
计算机视觉

听听这个故事,…
CVPR 2021年最佳论文奖授予来自马克斯·普朗克智能系统研究所和图宾根大学的迈克尔·尼迈耶和安德烈亚斯·盖格,因为他们的论文名为长颈鹿,这篇论文着眼于可控图像合成的任务。换句话说,他们着眼于生成新图像并控制将出现的内容、对象及其位置和方向、背景等。使用改进的GAN架构,他们甚至可以在不影响背景或其他对象的情况下移动图像中的对象!CVPR是一个一年一度的会议,就在上周,计算机视觉领域的大量新研究论文就是为了这个活动而发表的。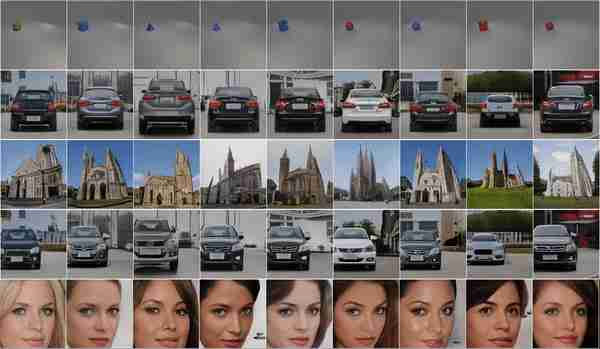
正如您已经知道的,如果您经常阅读我的文章,传统的GAN架构使用编码器和解码器设置,就像这样。在训练期间,编码器接收图像,将其编码成压缩表示,解码器采用该表示来创建改变样式的新图像。这对我们训练数据集中的所有图像重复多次,以便编码器和解码器了解如何最大化我们希望在训练期间实现的任务的结果。训练完成后,您可以将图像发送到编码器,编码器将执行相同的过程,根据您的需要生成新的不可见图像。无论任务是什么,它的工作原理都非常相似,无论是将一张脸的图像转换成另一种风格(如卡通机),还是根据快速草稿创建一幅美丽的风景。只使用解码器,我们也称其为生成器,因为它是负责创建新图像的模型,我们可以在这个编码信息空间中漫步,并将我们发送给生成器的样本信息发送给生成器,以生成无限数量的新图像。这种编码的信息空间通常被称为潜在空间,而我们用来生成新图像的信息被称为潜在代码。我们基本上在这个最优空间中随机选择一些潜在的代码,然后它在我们想要实现的任务之后生成一个新的随机图像,当然是在这个生成器的训练过程之后。这太酷了,但就像我刚才说的,这张图片完全是随机的,我们没有或很少知道它会是什么样子,这对创作者来说已经没有多大用处了。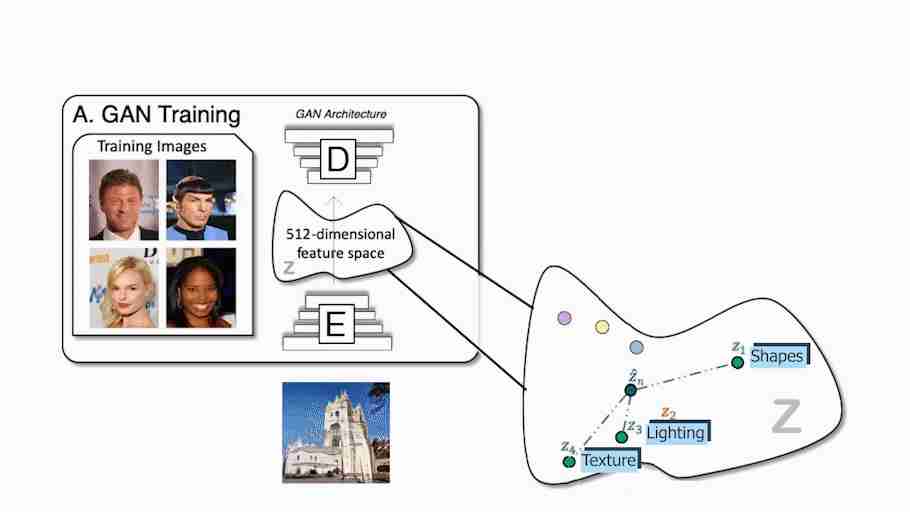
这就是他们用这份报纸攻击的问题。事实上,通过获取物体形状和外观的潜在代码并将其发送到解码器或生成器,他们能够控制物体的姿势,这意味着他们可以四处移动物体,改变外观,添加其他物体,改变背景,甚至改变相机姿势。所有这些变换都可以在每个对象或背景上独立完成,而不会影响图像中的任何其他内容!
正如您所看到的,它比其他基于GaN的方法要好得多,这些方法通常不能使对象彼此解开,并且都会受到特定对象修改的影响。
他们的方法的不同之处在于,他们在三维场景表示中解决这个问题,就像我们如何看待现实世界一样,而不是像其他Gan人那样停留在二维图像世界中。但除此之外,这一过程非常相似。他们对信息进行编码,识别对象,在潜在空间内编辑它们,然后解码以生成新的图像。在这里,在这个潜在的空间里还有更多的步骤要做。我们可以将其视为经典GaN图像合成网络与神经渲染器的组合,该神经渲染器用于从发送到网络的图像生成3D场景,正如我们将看到的那样。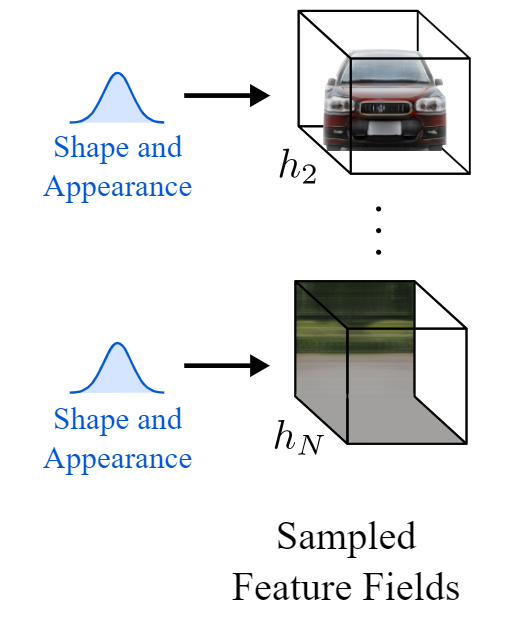
实现这一目标主要有三个步骤。在对输入图像进行编码后,意味着我们已经处于潜在空间,第一步是将图像转换为3D场景。但不只是一个简单的3D场景,一个由3D元素组成的3D场景,这些元素是物体和背景。这种将图像视为由生成的体积渲染组成的场景的方式允许它们改变生成的图像中的相机角度,并独立控制对象。这是使用与我之前介绍的名为nerv的论文类似的模型来实现的,但不是使用单个模型从输入图像生成整个锁定的场景,而是使用两个单独的模型独立生成对象和背景。这里称为采样要素字段。该网络的参数也是在训练过程中学习的。我不会详细介绍,但它与我在另一篇文章中介绍的NERF非常相似。如果你想了解更多关于这类网络的详细信息,你可以观看这段关于NERV的视频,它也在下面的参考文献中有链接。the paper I previously covered called NERV this video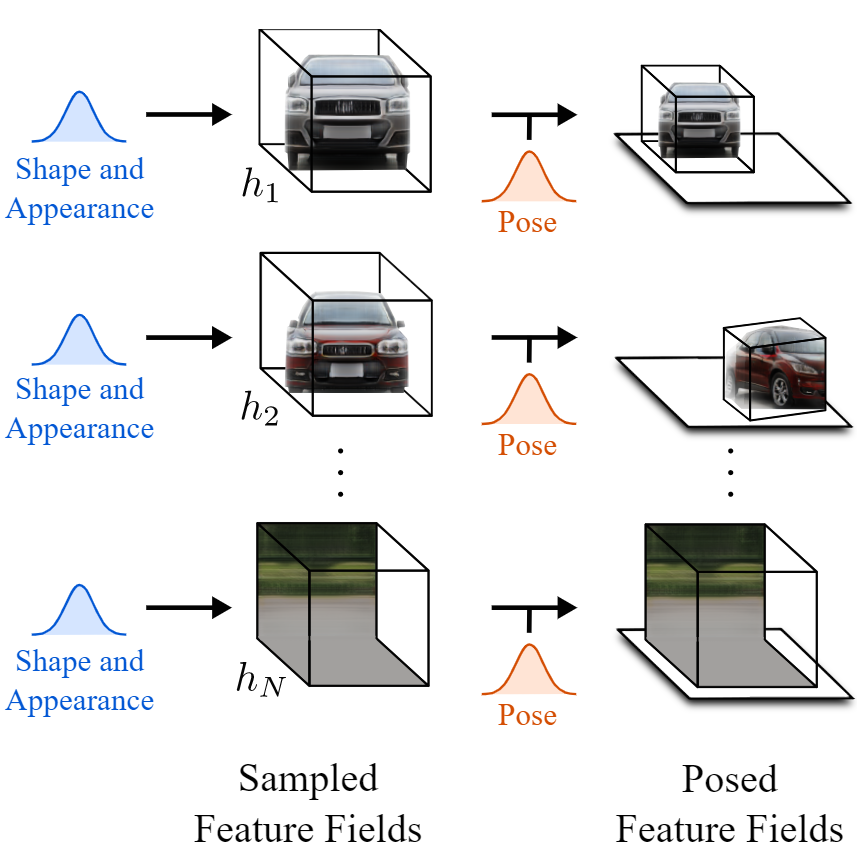
有了这个解开元素的场景,我们可以单独编辑它们,而不会影响图像的睡觉。这是第二步。他们可以对物体做任何他们想做的事情,比如改变它的位置和方向。换句话说,他们改变物体或背景的姿势。此时,他们甚至可以随心所欲地添加新对象。然后,通过将所有要素字段添加到一起,简单地将它们组合成包含所有对象和背景的最终3D场景。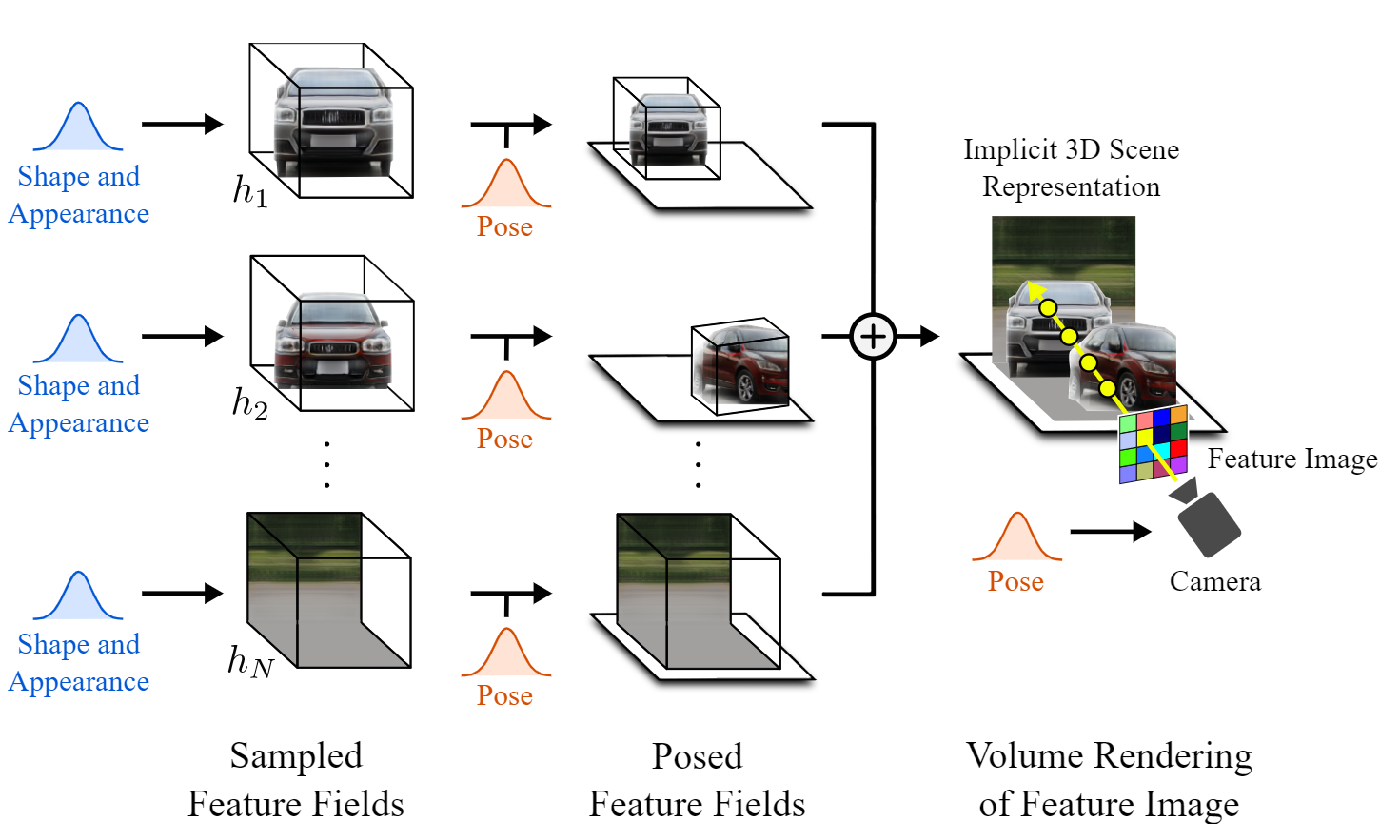
最后,我们必须回到自然图像的2D世界。所以最后一步是把这个3D场景渲染成一个规则的图像。由于我们仍处于3D世界中,因此可以更改摄影机视点来决定如何查看场景。然后,我们根据该相机光线和其他参数(如Alpha值和透射率)来评估每个像素。这就是他们所说的特征图像,但这个特征图像是由每个像素的特征向量组成的图像。由于我们还处于潜在空间,这些特征需要转换成RGB颜色和高分辨率图像。这是使用典型的解码器完成的,就像其他GaN架构一样,将其提升到其原始尺寸,并同时学习该功能到RGB通道的转换。瞧,你有了新的图像,对生成的内容有了更多的控制!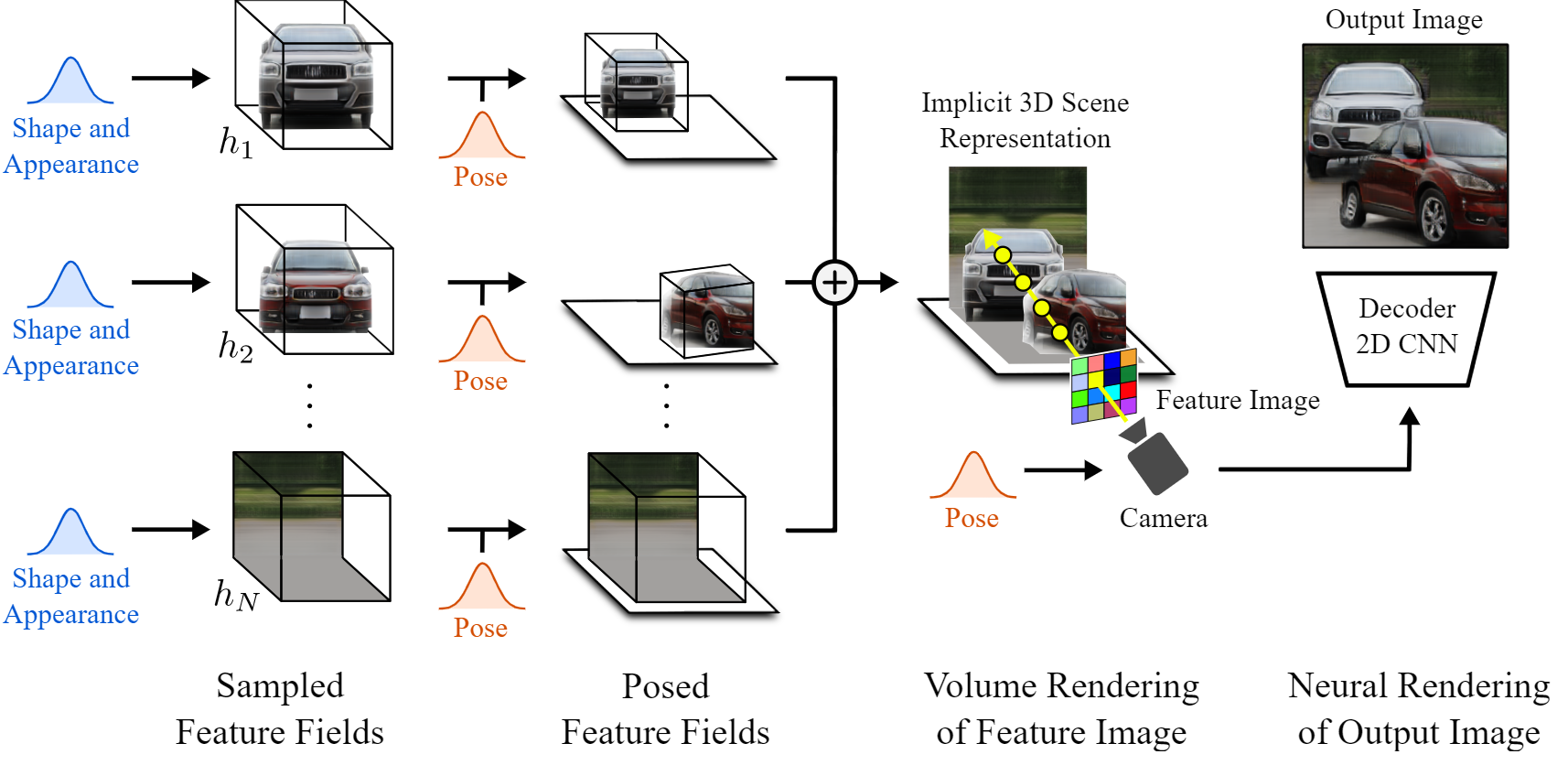
当然,正如您所看到的,在使用真实世界的数据时,它仍然不是完美的。尽管如此,它仍然令人印象深刻,是朝着正确方向迈出的重要一步,特别是考虑到这些都是完全由Gans生成的合成图像,而且这只是第一篇能够控制生成的图像达到这种精度水平的论文。
这篇论文真的很有趣,我建议你读一读,以了解他们的模型是如何工作的。祝贺迈克尔·尼迈耶和安德烈亚斯·盖格获得当之无愧的最佳论文奖。如果你愿意的话,他们还在他们的GitHub上提供了这些代码。该链接位于下面的参考文献中
感谢您的阅读!
观看视频
来我们的不和谐社区和我们聊天吧:一起学习人工智能,分享你的项目,论文,最好的课程,寻找Kaggle队友,等等!Discord community: Learn AI Together
如果你喜欢我的工作,想要了解最新的AI,你绝对应该在我的其他社交媒体账号(LinkedIn,Twitter)上关注我,订阅我的每周AI时事通讯!LinkedIn Twitter newsletter
来支持我:
- 支持我的最好方式是成为这个网站的成员,或者如果你喜欢我在YouTube上的频道,就订阅它。
- 在财务上支持我在Patreon上的工作
- 请在Medium上跟我来这里
参考文献
- 迈克尔·尼迈耶和安德烈亚斯·盖格,(2021),“长颈鹿:将场景表示为成分生成神经特征场”,发表在CVPR 2021上。
- 与纸张及更多内容的项目链接:https://m-niemeyer.github.io/project-pages/giraffe/index.html
- 编码:https://github.com/autonomousvision/giraffe
- NERF视频:https://youtu.be/ZkaTyBvS2w4
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/09/cvpr2021%e5%b9%b4%e6%9c%80%e4%bd%b3%e8%ae%ba%e6%96%87%e5%a5%96%ef%bc%9a%e9%95%bf%e9%a2%88%e9%b9%bf%e2%80%8a-%e2%80%8a%e5%8f%af%e6%8e%a7%e5%9b%be%e5%83%8f%e7%94%9f%e6%88%90/
