
本文介绍了ASMNet,一种轻量级卷积神经网络(CNN),用于野外人脸标志点检测(也称为人脸对齐)和人脸姿势估计。
代码和预先训练的模型可以在Github上找到。你也可以在这里阅读原版报纸。here here
引言
人脸标志点检测是许多人脸图像分析和应用中的一项重要任务。这对于人脸图像对齐、人脸识别、姿态估计和表情识别都是至关重要的。目前已经提出了几种人脸标志点检测方法,如基于约束局部模型的方法[1,2]、AAM[3,4]、部分模型[5]和基于深度学习(DL)的方法[6,7]。虽然基于DL的方法被认为是最先进的方法,但对于姿态变化较大的人脸来说,人脸标志点检测仍然具有挑战性。因此,实现高精度所付出的代价是计算复杂度的增加和效率的下降。
此外,特征中包含的信息层次化地分布在整个深层神经网络中。更具体地说,虽然较低层包含关于边缘和角点的信息,因此更适合于诸如面部地标点检测和姿势估计之类的定位任务,而较深层包含更抽象的信息,其更适合于分类任务。受多任务学习思想的启发,我们设计了CNN模型,并由此设计了关联损失函数来同时学习多个相关任务。
最近的方法都集中在提高精度上,这通常是通过引入新的层、增加参数的数量和更长的推理时间来实现的。这些方法在桌面和服务器应用中是准确和成功的,但随着物联网、移动设备和机器人技术的发展,对更准确和高效的算法的需求越来越大。
受MobileNetV2的启发,我们提出了一种新的网络结构,该网络结构是专门为人脸标志点检测而设计的,重点是使网络变浅变小,而不会损失太多的准确率。为了实现这一目标,我们提出了一种新的损失函数,它使用ASM作为辅助损失,并使用多任务学习来提高精度。图1描绘了我们提出的想法的总体框架。我们使用具有挑战性的300W[8]数据集和更广泛的野外面部地标(WFLW)数据集[9]测试了我们提出的方法。我们的实验结果表明,人脸识别的准确率较高。
ASM网络
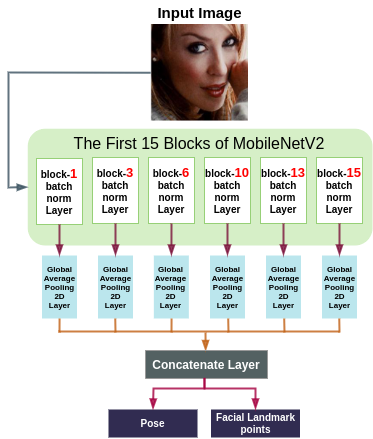
我们设计了一个大约比MobileNetV2[33]小两倍的网络,无论是参数数量还是FLOP数都是如此。在设计ASMNet时,我们只使用MobileNetV2[33]的前15个块,而主架构有16个块。然而,创建浅层网络最终会降低系统的最终精度。为了避免这个问题,我们特意添加了几个新层。图1显示了ASMNet的体系结构。
此外,在CNN中,较低的层具有更适合于地标定位和姿态估计等任务的边缘和角点等特征,而较深的层包含更抽象的特征,更适合于图像分类和图像检测等任务。因此,针对相关任务同时训练网络可以构建可以提高每个任务的性能的协同效应。
因此,我们设计了一个多任务的CNN来同时检测面部地标和估计人脸的姿势(俯仰、侧滚和偏航)。为了使用不同图层的功能,我们从挡路-1-批次-归一化,挡路-3-批次-归一化,挡路-6-批次-归一化,挡路-10-批次-归一化,最后挡路-13-批次-归一化创建了快捷方式。我们使用全球平均池层将这些快捷方式中的每一个都连接到MobileNetV2的挡路15(挡路15-ADD)的输出。最后,我们将所有的全局平均池层连接起来。这样的架构使我们能够使用在网络的不同层中可用的功能,同时保持较小的FLOP数量。换句话说,由于最初的MobileNetV2是为图像分类任务-EURO而设计的,其中需要更抽象的特征-EURO“它可能不适合面部对齐任务-EURO”,它既需要在更深的层中可用的抽象特征,也需要在较低层中可用的特征,如边缘和角。
此外,我们还向网络中添加了另一个相关任务。如图1所示,提出的网络预测两种不同的输出:面部标志点(网络的主要输出)以及面部姿势。虽然这两个任务之间的关联和协同可以产生更准确的结果,但我们也希望我们的轻量级ASMNet能够预测人脸姿势,以便它可以在更多的应用中使用。
ASM辅助损失函数
我们首先回顾了主动形状模型(ASM)算法,然后介绍了我们基于主动形状模型定制的损失函数,它提高了网络的精度。
活动形状模型查看
主动形状模型是一种形状对象的统计模型。每个形状用n个点表示,S集在公式中定义。1在以下内容中:
为了简化问题和学习形状分量,将主成分分析(PCA)应用于从K个训练形状样本计算的协方差矩阵。一旦建立了模型,使用公式计算任何训练样本(S)的近似值。2: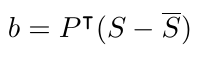
因此,可变形模型的一组参数由矢量b定义,从而通过改变矢量的元素来改变模型的形状。考虑b的第i个参数的统计方差(即特征值)为i。为了确保应用ASM后生成的图像与地面真实情况相对相似,矢量b的参数bi通常被限制为±3?ˆš?i[7]。该约束确保生成的形状与原始训练集中的形状相似。因此,根据公式,我们在应用此约束后创建新的shapeSN ew。3: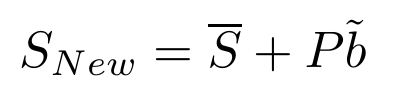
这里bµƒ是受约束的b,我们还根据公式定义了ASM算子。4: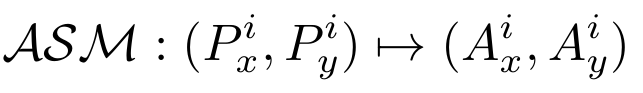
ASM使用等式将每个输入点(px i,py i)转换为一个新点(aix,aiy)。1、2和3。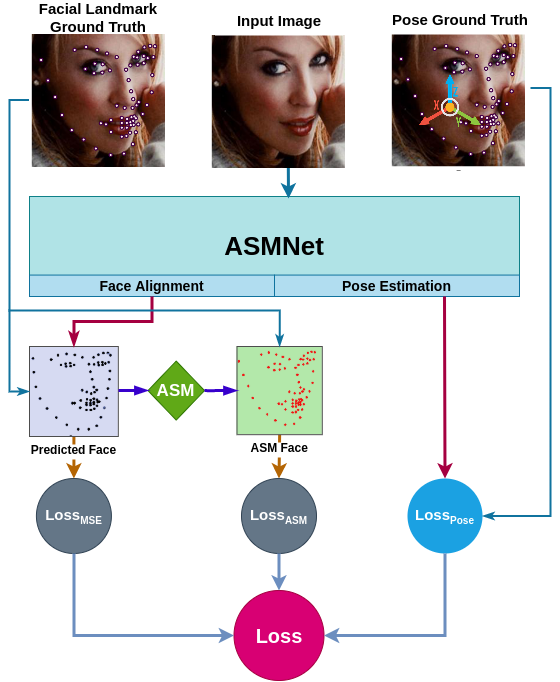
ASM辅助损失
我们描述了两个不同任务的损失函数。这些任务负责人脸标志点检测和姿态估计。
人脸标志点检测任务:人脸标志点检测常用的损失函数是均方误差(MSE)。提出了一种新的损失函数,将MSE作为主要损失,同时引入辅助损失,利用ASM来提高网络的精度,称为ASM-Loss。
提出的ASM-Loss引导网络首先学习面部标志点的平滑分布。换言之,在训练过程中,损失函数将预测的面部标志点与其对应的地面真实以及使用ASM生成的平滑版本的地面真实进行比较。有鉴于此,在培训的早期阶段,我们设置了更大的权重ASM-损失相比主要损失-欧元“这是MSEâuro”,因为平滑的面部标志点的变化比原来的标志点要低得多,作为一个经验法则,更容易被一个CNN学习。然后,通过逐步降低ASM丢失量的权重,使网络更多地集中在原有的标志点上。在实践中,我们发现这种方法,也可以看作是迁移学习,效果很好,模型更加准确。
我们还发现,虽然人脸姿态估计在很大程度上依赖于人脸对齐,但它也可以在平滑的人脸标志点的辅助下达到很好的精度。换言之,如果人脸标志点检测任务的性能是可以接受的,这意味着网络可以预测人脸的地标点,使得人脸的整体形状是正确的,姿态估计可以达到很好的精度。因此,使用平滑的地标点和使用ASM-Loss来训练网络将会提高位姿估计任务的精度。
考虑对于训练集中的每个图像,在称为G的集合中存在n个地标点,使得(Gx1,Gyi)是第i个地标点的坐标。类似地,预测集合P包含n个点,使得(Pxi,Py i)是第i个地标点的预测坐标。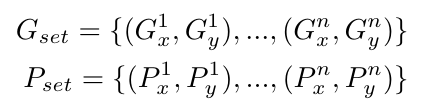
我们将PCA应用于训练集,并计算特征向量和特征值。然后根据方程应用ASM算子计算集合A,集合A包含n个点,每个点都是G中对应点的变换。4:
我们定义了主要的面部标志点损失,方程。7,作为地面真实值(G)与预测地标点(P)之间的均方误差。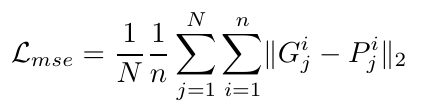
其中N是训练集中的图像总数,并且gij=(gix,giy)表示训练集中第j个样本的第i个地标。我们将ASM损失计算为ASM点(ASET)与预测地标点(PSET)之间的误差,使用公式。8: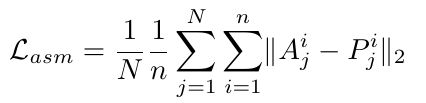
最后,根据公式计算出人脸标志性任务的总损失。9: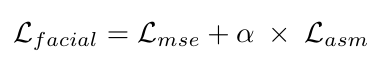
PCA的精度很大程度上依赖于ASM点(ASET),也就是说PCA越精确,地面真实值(G)与ASM点(ASET)之间的偏差就越小。更详细地说,通过降低PCA的精确度,生成的ASM点(Aset)将更接近于平均点集,平均点集是训练集中所有地面真实面对象的平均值。因此,Aset中的预测点比Gset中的点更容易预测,因为后者的变化量比前者的变化量小。我们使用这个特征来设计我们的损失函数,这样我们首先引导网络学习平滑的地标点的分布(更容易学习),并通过降低ASM-LOSS的权重来逐渐强化问题。我们使用等式将∑定义为ASM-损失权重。10: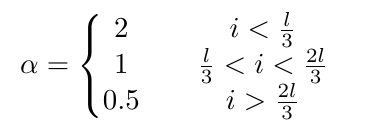
其中i是历元编号,l是训练历元的总数。如等式所示。9、训练开始时,I±值较高,说明我们更重视ASM损失。因此,网络更注重预测更简单的任务,收敛速度更快。然后在总历元的1/3之后,我们将±减为1,并同等重视主要的MSE损失ASM-损失。最后,在总历元的2/3之后,通过将Σ±减小到0.5,我们将网络引导到预测主要地面事实,同时考虑使用ASM生成的平滑点作为辅助。
位姿估计任务:我们使用均方误差来计算头部位姿估计任务的损失。情商。11定义损失函数Lpose,其中偏航(Yp)、俯仰(Pp)和侧滚(Rp)是预测姿势,yt、pt和rt是相应的地面真值。
实施详情
代码可以在这里的Github上找到。关于代码的所有文档也都可用。
安装要求
为了运行代码,您需要安装Python>=3.5。可以使用以下命令安装运行代码所需的要求和库:
pip install -r requirements.txt使用预先训练的模型
您可以使用以下代码测试和使用预培训的模型,这些代码位于以下文件中:https://github.com/aliprf/ASMNet/blob/master/main.pyhttps://github.com/aliprf/ASMNet/blob/master/main.py
tester = Test()
tester.test_model(ds_name=DatasetName.w300,
pretrained_model_path='./pre_trained_models/ASMNet/ASM_loss/ASMNet_300W_ASMLoss.h5')培训网络从无到有
准备数据
数据需要标准化,并以NPY格式保存。
PCA创建
您可以使用pca_utility.py类创建特征值、特征向量和均值向量:
pca_calc = PCAUtility()
pca_calc.create_pca_from_npy(dataset_name=DatasetName.w300,
labels_npy_path='./data/w300/normalized_labels/',
pca_percentages=90)培训
培训实现位于Train.py类中。您可以使用以下代码开始培训:
trainer = Train(arch=ModelArch.ASMNet,
dataset_name=DatasetName.w300,
save_path='./',
asm_accuracy=90)结果
下图显示了使用ASMNet进行人脸对齐和姿势估计的一些示例:
请将这项工作引用为:
@inproceedings{fard2021asmnet,
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation},
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1521--1530},
year={2021}
}参考文献
[1]A.Asthan,S.Zafeiriou,S.Cheng和M.Pantic。基于约束局部模型的稳健判别响应图拟合。见IEEE计算机视觉和模式识别会议论文集,第3444âuro“3451页,2013。
[2]D.Cristinacce和T.F.Cootes。基于约束局部模型的特征检测与跟踪。收录于Bmvc,第1卷,第3页,Citeseer,2006。
[3]T.F.库特斯,G.J.爱德华兹和C.J.泰勒。活动外观模型。在欧洲计算机视觉会议上,第484-EURO“498页。斯普林格,1998年。
[4]P.Martins,R.Caseiro和J.Batista。通过2.5d的主动外观模型生成人脸对齐。计算机视觉与图像理解,117(3):250âuro“268,2013。
[5]X.朱和D.Ramanan。野外人脸检测、姿态估计和地标定位。2012年IEEE计算机视觉和模式识别会议,2879âuro“2886页,2012年6月。
[6]张军,单世山,简明,陈X.用于实时人脸对齐的从粗到精的自动编码器网络(Cfan)。“欧洲计算机视觉会议,第1页”16,斯普林格,2014年。
[7]张振章,罗平平,C.C.Loy,唐晓华.基于深度多任务学习的人脸标志点检测。“欧洲计算机视觉会议”,第94页“108”。斯普林格,2014年。
[8]C.Sager as、G.Tzimiropoulos、S.Zafeiriou和M.Pantic.300面临野外挑战:第一个具有里程碑意义的面部本地化挑战。见IEEE国际计算机视觉研讨会会议论文集,第397âuro页,403页,2013年。
[9][9]吴文武,钱春春,杨山,王强,蔡玉英,周启.看看边界:一种边界感知的人脸对齐算法。见IEEE计算机视觉和模式识别会议论文集,第2129âuro页“2138,2018年。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/09/asmnet%ef%bc%9a%e4%b8%80%e7%a7%8d%e7%94%a8%e4%ba%8e%e4%ba%ba%e8%84%b8%e5%af%b9%e9%bd%90%e5%92%8c%e5%a7%bf%e6%80%81%e4%bc%b0%e8%ae%a1%e7%9a%84%e8%bd%bb%e9%87%8f%e7%ba%a7%e6%b7%b1%e5%ba%a6%e7%a5%9e/
