
用简单的语言表达难懂的概念。
目标检测包括分类和定位两个独立的任务。上次我报道了R-CNN系列的物体探测器。R-CNN系列目标检测器由两个阶段组成,即区域建议网络和分类和盒精化头。然而,现在我们将继续讨论单级物体探测器。在这篇文章中,我想介绍一下单次放炮多盒探测器(SSD)。
上一次:
RCNNRCNN
快速RCNNFast RCNN
FPNFPN
更快的RCNNFaster RCNN
包围盒回归
与更快的R-CNN一样,作者回归到默认边界框(D)的中心(Cx,Cy)及其宽度(W)和高度(H)的偏移量。因此,公式如下所示:
架构
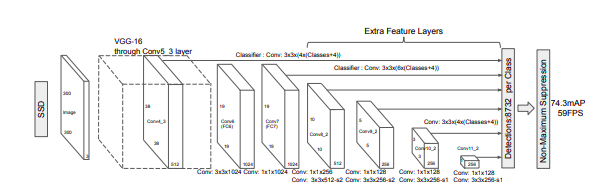
上图显示了以VGG-16为主干的架构。我将通过将其分为3个部分来解释该体系结构:主干、辅助卷积和预测卷积。为了您的方便,我还将提供一些代码片段。
基础网络
我想强调的是,以下示例是在假设输入图像的大小为300×300的情况下提供的,与原始论文相同。
由此可见,我们使用了一个简单而著名的VGG-16网络来提取vv4_3和vv7的特征。另外,我们可以注意到特征尺寸分别是(N,512,38,38)和(N,1024,19,19)。我希望这一部分足够简单明了,可以继续讨论公理卷积。
辅助卷积
辅助卷积使我们能够在我们的基础VGG-16网络之上获得额外的功能。这些层的大小逐渐减小,并允许在多个尺度上进行检测预测。因此,我们传递到网络的输入是从VGG-16网络获得的Conv7特征。在使用卷积和RELU激活函数时可以看到,我们应该保留中间特征,分别是v8_2、vv9_2、v10_2和v11_2,请慢慢来看一下代码和特征图的维度:)
选择默认边界框
这听起来可能很可怕,但不要担心,它仍然很容易掌握。默认边界框是手动选择的。将为每个要素地图图层指定一个比例值。例如,Conv4_3检测最小比例为0.2(有时为0.1)的对象,然后线性增加到Conv11_2的比例0.9(从辅助卷积获得)。此外,正如我们可以注意到的那样,我们在每个功能地图中的每个位置都考虑了一定数量的先前框。对于进行4个预测的图层,SSD使用4种不同的纵横比,即1、2、0.5和sqrt(s_k*s_(k+1)),其中s_k是第k个要素地图的比例值。一般定义为长宽比为1时计算的附加比例,默认框的宽度和高度计算如下:
现在,让我们用下面的一段代码进行总结。
其中,它返回8732个先前框,用于SSD做出的8732个预测。
预测卷积
这看起来可能很复杂,但它基本上获得了我们从基本VGG-16和辅助卷积中获得的所有要素地图,并应用卷积图层来预测每个要素地图的类别和边界框。花点时间去理解它,并通过注意功能地图的尺寸来确保您遵循它。
摘要
现在让我们把它们放在一起,看一下最终的架构,如下所示。
请注意,较低级别的特征(Conv4_3_Feats)具有相当大的比例,因此我们采用L2范数并重新调整其比例。重定标系数最初设置为20,但在后支撑期间为每个通道学习。
损失
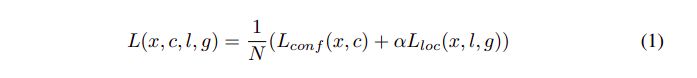
可以看到,我们已经从R-CNN系列的前几篇文章中熟悉了它。局部化损失是L1平滑损失,而分类损失是众所周知的交叉熵损失。
匹配策略
在训练期间,我们需要确定哪些生成的先前框应与要包括在损失计算中的地面事实框相对应。因此,我们将每个地面实值框与具有最高Jaccard重叠度的先前框进行匹配。此外,我们还选择重叠至少为0.5的先前盒子,以允许网络预测多个重叠盒子的高分。
硬性负挖掘
在匹配步骤之后,大多数先前/默认框被用作负样本。然而,为了避免正负样本之间的不平衡,我们将比例保持在最高3:1,因为这会导致更快的优化和稳定的学习。同样,本地化损失仅在正(非背景)先验上计算。
一些临终遗言

我希望我设法使SSD易于理解和掌握。我尝试使用代码,以便您能够可视化该过程。不要着急去理解它。而且,如果你试着自己使用它,那就更好了。下一次我将写关于YOLO系列物体探测器的文章。
原稿:https://arxiv.org/pdf/1512.02325.pdfhttps://arxiv.org/pdf/1512.02325.pdf
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/05/%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b%e8%a7%a3%e9%87%8a%ef%bc%9a%e5%8d%95%e5%8f%91%e5%a4%9a%e7%9b%92%e6%8e%a2%e6%b5%8b%e5%99%a8/
