
目录:
- 问题说明
- 了解数据
- 现有方法
- 探索性数据分析
- YoloV3
- YoloV5
- 使用烧瓶进行部署
- 应用程序演示
无论是发展中国家还是发达国家,公路都是社会和经济发展的重要组成部分。但由于我们清楚地意识到,政府组织(如市政当局)维护这一点是一个巨大的挑战,许多研究人员已经沉迷于寻找多种方法来开发一种有效和合适的方式来帮助市政当局。如果不定期检查路面状况,那么由于天气、交通、老化、材料选择不当等多种因素,道路状况会逐渐恶化。
一些机构部署了由多个昂贵的传感器和高分辨率摄像机组成的道路勘测车辆。有一些经验丰富的道路管理员对道路进行监督和目视检查。但是这些方法当然是非常耗时和昂贵的。即使在检查完成后,这些机构也很难保持记录的结构损伤的准确和最新的数据库。
这种管理不善导致道路维修的资源分配没有组织和不适当。
因此,我们需要一种廉价、快速和有组织的解决方案来进行这种道路损坏检测。如今,我们非常幸运,几乎每个人都携带一部基于相机的智能手机。因此,随着人工智能中对象检测技术的出现,人们已经开始在这一领域发起挑战和研究,日本的市政当局已经开始使用这种基于智能手机的人工智能技术来进行道路损坏检测。因此,这个案例研究试图使用一些最先进的技术来建立一个模型,试图使用人工智能工具来检测多种类型的道路损坏,如坑洞、鳄鱼裂缝等。
了解数据
数据集可从以下网址下载:https://github.com/sekilab/RoadDamageDetector/https://github.com/sekilab/RoadDamageDetector/
训练数据集包含日本/印度/捷克图像和注释。注释的格式与Pascal VOC相同。这项研究中提出的数据集考虑了从多个国家收集的数据-日本、印度和捷克(部分来自斯洛伐克)。
什么是PASCAL VOC格式?
与包含json文件的coco格式不同,它是一种包含每个图像的XML文件的图像数据格式。XML文件包含与在图像中找到的对象类相关的所有信息,以及它的边界框坐标等。
图像数据包含三个文件夹:捷克、印度和日本。每个文件夹包含两个子文件夹:批注和图像。子文件夹“Annotation”包含所有图像的所有XML文件,该子文件夹“Image”具有相同的文件名,但扩展名相同。
图像总数增加到26620张,几乎是2018年主流数据集的三倍。从印度和捷克(部分来自斯洛伐克)收集了新的图像,以使数据更加异质,并训练稳健的算法。虽然道路损坏类别有多种类型,但数据集侧重于以下类型:
- D00:线裂纹、纵裂、轮痕部件
- D10:线性裂缝,横向,等间距
- D20:鳄鱼裂缝
- D40:坑洼、车辙、倾倒、分隔
- D43:十字路口模糊
- D44:白线模糊
- D50:通用孔(维护舱口)
参考:(PDF)用于道路损坏检测的生成性对抗性网络(Research gate.net)(PDF) Generative adversarial network for road damage detection (researchgate.net)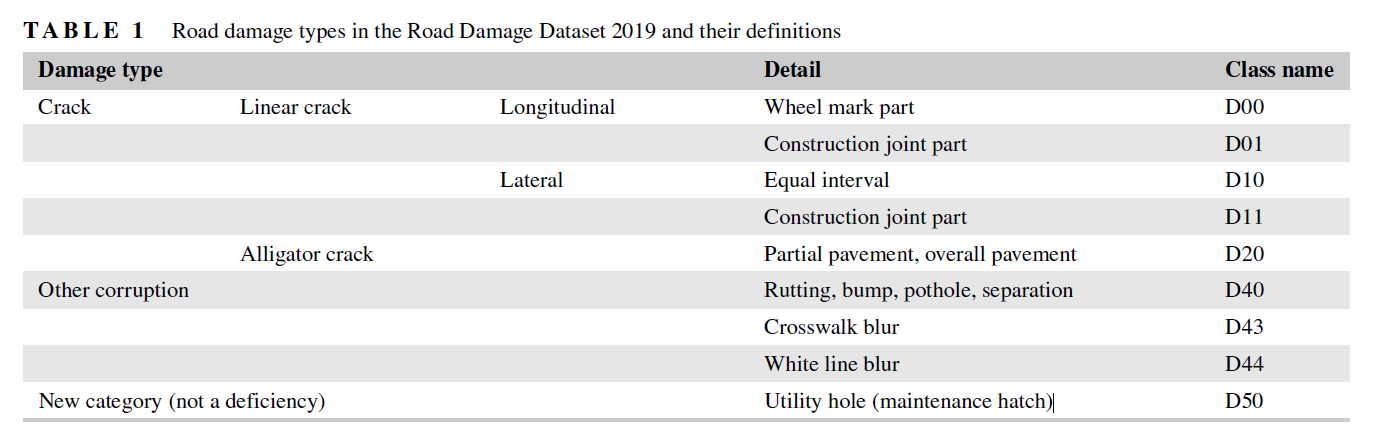
请注意,与评估道路标记劣化(如人行横道或白线模糊)相关的标准在几个国家之间差别很大。因此,这些类别被排除在研究之外,以便可以训练适用于监测多个国家的道路状况的通用模型。
探索性数据分析
现在,此数据集是Pascal VOC格式的XML文件。对于EDA,我会先将它们转换为CSV。为此,您可以参考以下代码:Pascal voc XML to CSV table·giHubpascal voc xml to csv table · GitHub
因此,我们为每个国家/地区数据创建一个CSV文件,因此我们得到三个CSV文件。然后,我们将这三个文件连接成一个,以获得主CSV文件。因此,我们的最终数据帧如下所示: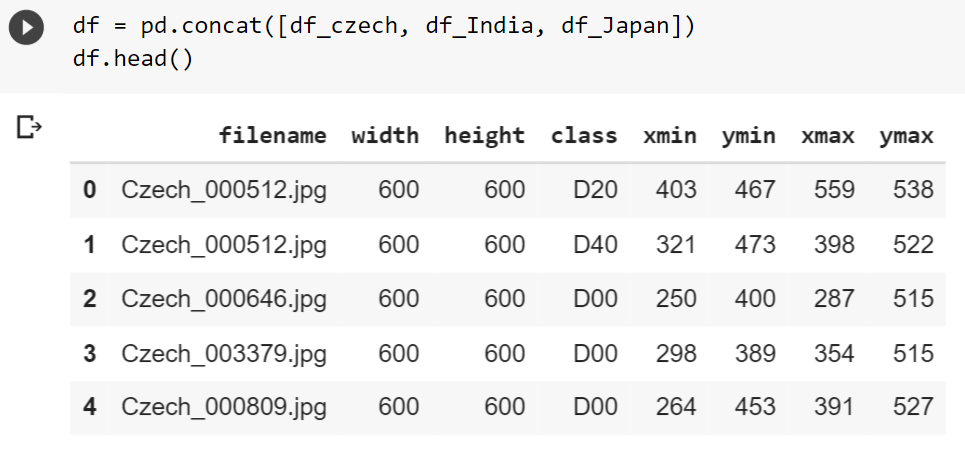
如您所见,对于每个图像,我们都有图像的尺寸、边界框的位置和损坏类型类别。
现在让我们来看一下类分布: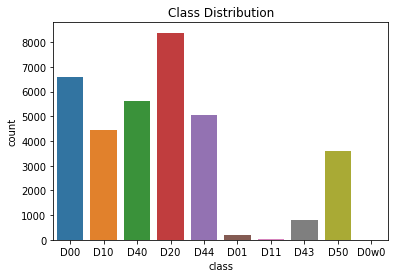
- 可以看到有10种不同级别的损害赔偿。
- 数据不平衡,D43级(横行模糊)、D01级(纵向施工缝裂缝)、D11级(横向施工缝裂缝)和D0w0级非常稀缺,而D20级(扬子鳄裂缝)非常丰富。
- 因此,您可能会考虑删除所有带有D43、D01、D11和D0w0的条目。在我的例子中,我删除了这4个类条目,并将其设为6个类标签的问题。移除后,让我们看看类的面积分布:
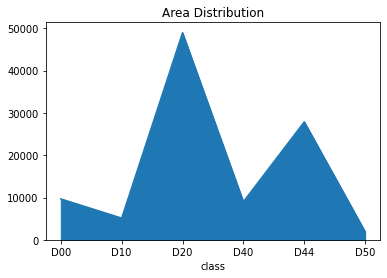
- 让我们看看面密度曲线:

现在让我们看看我们的目标是什么。我们有一幅道路的图像,我们想要检测一个包围盒,该包围盒限定了道路上的损坏区域,并检测到损坏的类型。因此,为了理解,我拍摄了这些图像,并在训练数据中画出了给定的边界框。
捷克语:
印度:
日本:
现在,让我们继续前进,看看一些现有的方法。
现有方法
论文1:https://arxiv.org/pdf/2008.13101v1.pdfhttps://arxiv.org/pdf/2008.13101v1.pdf
论文2:https://arxiv.org/ftp/arxiv/papers/1909/1909.08991.pdfhttps://arxiv.org/ftp/arxiv/papers/1909/1909.08991.pdf
我尝试了三种模型来解决这个问题:
这三个结果都有很大的不同。我将为这三个人解释“如何定制训练模型”,并分享我的观察结果。
让我向您介绍每种解决方案。
YoloV3
准备数据集:
首先,也是最重要的,为每个国家/地区创建一个图像文件夹,而不是三个不同的文件夹。获取我们决定使用的6个类对应的图片,删除睡觉图片。为此,我们需要将图像保存在我们已经创建的CSV文件中。
步骤1:为感兴趣的图像创建一个txt文件。
步骤2:为不需要的图像创建txt文件。
第三步:删除不需要的图片。
步骤4:现在您在一个文件夹中有了所有感兴趣的图像,我们将创建另一个名为“Labels”的文件夹,在该文件夹中,我们将为每个图像创建一个.txt文件,该文件将包含图像中对象的对象类和坐标,语法如下:
第5步:现在您有两个文件夹(“图像”和“标签”),您需要从这里下载“Darknet”。你也可以克隆它。here
第六步:在Darknet文件夹中,你会看到一个“Makefile”。编辑该Makefile并设置GPU=1、CUDNN=1和OpenCV=1。
步骤7:下载在Imagenet上训练的暗网预训模型,并将其放入“Darknet”文件夹中。darknet pre-trained model
步骤8:现在移动您在“Darknet/Data”文件夹中创建的“image”和“labels”文件夹。
步骤9:进入“DarkNet/cfg”文件夹,创建一个“yolov3.cfg”的副本,并将其重命名为“yolov3_CUSTOM_Train.cfg”。现在在这个“yolov3_Custom_Train.cfg”文件中进行更改:
- 在第8&9行,根据您的图像或您的选择更改“宽度”和“高度”。
- 在第20行,您可以使用“max_batches”。
- 在第603、689和776行,您可以使用公式(Filters=(CLASSES+5)*3)设置“Filters”。
- 在第610、696和783行,将“CLASSES”设置为等于6,因为我们有6个不同的类。
步骤10:因为我在Google CoLab上接受过培训,所以我想在每100个纪元之后保存权重,因此我将“Darknet/Examples”文件夹中“Detector.c”中的第138行更改为:
- 如果(i%1000==0||(i<1000&&i%100==0)){
步骤11:现在是将数据集拆分为训练集和验证集的时候了。为此,我们需要两个.txt文件“train.txt”和“val.txt”,它们应该分别包含列车图像和验证图像的目录路径。
第12步:现在在“Darknet/Data”中创建包含类名的“yolo.ames”文件。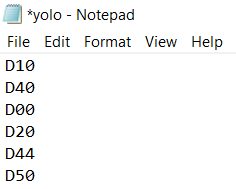
步骤13:在“Darknet/Data”中创建“yolo.data”。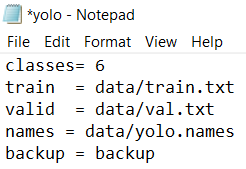
培训yoloV3:
现在你已经准备好了你的暗网文件夹,把它压缩并上传到google驱动器上。现在打开Google CoLab并将运行时更改为GPU。有关培训说明,您可以在这里查看我的CoLab笔记本中的yoloV3。here
结果:
结果真的真的很差。箱子的尺寸很大,没有检测到它应该有什么。对于EX:
我还上传了保重测试笔记本,在这里。here
YoloV5
准备数据集:
步骤1:创建两个文件夹“image”和“labels”,就像您在yoloV3中所做的那样。但是这里不要把所有的图像一起放在“图像”文件夹中。而是在“图像”文件夹和“标签”文件夹中创建子文件夹“Train”和“Valid”。
步骤2:将所有图像拆分到上面创建的Train和Valid文件夹中。与随机复制粘贴不同,您可以通过编写脚本并使用包含训练图像和验证图像的目录路径的“train.txt”和“val.txt”文件来执行此操作。在训练上面的yoloV3时,我已经创建了那些txt文件。
因此,您的数据目录现在应该如下所示:
步骤3:使用以下命令克隆yoloV5存储库:
!Git克隆https://github.com/ultralytics/yolov5https://github.com/ultralytics/yolov5
步骤4:克隆完成后,进入yolov5目录,打开datet.yaml文件,根据您的配置进行编辑。在我的案例中:
第四步:您可以从yolov5/model中选择不同的机型。例如,“yolov5l”(大)、“yolov5s”(小)、“yolov5x”(最大)等,您选择的模型越大,参数的数量就越多。因此,选择您的模型并将其复制到“Models”子文件夹之外的“yolov5/”。确保你只把一个模型放在外面。在我的例子中,我选择了“yolov5l.yaml”
步骤5:在“yolov5/”,(yolov5l.yaml)中打开选中的模型,更改:
- 第2行,将“NC”设置为6(类数)。
- 第3&4行,“Depth_Multiple”和“Width_Multiple”等于1.0。
培训:
现在您已经配置了“yolov5”文件夹,将其压缩并上传到Google驱动器上。打开Google CoLab并挂载您的驱动器。您可以在这里查阅我的培训笔记本。here
结果:
结果非常令人满意。在大多数情况下,模型以适当的类别检测到了损害。这就是为什么我决定继续训练yoloV5的重量。
使用烧瓶进行部署
现在已经很好地训练了模型,下载训练后获得的权重,让我们部署并创建一个网页。
出于部署目的,我使用了Flask。Flask是一个简单的Web框架,也称为微框架,在Python中,它不需要繁重的库,用于开发应用程序。
因此,我们需要一个拥有端到端管道的python文件,该管道可以接收图像并返回带有边界框的输出图像。创建一个“app.py”文件,并编写一个函数,该函数只负责将图像作为输入,并将其输出保存到本地的某个位置。您可以获取“yolov5”目录中的“Detect.py”文件,并在这里和那里进行一些调整,以根据您的要求对其进行操作。假设您的函数已经准备好了,那么在下面您可以创建用于呈现html文件和上传图像的Flask函数。您可以查看我的app.py文件。app.py
显然,你需要你的html文件,你可以根据你的喜好来设计它。
应用程序演示
今后的工作
这个问题还有很大的余地。我想尝试TensorFlow2.0提供的最先进的EfficientDet Weight,但由于GPU和时间的限制,我无法尝试太多。但这肯定有很大的余地。
另外,使用yoloV5,我在CoLab上只训练了34个时期。人们绝对可以尝试运行大约99个时代,看看性能是否有所改善。
因为,我的资源有限,这就是为什么我使用数据集中提供的图像进行培训。虽然图像的数量是足够的,但人们仍然可以尝试使用多种图像增强技术来看到任何改进。
参考文献:
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/01/%e5%9f%ba%e4%ba%8e%e4%ba%ba%e5%b7%a5%e6%99%ba%e8%83%bd%e7%9a%84%e9%81%93%e8%b7%af%e6%8d%9f%e4%bc%a4%e6%a3%80%e6%b5%8b-2/
