
当今商业所采用的人工智能的一种主要形式是计算机视觉/OCR。它有多好用,使用起来有多难?
作为一名软件开发人员,很容易忘记并不是所有的世界都运行在Web表单上。在那里,有些人仍然可以接触到这种叫做纸的东西。还有钢笔。如果他们需要复印一份表格的复印件,然后把它塞进某人的口袋里,这样他们就可以手工填写了,那就这样吧。这是他们愿意付出的额外努力。
这意味着并不是运行许多业务所需的所有信息都以机器可读的格式到达。其中很多仍然是手工加工的。由于未能将客户转移到完全数字化,企业正转向人工智能来填补这一空白。在文档领域,计算机视觉/OCR扮演着重要角色,但它真的能解决问题吗?
快速入门:使用Amazon TExtract
为了解决这个问题,让我们看看一个特定的OCR服务:Amazon TExtract。他们自己的描述说,这项服务“自动从扫描的文档…中提取文本和数据。超越了简单的光学字符识别(OCR),还可以识别表单中字段的内容和存储在表格中的信息。“Amazon Textract
如果您有AWS帐户,您可以非常快速地第一眼看到这一点(如果您没有,以下是说明)。只需转到TExtract演示页面,您就可以将文件拖放到页面上,并立即看到结果。它看起来是这样的:instructions demo page 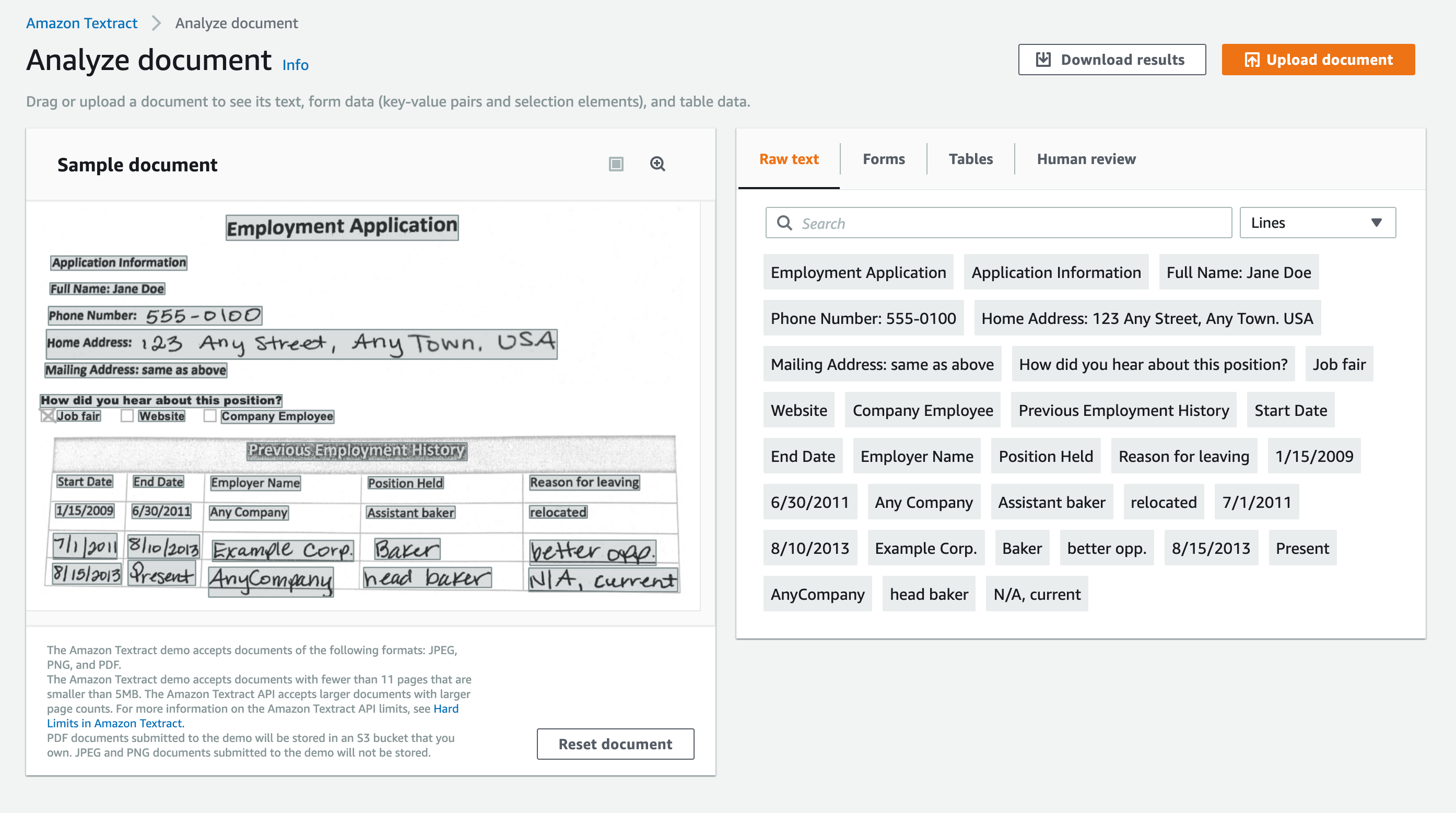
如果这是您第一次使用此演示页面,它将为您设置一个S3存储桶来存放您上传的文件,并在以后每次您通过控制台进行测试时再次使用此存储桶。请注意,如果您不希望测试文件挂在您的帐户中-它们不会自动删除,如果您不想保留它们,则需要手动删除。S3
除了查看结果之外,您还可以从控制台下载输出。这项服务有三种不同的“口味”:
- 直接OCR/文本提取
- 表单提取(检测并从表单中提取键值对)
- 表格提取(检测并从文档中提取表格格式)
不同的服务有不同的端点和价格。每个响应都以JSON格式带回大量信息。它包括文本、几何图形(位置)、有关单词之间连接的详细信息、在单词和行级别提取的置信度分数、是否为手写的指示器等。这意味着JSON响应可能非常长,特别是在您有一个多页文档的情况下-如果您选择查看它,您可能会发现文本编辑器很难处理一些较大的响应。这意味着JSON响应可能非常长,特别是当您有一个多页文档时-如果您选择查看它,您可能会发现您的文本编辑器很难处理一些较大的响应。从一个相对较小的文档开始,感受一下它。prices
当您开始以编程方式使用它时,我强烈建议您不要尝试编写自己的所有代码来解析响应(这是非常紧张的)。库/代码示例(如TExtract、响应解析器和Textacter)将使您的工作变得容易得多!如果您正在寻找如何将服务连接到您的应用程序的示例架构,这里有一个很好的示例:Amazon TExtract无服务器文档处理。Textract Response Parser Textactor Amazon Textract Serverless Document Processing
回到现实世界

现在您对Amazon TExtract有了一些了解,让我们回到最初的挑战-自动化传入表单/文档的接收处理。人工智能已经为我们解决了所有的问题吗?我所在的团队已经看了很多表格,虽然我们对这项技术印象深刻,它确实能够提取我们所需的大约80%,但仍然存在一些真正的挑战。以下是我们发现的一些主要原因:
格式-表单标签传统的OCR已经存在很长时间了,如果您知道表单的确切布局,您可以利用这些知识编写代码,将信息映射到其他地方。挑战在于,大多数表单的信息没有以一种易于接受的方式清晰地布局。它们有多种布局,附加到值的表单标签可以在旁边、顶部、下方或其他一些有趣的组合。手动编码和维护每个表单的映射既繁琐又脆弱。然而,在这里,TExtract的表单提取服务真正发挥了作用,它做了一项非常出色的工作,允许我们只维护键映射,而不是位置映射。
在这里,您可以看到它将标签和值链接到不同的布局和位置。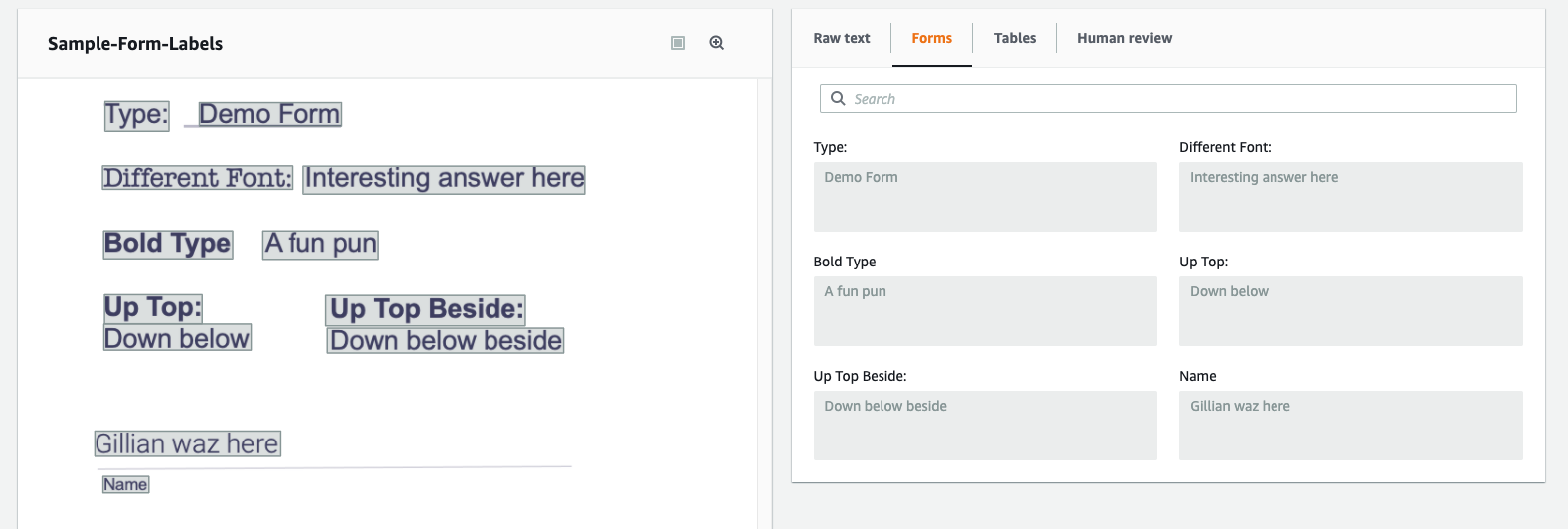
格式选择框像表单域一样,选择框有各种形状、大小和布局。为了成功地从选择元素中提取值,您需要能够识别它是选择元素,识别它是否被选中,并将其与正确的标签相关联。
TExtract的表单提取服务在拾取选择框方面非常出色,它会告诉您它们是否被选中。当复选框旁边的值必须与另一个值关联才有意义时,挑战就来了。例如,如果您查看下面的示例,会发现有两组标记为“是”和“否”的复选框。
将它们放入TExtract表单提取,我们可以看到它们都被识别出来,以及它们是否被选中。知道“Yes”是在没有其他信息的情况下选择的,但是如果没有用的话–你需要知道它与什么问题有关(“Gillian是不是很棒”)。这意味着我们必须重新理解有关表单的一些位置信息,并手动匹配选择框。这项服务让我们完成了一部分工作(找到选择框,告诉我们它们在表单上的位置和选择的状态),但我们这边还有一些重活要做。
质量不佳的表单
很多表格仍然是扫描进来的,或者来自照片(例如收据)。这可能会导致表单褪色、变暗或倾斜(可能会切断一些文本)。打印或传真不佳的表单可能会有条纹。有一百万种方式可以让表单从数字化开始,然后绕道进入现实世界,然后以数字格式结束。虽然我们发现TExtract可以很好地处理这些场景中的大多数,但它仍然在文本被切断或模糊的地方挣扎(对于任何OCR服务来说,这都是一个合理的问题)。
颜色
有些人喜欢五颜六色的表格,或者喜欢亮出他们的荧光笔。不同的颜色可能会导致某些提取失败,因为文本和页面之间的对比度在整个文档中各不相同。
手写表格
正如一开始所说的那样,手写的表单比您想象的要多。手写识别是最近几年才开始真正变得很好的东西。笔迹在2020年底被添加到TExtract中,我们发现它可以处理范围广泛的笔迹样本。
然而,…挑战依然存在。手写表单有双重挑战-既有手写本身,也有将被扫描的事实,因此质量可能较低。TExtract处理笔迹的能力真的令人钦佩,但实际上,即使是人类也不能一直阅读他人的笔迹。以下是我们看到的一些具体挑战:
- 许多表单实际上都是为键入而设计的,因此这些字段通常比手写理想的字段要小。这意味着人们会写得很小,重复行数,词与词之间不留空格,或者只是编造自己的空格来写字。
- 在手写表单上,您可以做在打印表单中不可能做的所有事情。例如,在表格中覆盖多个框,或者在表单的侧面添加注释。即使服务读取了这些内容,也很难将它们绑定回特定字段。
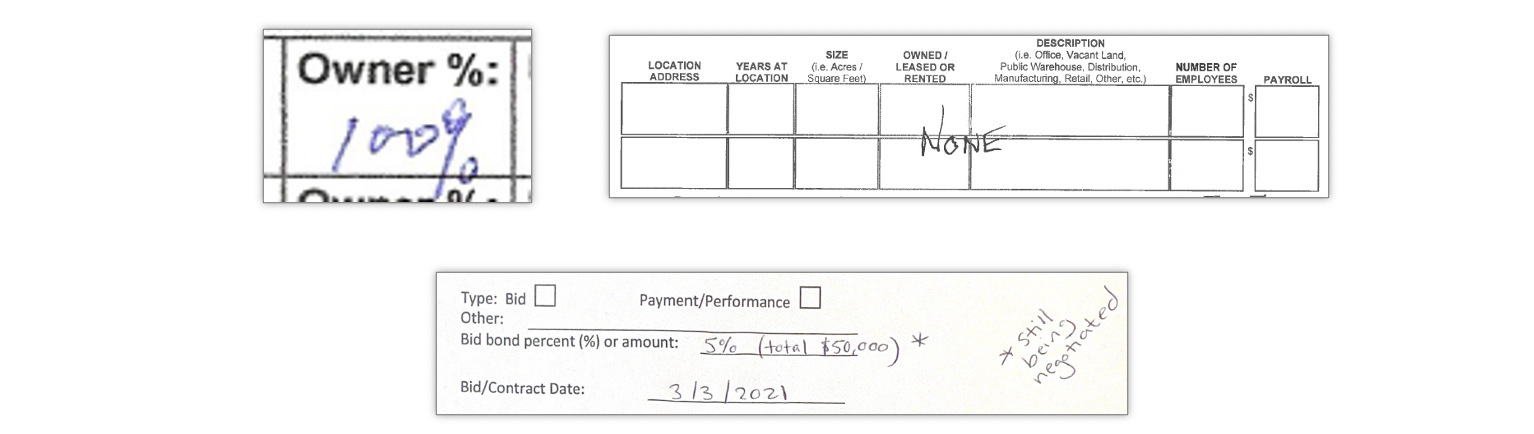
- 人们会犯错,然后草草写下东西。理解不计算划掉的东西是一个语义过程。计算机会将它认为看起来像文本的任何东西读成文本。
- 有时文字真的很难辨认。即使是另一个人也看不懂,所以电脑就没有机会了!
为了向你展示哪里可能出问题,这是我笔迹的第二个样本。您可能会注意到,这一次的“提醒”被选为“remiddes”。你能找出原因吗?
首先,我把“d”改成了“n”,但“d”对计算机来说仍然足够清晰,以至于它胜过了“n”。其次,我把“e”和“r”连在一起,恰到好处地让它看起来更像一个“s”–最后得到的是remiddes,而不是提醒。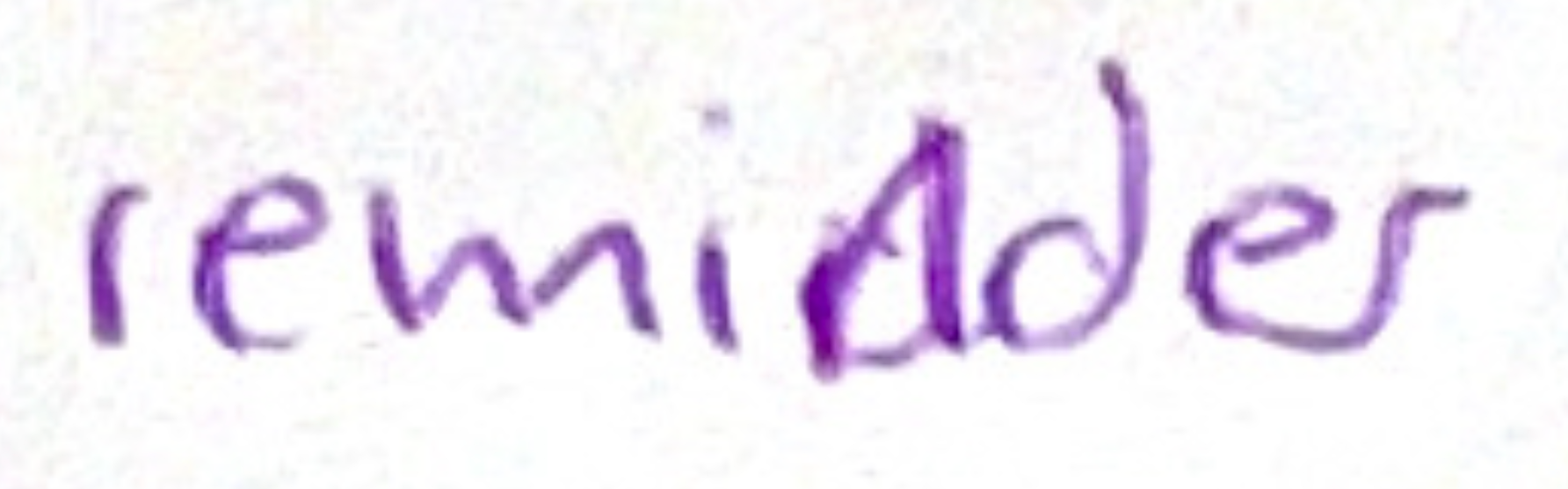
人类在阅读时会隐含地添加很多上下文,所以当事情不清楚时,他们有能力更好地“猜测”(或者去问别人)。我认为在接下来的几年里,我们会看到越来越多的语义感知服务出现,但它们的关注点从一开始就会相当狭窄。
结论
推动文档理解的计算机视觉/OCR技术在过去几年中已经变得非常令人印象深刻,将它们作为商品服务提供意味着它是任何企业都非常容易获得的东西。如果您对表单上的预期布局和字段有详细的了解,使用此技术应该可以使其几乎完全自动化。但是,要动态理解任何形式,需要具备以下方面的一些语义知识:
- 逻辑分组(复选框附带的问题、标签附带的节标题等)
- 预期的值类型(“此字段应为日期”等),以便在值不明确的情况下进行更好的预测(手写不好、模糊等)
这两个都有他们自己的挑战,值得写一篇自己的博客文章!我确实认为这些事情将会到来-首先是针对特定类型的文档/表单的狭窄区域,然后扩展到能够概括到任何文档。
我很想看看接下来会发生什么!如果你也很想知道下一步是什么,对ML感兴趣,或者有问题,请在Twitter(Virtualgill)上与我联系,让我们聊天!twitter irtualgill
进一步阅读:通过查看AWS ML博客https://aws.amazon.com/blogs/machine-learning/category/artificial-intelligence/amazon-textract/上的这些帖子,更深入地了解您可以使用TExtract做的一些有趣的用例或事情https://aws.amazon.com/blogs/machine-learning/category/artificial-intelligence/amazon-textract/
另外,在自己编写所有内容之前,请查看AWS提供的大量代码示例。不幸的是,现在并不是所有的文件都带有“tExtract”标签,所以您必须稍微手动执行search!https://github.com/aws-samples?q=textract&type=&language=&sort=。https://github.com/aws-samples?q=textract&type=&language=&sort=
编码愉快!
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/23/%e4%ba%9a%e9%a9%ac%e9%80%8atextract-vs-the-world%e8%a1%a8%e6%a0%bc%e4%b8%96%e7%95%8c-2/
