕获的两个图像的知识,并且具有假定已知的外部(例如,摄像机的位置)和内在(例如,焦距)的摄像机参数。
立体声在很大程度上是由生物学驱动的(即,使用左眼和右眼同时捕捉视觉信息)。
经典的立体问题包括视差(相机参数)、深度(估计相机之间的距离)、遮挡、自动立体图、运动结构(场景的2D到3D表示)、运动视差、深度贴图生成和纹理贴图。有几种方法可以对问题建模,如上所示。例如,可以使用刚体解算器在球坐标中求解方程。尽管如此,本系列的重点将放在深度学习(DL)解决方案上。
总之,在提供左和右图像的情况下,通过在两个图像中可以看到的世界坐标中的点的匹配对应处从两个图像平面进行三角测量来满足上述模糊性问题。用图形表示: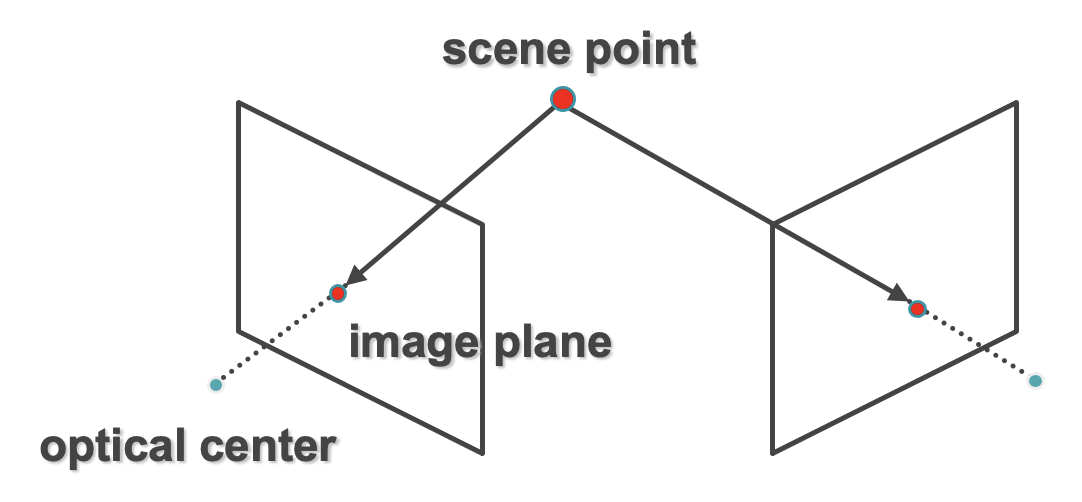
上面所示的三角剖分的基本原理是:通过两条射线的交点进行重建。要求:校准和点通信。
此外,利用核线约束,将对应问题简化为沿共轭核线的一维搜索。如下图所示。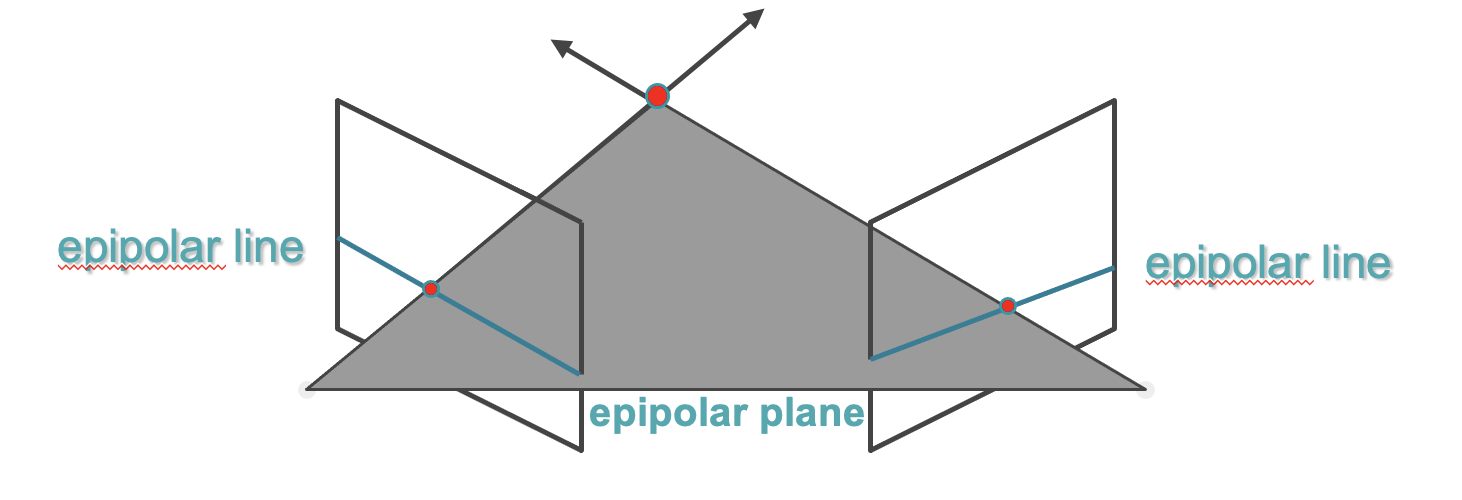
因此,后极约束假设立体对是校正后的图像,这意味着相同的核线平面(如上所示)跨行对齐,使得它与这两个平面都正交,并且彼此对齐[1]。纠正是通过学习基于内在和外在参数的转换来实现的:这是一个可以追溯到几十年前的过程。
根据校正后的图像对,深度Z可以通过其与视差d成反比的关系来确定,其中视差被定义为在比较来自左和右的对应时沿水平方向的像素差,即i(x,y)=D(x+d,y)。
这种关系在视觉上最容易把握。
假设在世界坐标(X,Y,Z)中投影的左侧图像平面P_L(x,y)中的一个点作为3D场景中的一个点,我们的目标是在提供立体对的情况下重建缺失的Z(深度)。
以及右侧图像平面中的对应关系。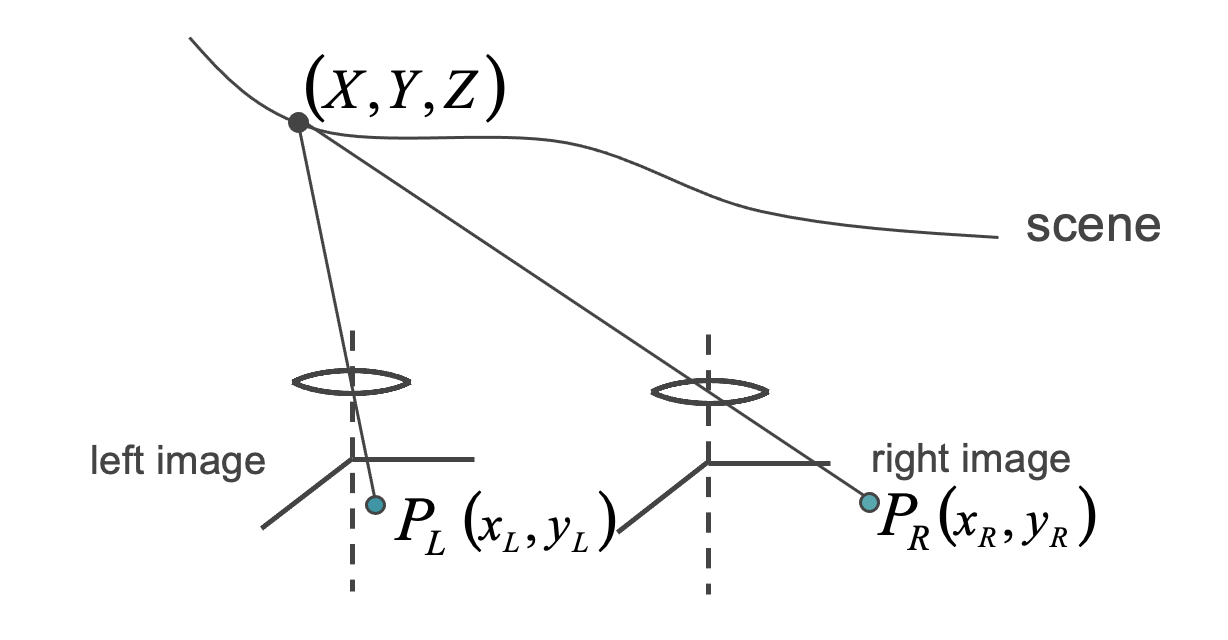
我们设置相对世界坐标(红轴),并在两个相机中心之间具有已知基线b: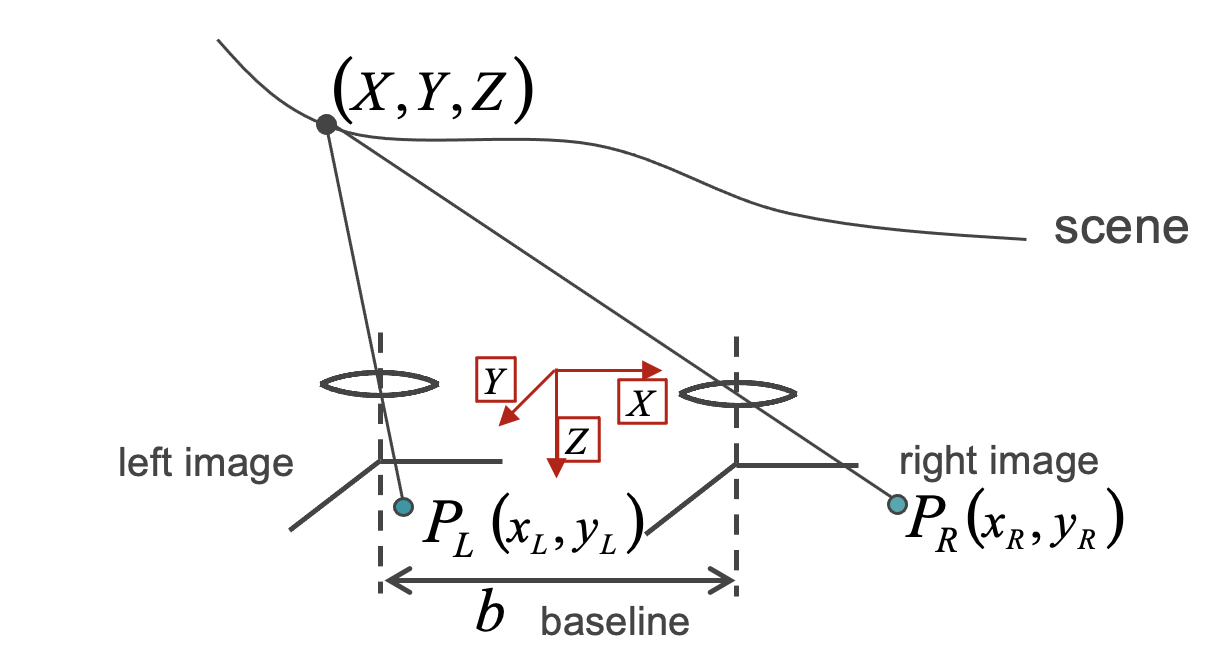
我们会得到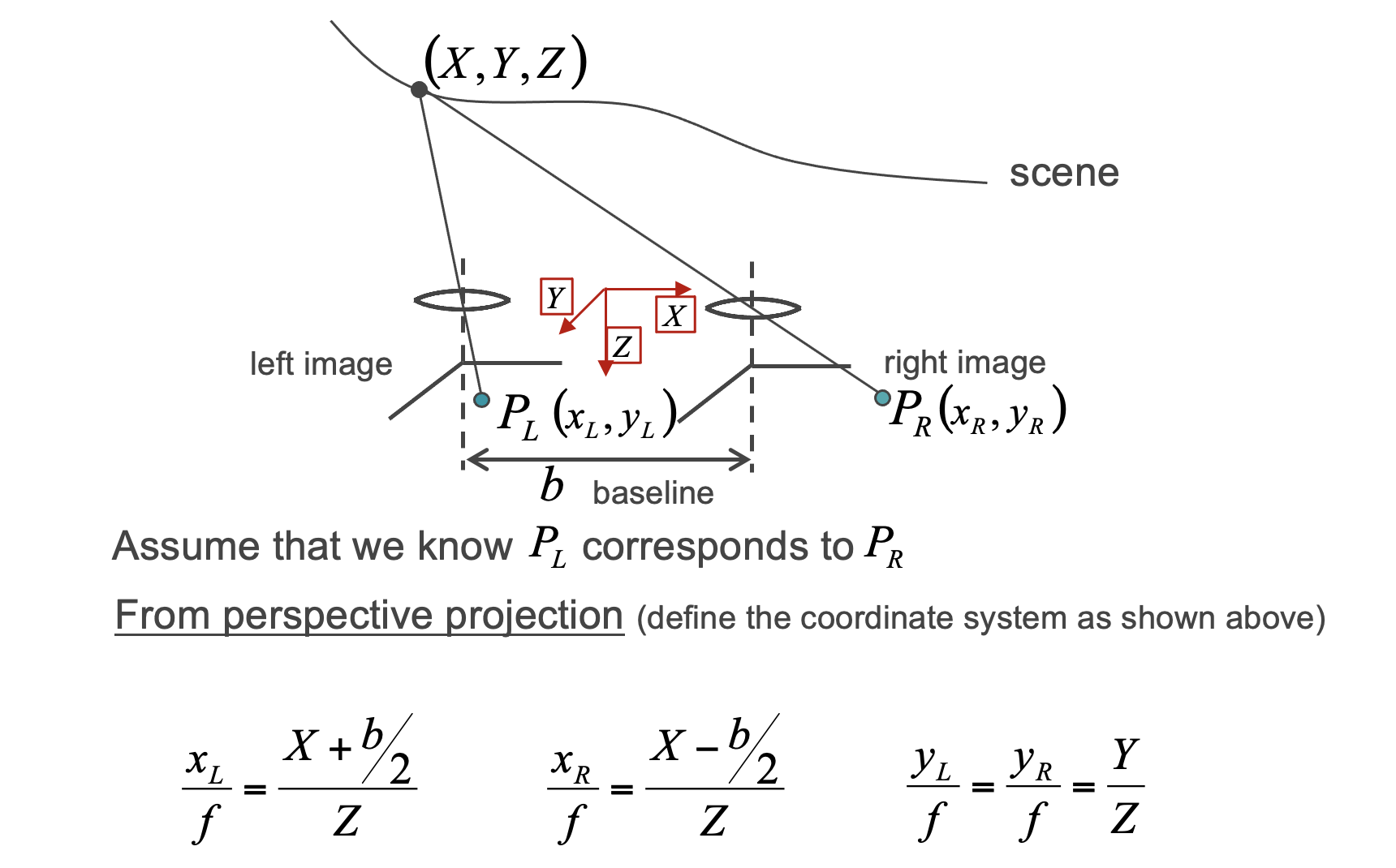
它可以表示为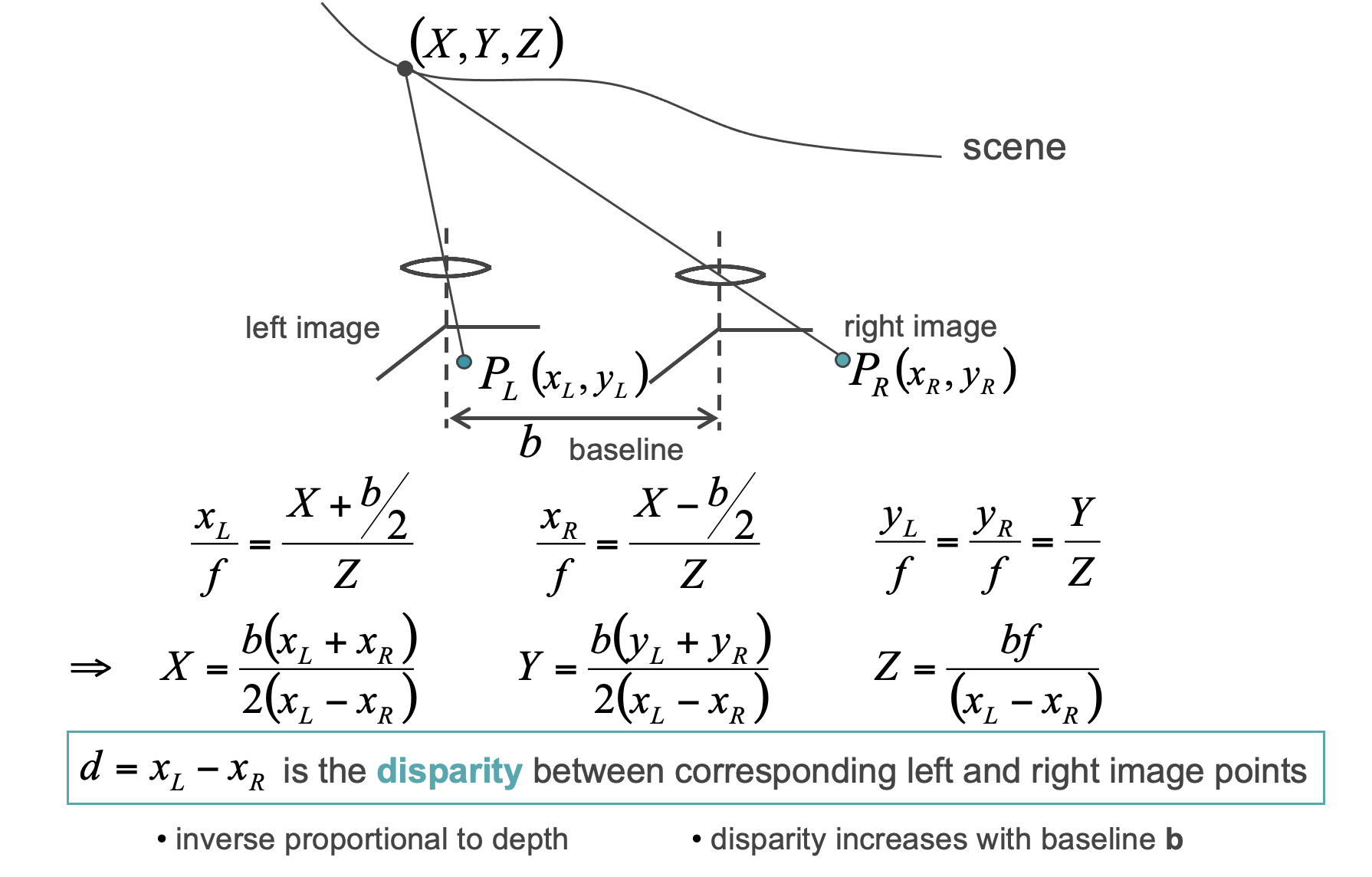
几代立体视觉系统
多年来,立体视觉一直是研究界感兴趣的问题。如今,人们可以将不同的方法描述为三代之一。
关于这一系列用于视差图估计的DL,我们可以将这些方法描述为以下两种方法中的一种。
对于端到端(2)的系统,必须满足以下原理图。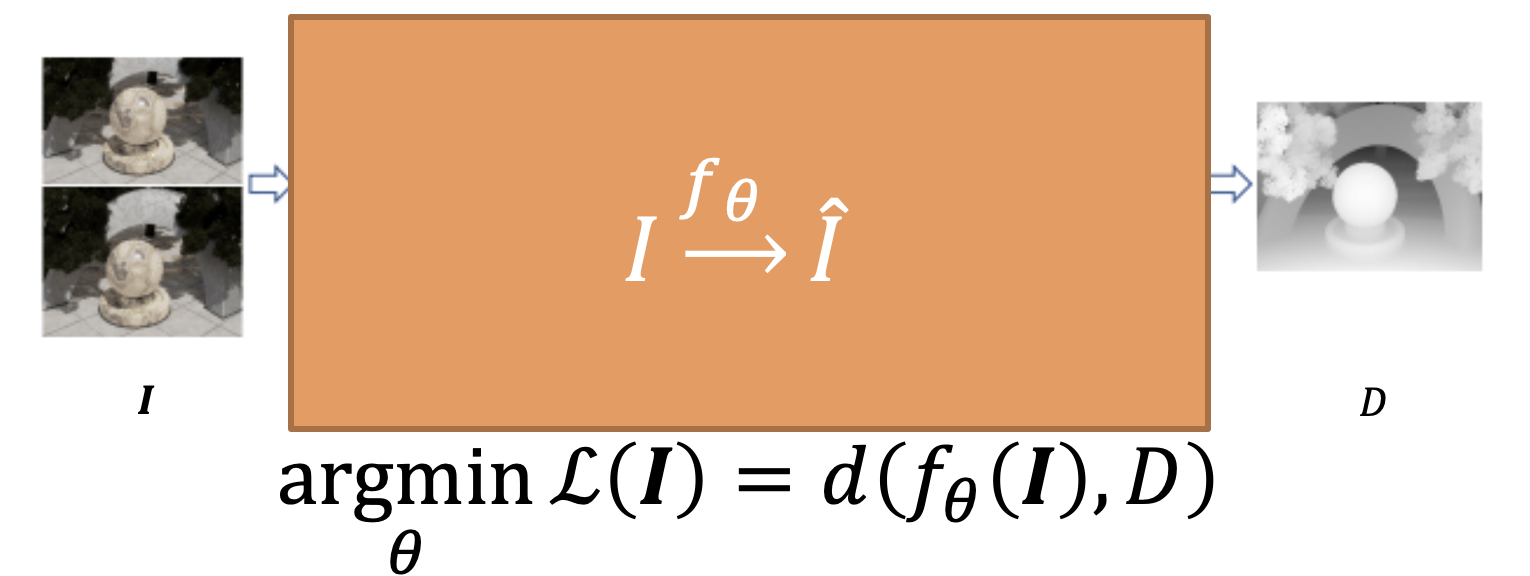
正如我们将在前面的部分中看到的,代表DL网络的黑色(好的,橙色)框可以由几个子模块组成,这些子模块通常串联在一起,使得不同的步骤类似于传统立体视觉系统中涉及的常规步骤。
展望未来
接下来,在第一部分中,我们将回顾用于立体视觉问题的数据集、资源和度量。这将是这篇介绍性文章的扩展,其中包含公开可用的基准中面临的特定示例、挑战和统计数据。
然后,在第二部分中,我们将回顾MC-CNN作为首次尝试使用深度学习来提取更鲁棒的特征[1],然后继续使用DispNet[2]、GC-Net[3]、PSMNet[4]、iResNet[5]和GA-Net[6]。
[1]C.Loop和Z.Zhang。计算立体视觉的校正单调。IEEE会议“计算机视觉与模式识别”,1999。Computing Rectifying Homographies for Stereo Vision
[2]Zbontar,Jure和Yann LeCun。“通过训练卷积神经网络来比较图像块进行立体匹配。”J·马赫。学一学。决议17.1(2016):2287-2318。
[2]Mayer,Nikolaus等人。用于训练卷积网络以进行视差、光流和场景流估计的大型数据集。IEEE计算机视觉和模式识别会议论文集。2016年。
[3]Kendall、Alex等人。“端到端学习几何学和深度立体声回归的上下文。”IEEE计算机视觉国际会议论文集。2017年。
[4]张家仁、陈永胜。“金字塔立体匹配网络。”IEEE计算机视觉和模式识别会议论文集。2018年。
[5]梁正发等人。“通过特征恒定进行视差估计的学习。”IEEE计算机视觉和模式识别会议论文集。2018年。
[6]张飞虎等人。“GA-Net:用于端到端立体匹配的引导式聚合网络。”IEEE/CVF计算机视觉和模式识别会议论文集。2019年。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/18/%e4%bb%8e%e8%a7%86%e5%b7%ae%e5%88%b0%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e7%9a%84%e6%b7%b1%e5%ba%a60/
