

任务描述📔
?�“aiax�创建一个程序,该程序在识别特定面孔时执行下面提到的任务。
📌当它认出你的脸时,就会”👉“它会把邮件发送到你的邮箱ID。👉第二,它会向你的朋友发送WhatsApp消息。
📌当它识别第二张脸时,它可以是你的朋友或家人的脸。👉在AWS中创建EC2实例。👉创建5 GB的eBS卷并将其附加到实例。
在本文中,我们将在Python和AWS中使用计算机视觉。
首先让我们来看看什么是计算机视觉,
计算机视觉是人工智能的一个领域,它训练计算机解释和理解视觉世界。使用来自相机和视频的数字图像和深度学习模型,机器可以准确地识别和分类物体(欧元),然后对他们看到的东西做出反应。(œ�)
计算机组装视觉图像的方式与你拼凑拼图的方式相同。
想一想你是如何玩拼图游戏的。你有所有这些碎片,你需要把它们组装成一个图像。这就是™的计算机视觉神经网络的工作原理。它们区分图像的许多不同部分,识别边缘,然后对子组件进行建模。使用过滤和通过深层网络层的一系列操作,他们可以将图像的所有部分拼凑在一起,就像你玩拼图一样。
计算机不会在拼图盒子的顶部给出最终的图像(™),但通常会输入成百上千张相关的图像来训练它识别特定的对象。
程序员不再训练计算机寻找胡须、尾巴和尖尖的耳朵来识别猫,而是上传数百万张猫的照片,然后模型自己学习构成猫的不同特征。
这些进步对计算机视觉领域的影响令人震惊。在不到十年的时间里,物体识别和分类的准确率已经从50%上升到99%(欧元),而今天(欧元™)的系统在快速检测和对视觉输入做出反应方面比人类更准确。
许多行业的计算机视觉用户正在看到实实在在的结果–“EURO”,我们?EURO™在这张信息图中记录了其中的许多结果。例如,您是否知道:
- 计算机视觉可以区分阶段性和真实性的汽车损坏。
- 计算机视觉使安全应用的面部识别成为可能。
- 计算机视觉使现代零售店的自动结账成为可能。
计算机视觉的工作原理
计算机视觉工作有三个基本步骤:
获取图像:通过视频、照片或3D技术可以实时获取图像,即使是大集合也可以进行分析。
图像处理:深度学习模型自动化了大部分过程,但这些模型通常是通过首先输入数千张已标记或预先识别的图像来进行训练的。
理解图像:最后一步是解释步骤,对对象进行识别或分类。
有许多类型的计算机视觉以不同的方式使用:
- 图像分割将图像分割成多个区域或片断,分别进行检查。
- 对象检测标识图像中的特定对象。高级对象检测在单个图像中识别多个对象:足球场、进攻球员、防守球员、球等等。这些模型使用X,Y坐标创建边界框并标识框内的所有内容。
- 面部识别是一种高级类型的目标检测,它不仅识别图像中的人脸,而且识别特定的个人。
- 边缘检测是一种用于识别对象或景观的外部边缘的技术,以更好地识别图像中的内容。
- 模式检测是识别图像中重复的形状、颜色和其他视觉指标的过程。
- 图像分类将图像分成不同的类别。
- 特征匹配是一种模式检测,它匹配图像中的相似性以帮助分类。
计算机视觉的简单应用可能只使用其中一种技术,但更高级的应用,如自动驾驶汽车的计算机视觉,依赖于多种技术来实现它们的目标。
下面是存储亚伯拉罕·林肯图像的灰度图像缓冲区的简单插图。每个像素-欧元™的亮度由一个8位数字表示,其范围为0(黑色)到255(白色):
这种存储图像数据的方式可能与您的预期背道而驰,因为数据在显示时肯定看起来是二维的。然而,情况就是这样,因为计算机内存只是由不断增加的地址空间线性列表组成。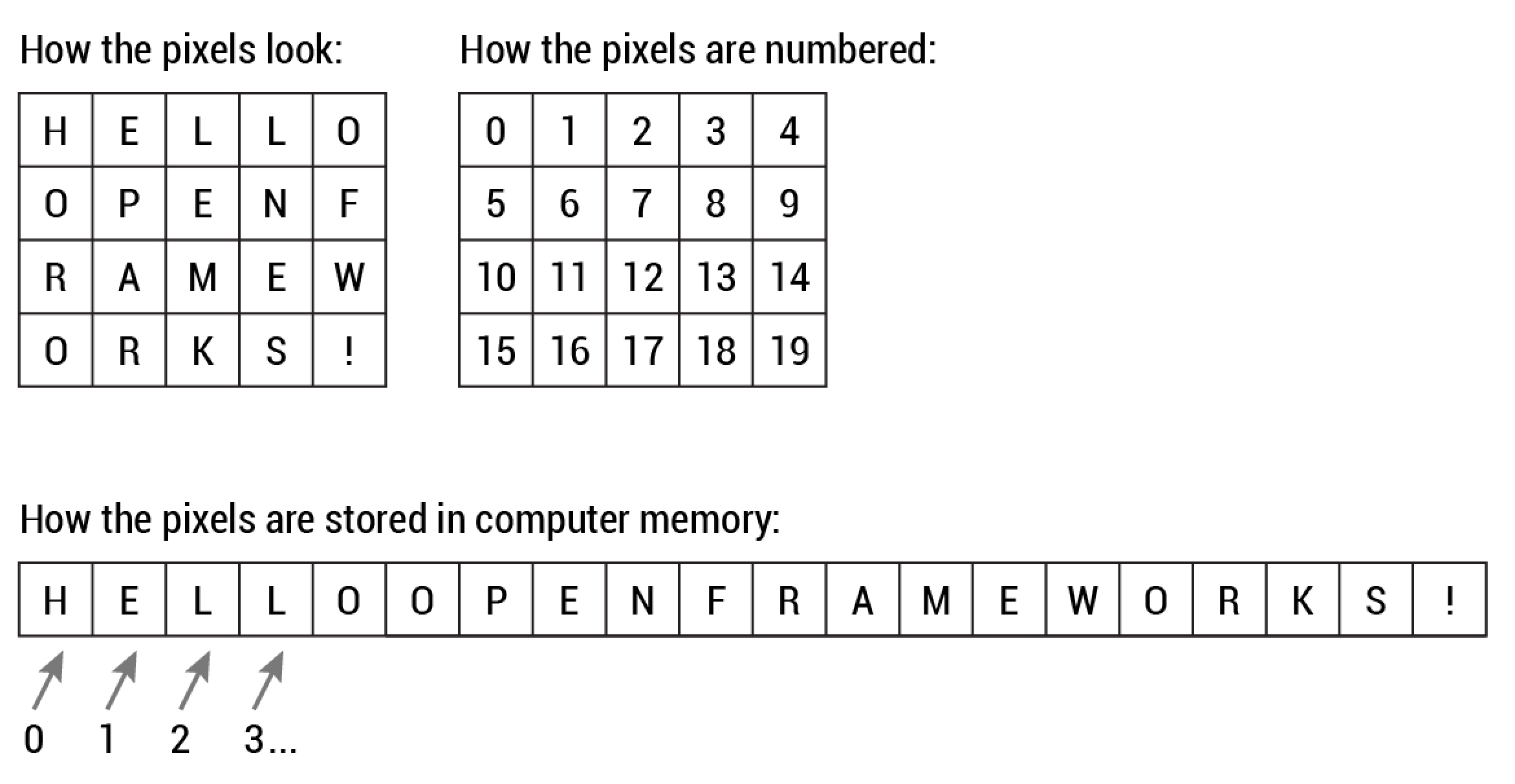
训练对象检测模型
维奥拉和琼斯进场
有许多方法可以解决对象检测挑战。多年来,流行的方法是Paul Viola和Michael Jones在“鲁棒实时目标检测”一文中提出的方法。Robust Real-time Object Detection
虽然它可以被训练来检测不同范围的对象类别,但该方法首先是由人脸检测的目标驱动的。它是如此快速和直接,以至于它是在点和拍相机中实现的算法,允许在几乎没有处理能力的情况下进行实时人脸检测。
该方法的中心特征是使用基于Haar特征的潜在大的二进制分类器集进行训练。这些特征表示边和线,在扫描图像时计算起来非常简单。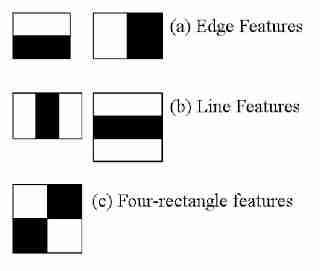
虽然非常基本,但在脸部的特定情况下,这些特征允许捕捉重要的元素,如鼻子、嘴巴或眉毛之间的距离。这是一种有监督的方法,需要识别对象类型的许多正负示例。
基于CNN的方法
深度学习已经真正改变了机器学习的游戏规则,特别是在计算机视觉领域,基于深度学习的方法现在已经成为许多常见任务的前沿。
在各种实现目标检测的深度学习方法中,R-CNN(Regions With CNN Feature)特别容易理解。这项工作的作者提出了一个三个阶段的过程: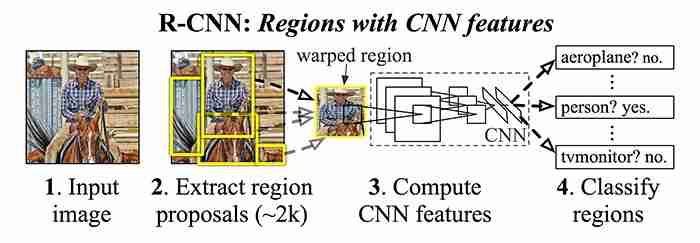
虽然R-CNN算法对于所采用的特定区域建议方法是不可知的,但在原始工作中选择的区域建议方法是选择性搜索。步骤3非常重要,因为它减少了候选对象的数量,从而降低了该方法的计算成本。
这里提取的特性不如前面提到的Haar特性直观。综上所述,使用CNN从每个区域提案中提取4096维的特征向量。鉴于CNN的性质,输入必须始终具有相同的维度。这通常是cnnâuro™的弱点之一,各种方法都以不同的方式解决这一问题。关于R-CNN方法,训练有素的CNN架构要求输入227-227像素的固定区域。由于所建议的区域的大小与此不同,作者使用欧元™方法简单地扭曲图像,使其符合所需的尺寸。
我们将使用Haar人脸分类器完成此任务
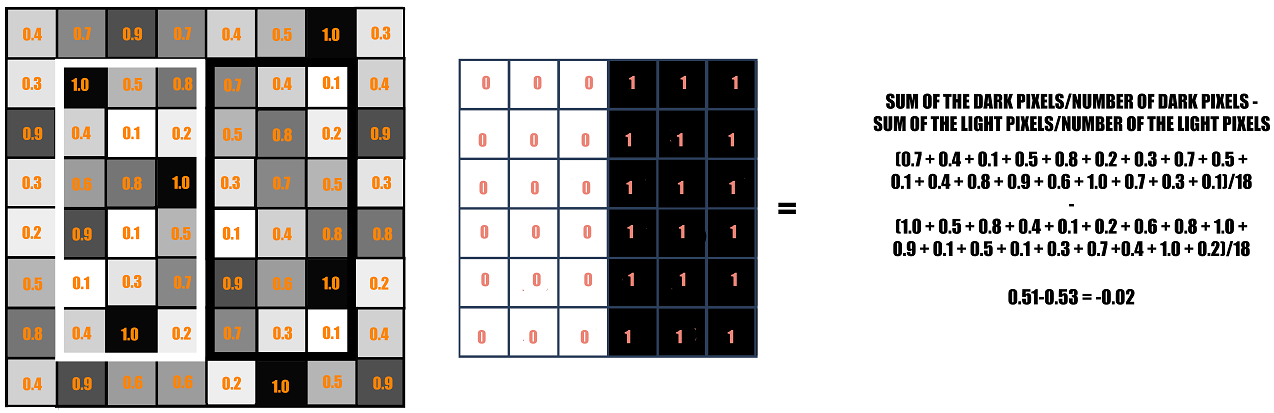
左侧的矩形是像素值为0.0到1.0的图像的示例表示形式。中间的矩形是一个哈尔核,它的左边是所有的亮像素,右边是所有的暗像素。通过找出在较暗区域的像素值的平均值与在较亮区域的像素值的平均值的差来进行HAAR计算。如果差值接近1,则存在由haar特征检测到的边缘。
haar功能中较暗的区域是值为1的像素,较亮的区域是值为0的像素。其中每一个都负责找出图像中的一个特定特征。例如图像中强度突然变化的边缘、线或任何结构。为了前任。在上图中,haar功能可以检测到右侧像素较暗、左侧像素较浅的垂直边缘。
这里的目标是找出位于HAAR特征的较暗区域的所有图像像素和位于HAAR特征的较亮区域的所有图像像素的总和。然后找出它们的不同之处。现在,如果图像有一条边缘分隔右边的暗像素和左边的亮像素,那么haar值将更接近1。这意味着,如果haar值更接近1,我们就说检测到了一个边缘。在上面的示例中,因为haar值远离1,所以没有边缘。
这只是分隔垂直边的特定哈尔特征的一种表示。现在还有其他的HAAR特征,它可以检测其他方向的边缘和任何其他图像结构。为了检测图像中任意位置的边缘,HAAR特征需要遍历整个图像。
首先,我们将收集培训数据。我们将使用网络摄像头捕捉200张图像来训练我们的模型
现在,我们将加载捕获的200幅图像,并且我们将训练模型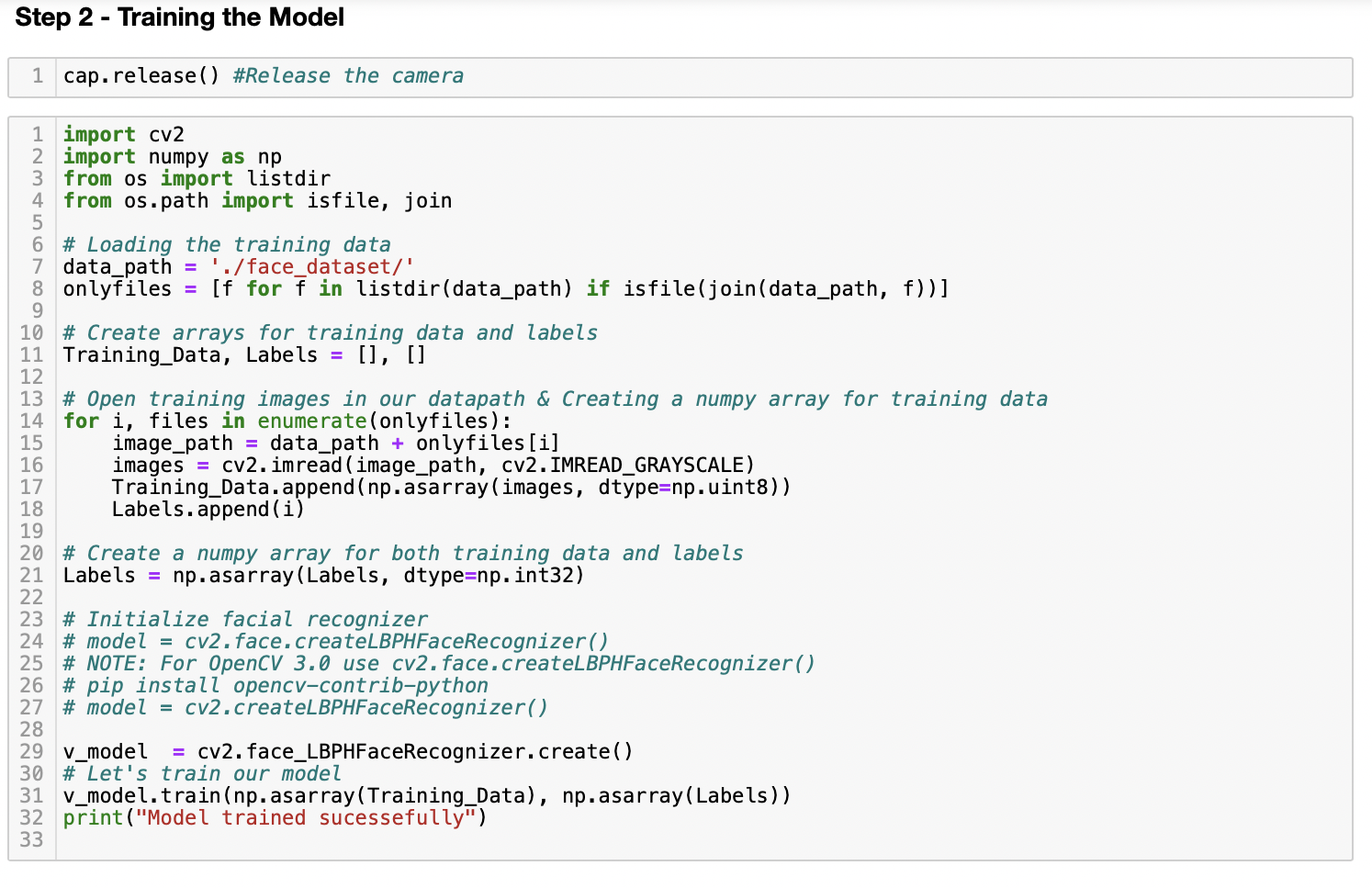
在对模型进行训练后,我们将运行人脸识别进行检测,它也将在识别时显示置信度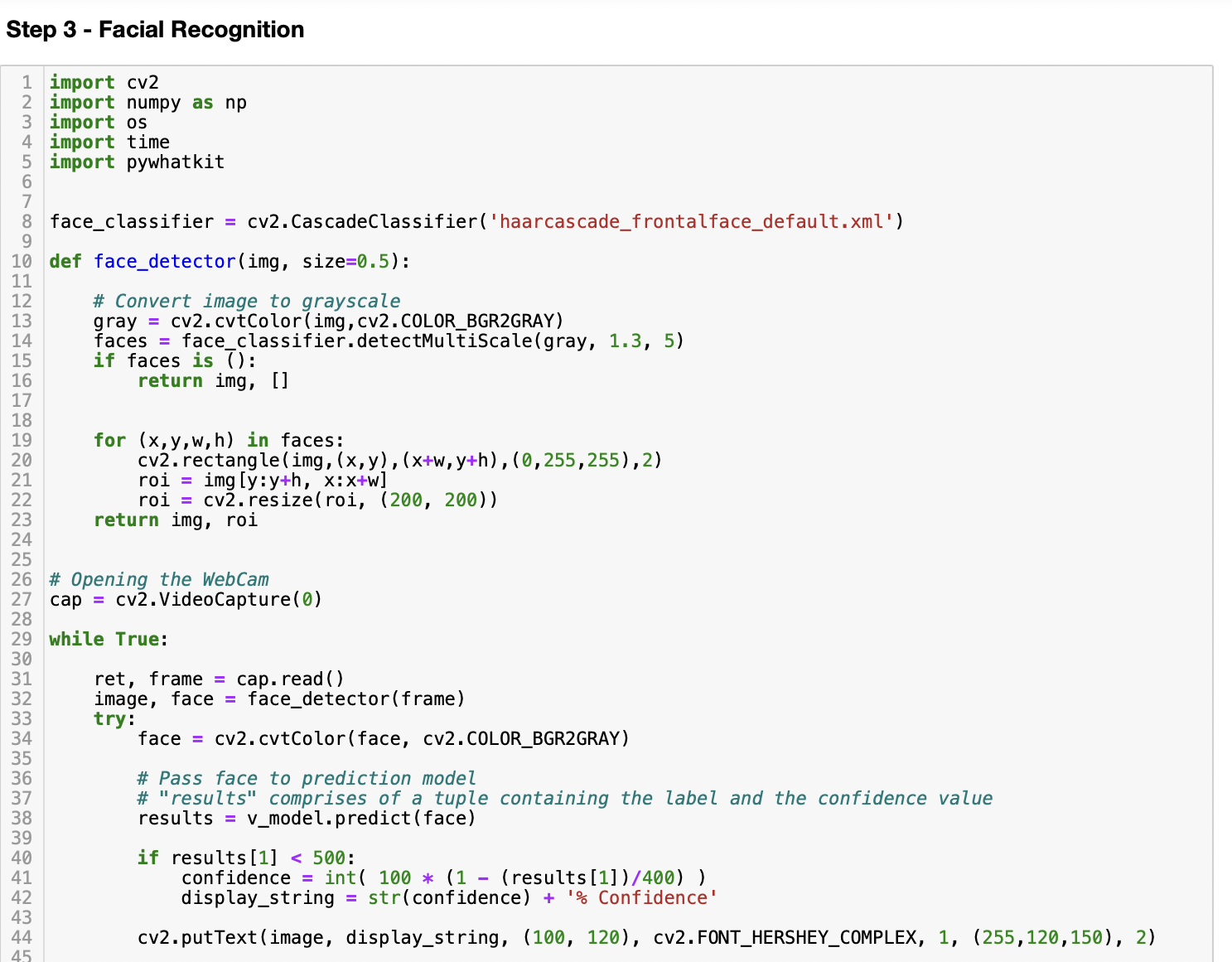
现在,根据任务描述,一旦检测到用户,它将使用WhatsApp web应用程序发送一条WhatsApp消息,并发送一封电子邮件。要做到这一点,置信度分数需要大于90%。如果它检测到朋友或家人等其他人,它会在AWS中启动EC2实例,创建5 GB的EBS卷并将其附加到该实例(我们需要提前在终端或命令提示符中使用AWS CLI登录到AWS账户)。程序会在启动eBS挡路前等待120秒,即2分钟,这样ec2实例初始化完成,附着时不会出现错误。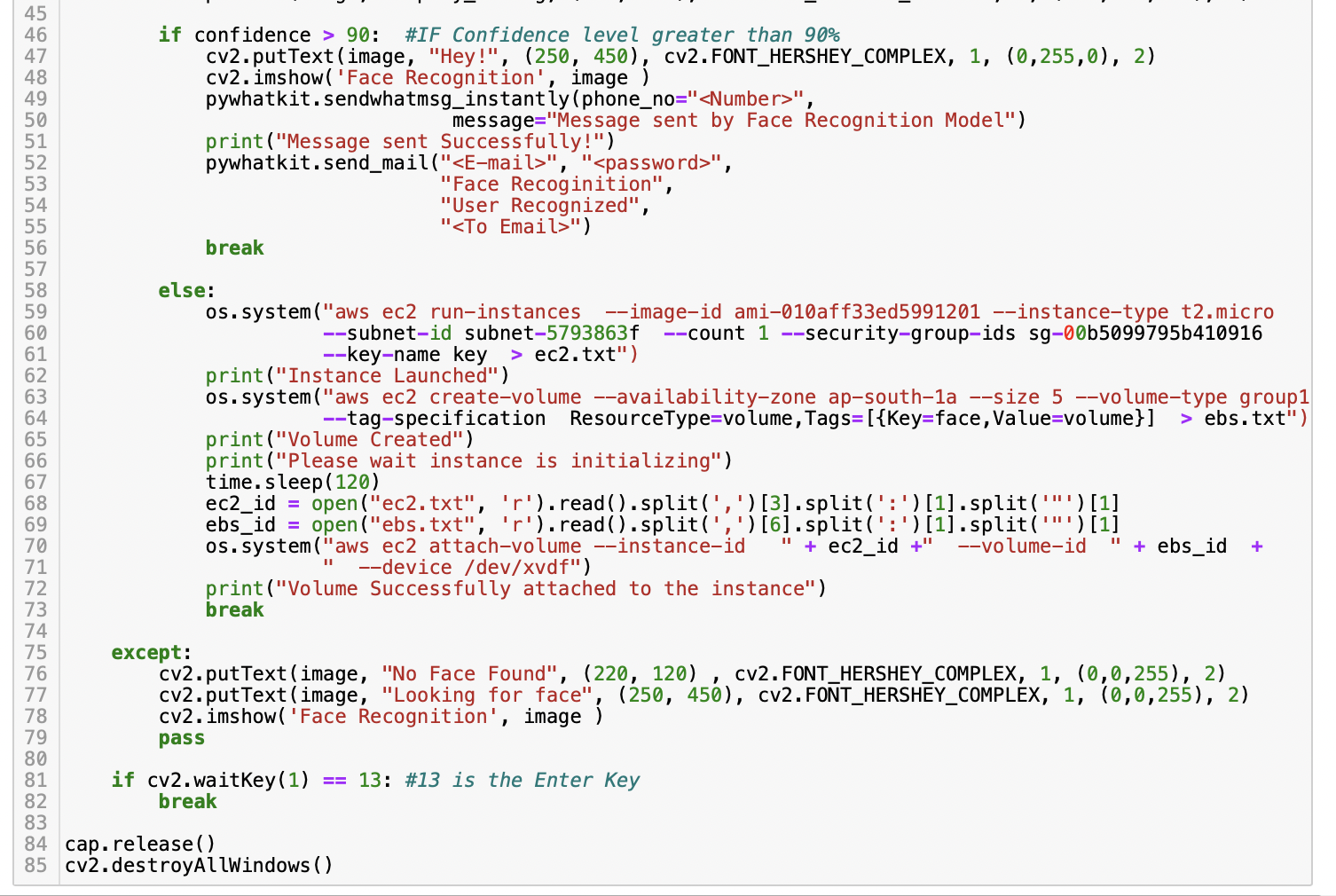
我们只需要按Enter键就可以关闭程序。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/18/%e5%88%9b%e5%bb%ba%e4%ba%ba%e8%84%b8%e8%af%86%e5%88%ab%e6%a8%a1%e5%9e%8b%e5%b9%b6%e5%b0%86%e5%85%b6%e8%bf%9e%e6%8e%a5%e5%88%b0aws%e7%ad%89/
