

我一生都想养一只狗作为宠物,我妈妈受不了毛皮,所以我小时候从来没有养过一只狗。(™)我一个人住了很长一段时间,我觉得现在是找我心爱的最好的朋友的好时机。™™是一个很好的时间去找我心爱的最好的朋友。当然,我从一个救援收容所拿到了我的,给她取名为卡丽熙ğŸ�‰。
现在让我完全客观地说,卡丽熙非常英俊(你可以这么说狗,对吗?)我和她所到之处,人们不断走近她,一边恭维她,一边反复问这个问题–EUROUREœ,她的品种是什么?EURO™??EURO�。œ嗯,She?™是个杂种。?Euro�我总是这么说,试图避免我对我的宠物遗传缺乏了解,但听到的却是紧跟在我答案后面的失望的?EUROœOHO.?EURO�(我的答案后面跟着的是?EUROœOHO.?EURO�)。
四年后的将来,作为数据科学(DS)奖学金计划的一部分,我和我选择的团队必须为最终项目想出一个想法。果然,最终能够利用深度学习和计算机视觉的力量找出宠物-™品种,并解决最终的问题,是我们选择的主题。
快速入门ğŸ>>
在本文中,我们将解释执行上述任务的过程。您可以按照步骤或运行我们上传到GitHub存储库的预制脚本来自己创建此模型。这些脚本是我们在过程中运行的实际代码(只是组织得更有条理一点)。GitHub repository
该项目必须包括一般DS项目的所有部分,因此本文中的部分将相应命名:
(1)采集数据ğŸ“元
第一步是获取所有需要的数据。对于我们的项目,我们使用了两个不同的数据集:
下载数据集是使用Kaggle的API完成的。也就是说,您需要一个Kaggle令牌才能使用我们的脚本或通过Google Colab访问这些集合。当然,您始终可以手动下载文件。Kaggle’s API
ğŸ导航到克隆存储库,安装项目要求,并运行用于下载数据集的脚本:💡
git clone https://github.com/Shlomigreen/pet-breed-classifier
cd pet-breed-classifier
pip install -r requirements.txt
python3 src/download-files.py 
(1.1)文件编目📇
因为我们™正在处理相当大量的文件,所以在某种程度上,管理文件信息变得更容易了。在我们的示例中,我们创建了一个名为Catalog.csv的文件,其中包含有关下载的图像的有用信息,例如它们的源(数据集)、标记的物种、标记的品种、路径和文件名。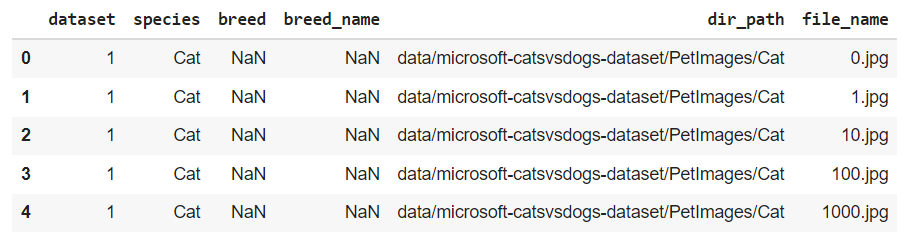
请注意,品种包含NaN值,因为来自微软™数据集的图像没有为品种添加标签。
ğŸ的目录包含在GIT存储库中的INFO文件夹下。但是,如果您愿意从头开始生成,则可以使用create-Catalogy.py脚本:💡
python3 src/create-catalog.py现在我们都准备好了我们的数据和相关信息,我们可以开始探索!🷵ğŸ�»âuro�â™,aiecor�
(2)电子设计自动化及前处理ğŸ“�
分配
如前所述,我们使用两个数据集。第一组(微软™s)只包含带标签的物种图像(猫或狗),而第二组(牛津大学™s)同时包含物种和品种标签。当组合在一起时,这两个公开可用的数据集总共包含32,347张图像,分别分为12个和25个品种的14,870张(46%)猫的图像和17,477张(54%)狗的图像。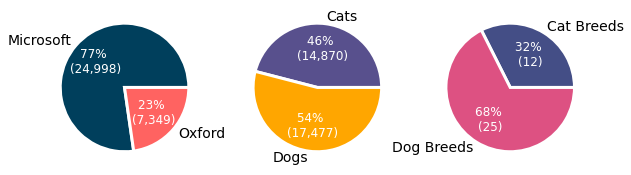
因为这两个数据集在kaggle上都是公开可用的,所以我们希望它们是相对干净的欧元˜™集,而且正如上面所看到的,它们确实是这样的!
我们要检查的最后一件事是不同品种的分布情况: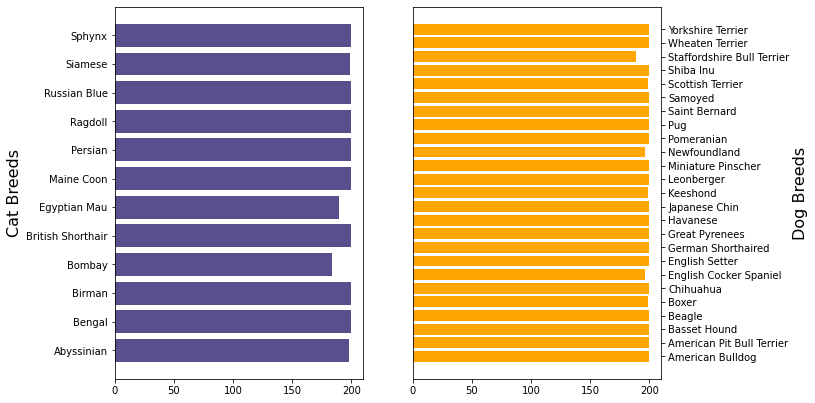
每种犬约有2 0 0张图像,数据集看起来各方面都很平衡!👃ğŸ�»
不良形象
EDA的第二步是手动浏览图像并查看是否出现问题。这个过程很整洁,而且不精确,但是我们确实设法列出了一系列既不是猫也不是狗的图片,但它们都被贴上了标签。
采取的另一个步骤是检测任何不是图像的文件。目录文件是使用数据集提供程序提供的图像的路径创建的,但是在这些给定的路径中,有些文件不是图像,它们必须被过滤掉。
在名为is_image的编录文件上的新列中标记了坏图像和非图像文件。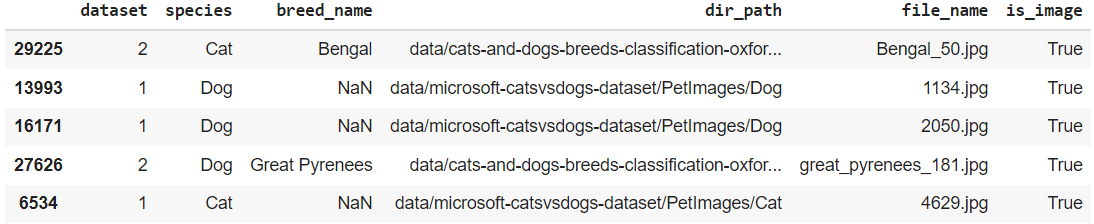
ğŸ通过运行precessing.py脚本来检测非图像和错误分类的图像。这将自动更新INFO/Catalog.csv中的编录文件。💡
python3 src/pre-processing.py到目前为止-EUE??œ“我们检查了数据的不平衡情况-œ”清理了坏的和错误分类的图像-œ“创建了我们数据的信息表示
似乎是开始构建我们的初始模型的好时机!
(3)基线建模ğŸ袁‰
在清理数据并准备好之后,我们的第一个任务是构建某种基本模型,以证明我们的目标确实是可能实现的。当然,猫/狗分类器已经存在很长一段时间了,但作为年轻的数据科学家,我们希望亲身体验一下从头开始生成这些分类器的经验。
架构
显而易见的选择是构建一个卷积神经网络(CNN),它有三个卷积层和几个全连通层,具有RELU和Sigmoid激活函数,以允许某些非线性。
考虑到这一点,我们使用TensorFlow中的KERAS实现构建了上述网络,同时在卷积之间添加了一些丢包。TensorFlow
我们使用ADAM作为优化器,结合二元交叉损失函数和应计指标,编制了序贯模型。我们还定义了一个回调函数,用于在验证损失(MONITOR=?EUROU�VAL_LOSS?�)在5个时期后没有改善的情况下停止训练并保存最佳结果。您可以在这里阅读更多关于回调和提前停止的内容。here
培训与评估
使用OpenCV库将图像逐个加载到图像阵列中并调整其大小。然后,采用基本的训练-测试-分割方法将图像数组分为训练集和测试集,测试记录占总记录的20%。然后加载图像
将所构建的模型在训练集上进行训练(拟合),同时使用批次大小为32,验证分割为10%的情况。由于提前停止,模型在20个纪元后达到了最大潜力,在验证和后来评估的测试集上的准确率都达到了87%!
为了获得更好的性能,ğŸ在使用Google Colab的笔记本上进行了培训和电子数据分析。我要写的是,基本型号的笔记本没有包含在存储库中,对不起!
(4)改进型ğŸ袁‡
基线CNN可以很好地进行物种分类。然而,对于更大的品种分类任务来说,这个基础网络是根本不够的。为了达到这一目的,我们的目标是使用预构建神经网络(NN)的迁移学习。
为了最大限度地提高最终性能,我们决定推出三种型号:
架构
因为我们使用TensorFlow中的KERAS实现作为我们的Go-to-to NN构建模块,所以我们试验了几种带有预先训练的权重的罐装架构,这些权重可作为包的一部分提供。available as part of the package
VGG-16在我们的实验中给了我们最好的结果,所以我们用它来制作我们的新模型。VGG-16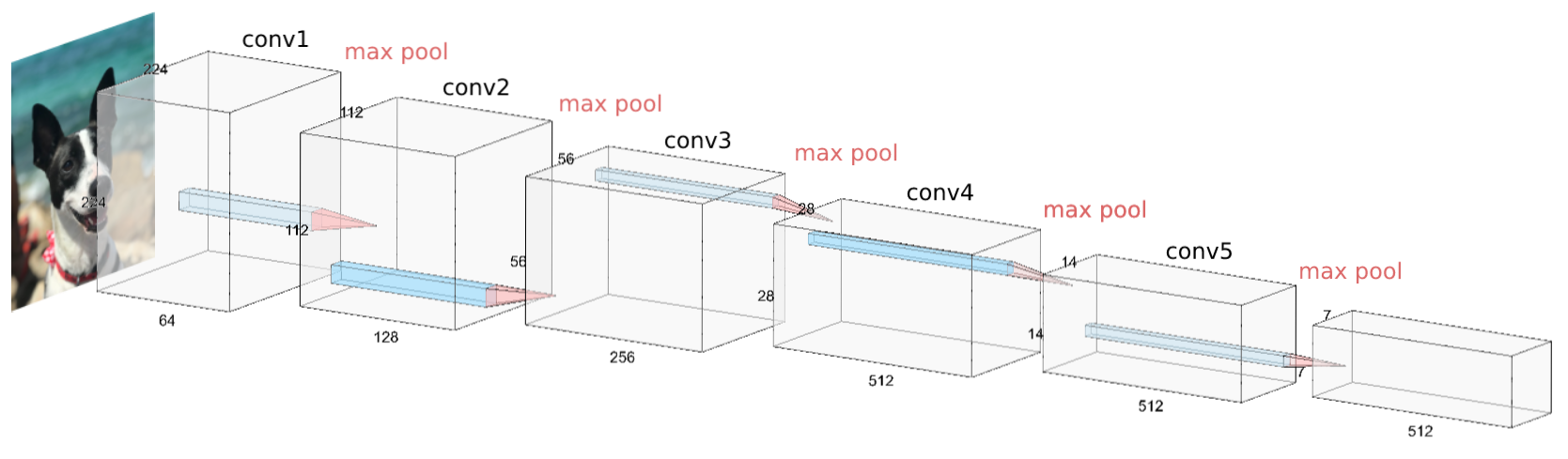
对于VGG-16CNN,我们增加了一个展平层和两个具有RELU和Sigmoid/Softmax激活函数的致密层(取决于分类器的类型)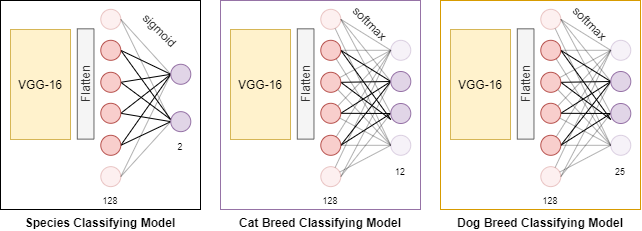
培训
我们没有像以前那样加载所有图像,而是利用了内置在ImageDataGenerator对象中的Keraâuro™,该对象允许生成具有实时数据增强功能的张量图像数据批次。ImageDataGenerator
对于这三个模型中的每一个模型,都在目录文件中创建了一个新列,指示该图像是否作为该模型的列车集的一部分。这一步给我们留下了编录文件的当前状态:
使用迁移学习的培训过程的ğŸ笔记本可以在GitHub存储库中的笔记本目录下找到。
物种分类模型
物种分类模型使用0.2验证拆分、64批次大小、提前停止回调和30个历元进行训练。该模型是用优化器=?EURO™ADAM?EURO™AND LOSS=?EURO™BINARY_CROSENTROPY编译的,经过大约4个时期之后,模型在验证集上达到了96%的峰值准确率。评估显示,在测试集上的准确率也达到了97%,现在比简单的CNN要好得多!
品种分类模型
猫和狗的品种分类也是以同样的方式进行的。我们启动了一个图像生成器,使用15%的验证分割,因为每个品种的图像数量并不是那么大的™。
用2 5 6个提前停止回调和6 0个历元的批次大小训练犬种分类器ğŸ�·。模型采用ADAM优化器和稀疏分类交叉熵损失法编制而成。最终模型在验证集上的准确率达到77%。这是出乎意料的好的TOP-1准确率(与4%的基线相比)。在测试集上的评估结果表明,准确率为76%。虽然我们有很好的TOP-1精度结果,但是我们也检查了我们模型的TOP-3和TOP-5精度,因为这对于多类分类问题是可以接受的(见下文)。
使用相同的超参数进行猫品种分类ğŸ�ˆ,但验证分裂改为0.2.结果再次显示了在验证和测试集中77%的惊人结果!这比随机猜测要好近10倍!再次测量了TOP-3和TOP-5的精确度。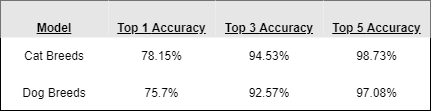
BonusğŸ元³
我们对我们的模型-™的结果非常满意,我们决定用它做一些有趣的事情。一般说来,品种是根据它们的遗传物质来区分的,其中一种表示遗传相似性的方法是使用™所说的系统发育树。这棵树通常是通过在比较的有机体上对遗传特征进行聚类而创建的。
我们的模型可以预测品种,而品种是系统发育树的一部分。那么为什么不在模型™的念力矩阵上进行聚类(更具体地说是层次聚类),看看这些品种之间的相似性呢?!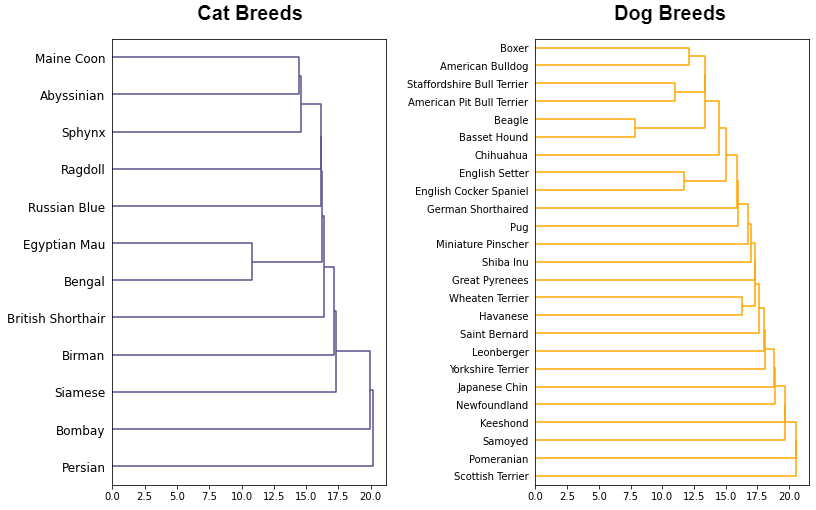
有趣的是,一些在现实中具有普遍亲缘关系的品种在树状图上彼此聚在一起。其中有斯芬克斯犬和阿比西尼亚犬,还有猎犬和巴塞特猎犬。当然,这不是完美的™,但仍然很酷!
(5)网页应用ğŸ·斧头
我们在项目中的最后一步是以其他人可以使用的方式部署我们的模型。为此,我们使用了Python的Streamlight模块。它允许将数据脚本转换为可共享的Web应用程序相当容易。Streamlit
这个应用程序目前正在工作,方法是克隆项目repo并从主目录执行Stretinglightrun app.py。
在应用程序中,你可以上传你选择的图片,并将物种分类和品种分类作为输出。该应用程序将输出所有品种及其概率,直到覆盖99%的分类概率。
结论-˜�ğŸ�»
我们的任务是为狗™和猫™的品种生成一个分类器。我们找到了一个品种数量有限的数据集,以便将我们的想法付诸实施。首先,当我们简单地构建CNN时,我们对区分猫和狗的能力进行了概念证明。该网络的结果还不错,但通过迁移学习也得到了很大的改善。
使用给出最佳结果的模型构建,将建模过程应用于不同品种,获得了非常好的TOP-1精度和接近完美的TOP-3和TOP-5精度。
总体而言,我们™为我们的项目和取得的成果感到自豪。在有限的硬件下处理大数据集的图像是一项挑战,但最终我们成功地超出了我们的预期。
至于KhaleesiğŸ�‰,正如你可能会想的那样,她?™‘s仍然是一个谜。她被我们的模特归类为小酒鬼,但她?™的成长之道实际上就是一个小酒鬼。我想需要用更多的品种来改进模型:)。
在LinkedIn上查找我们!
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/18/%e5%a6%82%e4%bd%95%e5%9b%9e%e7%ad%94%e5%85%b3%e4%ba%8e%e4%bd%a0%e7%9a%84%e5%ae%a0%e7%89%a9%e8%a2%ab%e9%97%ae%e5%be%97%e6%9c%80%e5%a4%9a%e7%9a%84%e9%97%ae%e9%a2%98/
