
什么是物体检测
物体检测是计算机视觉的一项被广泛研究的任务,计算机视觉是一个研究计算机如何从图像或视频中提取高级概念的科学领域。具体地说,目标检测就是在图像中定位感兴趣的元素并对它们进行分类。
一种现代物体探测器的体系结构
如今,探测器不能被认为是由单个大部件组成的单片系统。更合适的做法是将其视为由三个主要模块按顺序组成的体系结构,每个模块都有自己的特定功能,但都链接在一起。这三个要素将成为本帖子的主题,它们分别命名为主干、汇聚层和头部。
当图像被送入检测器时,它将经历三次不同的宏观计算,每个组件一次:主干部分将提取对任务有意义的视觉特征;聚合层(顾名思义)将跨不同尺度聚合这些特征以丰富所提取的信息;以及最终,头部将为场景中的每个对象生成边界框以及分类标签。
主干
主干的任务是提取对识别对象可能重要的视觉信息。例如,如果我们要检测图像中的狗,脊椎必须提取那些编码爪子、尾巴、鼻子等存在的特征;此外,提取的特征还应该编码自己在图像中的位置,因为头部将进一步细化这些信息,以输出狗的定位。通常的做法是从分类任务中借用这些主干的设计,因为它们在体系结构的这个阶段共享相同的目标,即提取表示对象类的区别特征。为了使它们与检测任务兼容,必须移除最后一个分类层(通常是完全连接的层),以便检测器的后续部分可以在将其分类之前访问本地化和分类特征。原则上,任何需要对图像进行推理的任务,如检测、语义分割、超分辨率,都可以依赖于该网络提取的特征,以便从高维像素图像到更小、更具语义的表示。这些模型中使用的典型操作是卷积,然后是池化和规格化层。通常,合并会被跨步卷积所取代,因为它们实现了相同的空间子采样,同时更好地保留了信息。在最近的文献中,一个很强的模式是沿着主干对输入图像进行5次下采样,要么是通过汇集,要么是通过跨步卷积。这种做法在很大程度上与研究社区使用的数据集及其图像输入大小有关。虽然下采样次数几乎是一个标准,但它们在体系结构中的位置是网络设计的关键部分,每个网络的位置都有很大变化。当输入给定分辨率的图像时,探测器的主干从图像中提取视觉特征,并逐渐降低其空间维度。主干的输出是在下采样之前的所有特征地图加上最终的特征地图的级联,以便将所有不同分辨率的特征提供给检测流水线中的下一步。具体地说,具有L个下采样层(例如,L=5)的主干的输出将由以下大小的张量列表组成:classification task fully-connected layer semantic segmentation super-resolution pooling strided convolutions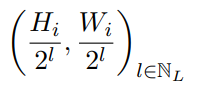
其中(H_i,W_i)是输入图像的尺寸。具有分辨率递减的L个特征地图,主干的输出通常被命名为特征金字塔,因为它们可以垂直堆叠以形成金字塔,如图2所示。
聚合层
骨干产生的特征金字塔包含头部定位和分类所需的所有信息,但这些信息位于金字塔内部的不同位置:较低级别(较高分辨率)的特征定位良好,具有较好的定位潜力;而较高级别(较低分辨率)的特征具有高度语义,但过于粗糙,无法进行适当的定位。聚合层的目标是将不同级别的要素地图混合在一起,以生成最终的金字塔,对所有级别的两个方面进行编码。由于主干执行的计算只有一个方向,即从较高的分辨率到较低的分辨率,最后一级可以从所有先前级别的信息中受益,但反之亦然。聚合层通常通过让信息从较低分辨率级别流向较高分辨率级别来在网络中添加相反的机制。通常的做法是仅通过串联或求和来聚合金字塔相邻级别的要素。这一体系结构的改变已经被证明给大量探测器带来了显著的性能提升。(工业和信息化部电子科学技术情报研究所陈皓)汇聚层的引入是骨干网现在具有金字塔输出而不仅仅是计算最后一个特征图的主要原因。事实上,较老的目标检测器只处理从主干接收到的最后一个特征图,并通过在输入图像的多个分辨率上重复检测来获得一定程度的尺度不变性。如今,聚合层被认为是实现多尺度检测的最佳方式和标准选择,因为它比多次运行检测器在计算上更高效。当然,多尺度检测不是强制性的,人们仍然可以将检测器设计为仅在没有任何聚合层的最后一个要素地图上运行。
头
检测器的最后一个组件-也是通常为整个方法命名的组件-是头部,预计它将定义网络的最终结果:在每个对象周围放置一个边界框,并放置一个标签来表示其类别。如果多个功能地图来自主干或聚合层,则通常会将头部分别应用于其中的每一个。磁头可以组合来自多个级别的信息的方式没有限制,但一次处理其中一个级别会使设计更加模块化,例如,可以添加或删除一个级别,而不必更改磁头的设计。因此,这是文献中的常见做法。头部需要定义三个主要方面才能正常工作:*如何表示图像中一个或多个对象的位置(或不存在)-这是通过编码步骤完成的;*如何处理来自聚合层的输入-这是由模型定义的;*如何处理学习过程中网络造成的错误-即损失函数。这三种设计选择将在本节的其余部分进行说明。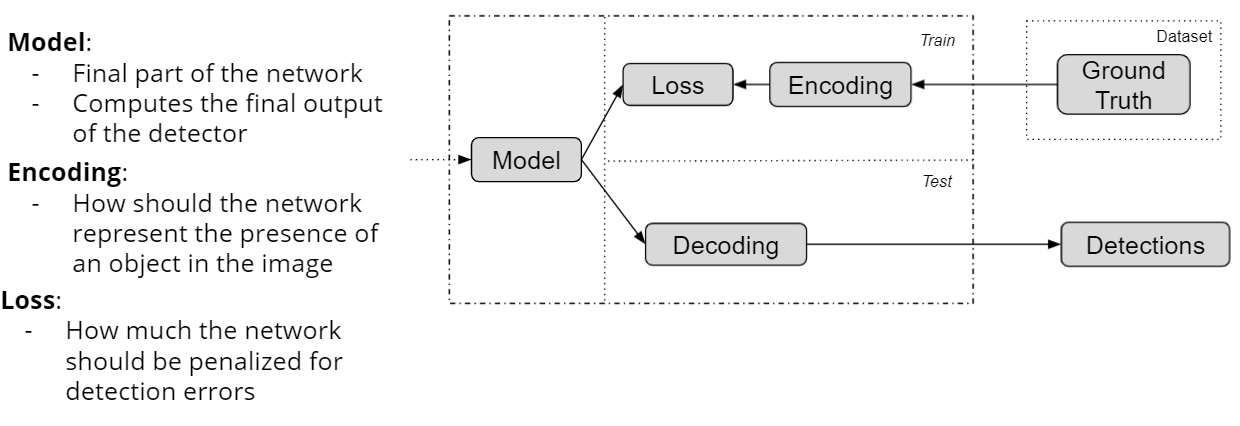
编码/解码
对神经网络来说,对无序边界框集合的预测不是一项微不足道的操作,如何表示它们也不是微不足道的:这些信息必须由网络设计者以一种适合学习的方式在网络中编码。该选择在训练时用于将地面真值框转换为网络表示,但也在测试时用于从网络预测转换为输出边界框。前一种情况称为编码步骤,而后者称为解码步骤。边界框的最基本描述是六个元素的元组:四个元素用于通知对象相对于输入图像的位置,一个元素用于描述其类别,最后一个元素传达预测的保真度,也称为置信度分数。对于地面真值框,根据定义,置信度分数设置为最大值。以下是边界框描述符的示例: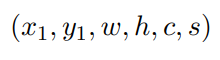
这里c∈{狗,猫,老虎,。。。}是类别标签,s∈[0,1]是置信度分数。在本例中,边界框的位置通过其左上角和大小信息明确表示,但是幂等描述包括中心坐标和大小(cx,cy,w,h)或左上角和右下角坐标(x1,y1,x2,y2)。根据检测器是否使用锚,可以根据编解码步骤将检测器分为两大类。锚点是对数据集中可能存在的检测的一些初始猜测。在基于锚点的检测器中,头部必须评估每个锚点,并产生与图像中的对象对齐的变形,或者为其分配较低的置信度分数以丢弃它。通过锚点,开发者可以注入一些关于数据集的先验知识,如比例或长宽比,大大简化了任务和学习过程;另一方面,锚点在测试时可能很难调整和限制检测器的泛化性能。此外,基于锚的检测器必须处理具有大量预测的固有模糊性,因此多个锚为完全相同的对象投票的情况并不少见-这种模糊性是通过在测试时间通过非最大抑制步骤解决的,可能导致次优结果。这就是为什么该领域的许多最新提案都集中在无锚点方法上。Non-Maximum Suppression
型号
该模型由一系列层组成,这些层将聚合层的输出投影到编码的地面真值框的相同表示空间中。在这个表示空间中,网络预测和真实数据是可比较的,这种损失可以弥补它们之间的差异。虽然编码步骤必须由开发人员显式定义,但只要张量维数符合表示空间,模型就会自己学习正确的投影函数。对于编解码步骤,检测器也可以根据建模方法分为两大类。具体地说,这两个系列是两阶段对一阶段:顾名思义,前者只有在定位了所有对象之后才执行分类任务;相反,后者的体系结构在一个并行步骤中产生两个结果。
损失
损失函数定义网络在预测图像中的一个或多个对象的定位和分类时产生的误差量。损失必须说明有关盒子坐标、误报和类别标签的错误。这些误差通常由三个不同的函数计算,然后将这些函数与不同的贡献权重聚合在一起,形成最终的损失值。不同的损耗公式或参数化可能会得出完全不同的结果。
这篇文章摘录自我在深视咨询实习期间撰写的硕士论文,一定要看一看!master thesis Deep Vision Consulting
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/18/%e5%af%b9%e7%8e%b0%e4%bb%a3%e7%9b%ae%e6%a0%87%e6%8e%a2%e6%b5%8b%e5%99%a8%e4%bd%93%e7%b3%bb%e7%bb%93%e6%9e%84%e7%9a%84%e9%ab%98%e7%ba%a7%e7%90%86%e8%a7%a3/
