

自2017年末首次推出以来,《变形金刚》迅速成为自然语言处理(NLP)领域最先进的架构。最近,研究人员开始将潜在的想法应用到计算机视觉领域,结果表明,由此产生的视觉变形金刚在速度和准确性方面都优于基于CNN的前身。在这篇博文中,我们将更深入地了解如何将变压器应用于计算机视觉任务,以及对图像进行标记化意味着什么。first introduction
基金会:一些重要的关键字
我们首先回顾一下Transformer的基本构建块。如果您已经熟悉该体系结构,请随意跳到下一节。
编码器/解码器
与许多其他成功的深度学习模型一样,Transformer由编码器和解码器部分组成。其总体思想是对输入向量的某些特征进行编码,然后将这些特征映射到某些输出,并解码其中的相关信息。通过跳过连接来连接不同的层,得到的模型在每一层都有更多可用的信息,并且还可以防止渐变消失的问题。在变压器中,编码器和解码器由许多相同的块组成,这些块主要依赖于注意机制。我们将在这里介绍的示例,如著名的BERT模型,仅使用编码器部分。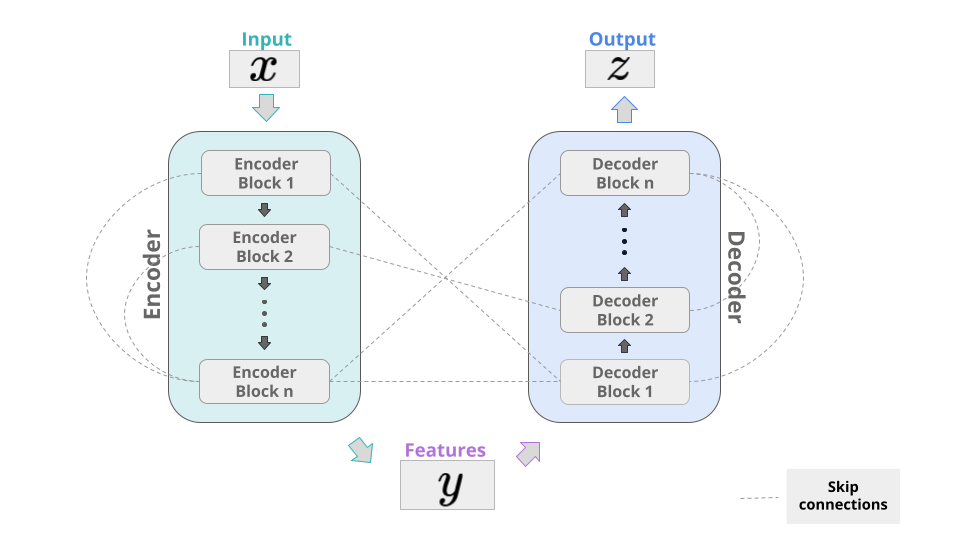
注意事项
自我注意机制是“变形金刚”成功的核心。它允许模型了解输入的哪些部分是重要的,以及输入的每个部分与其他部分的相关性如何。从概念上讲,自我关注层通过合并关于每个条目的整个序列的全局信息来更新输入序列。它之所以如此高效,是因为它不是以顺序的方式完成这项工作,而是一次完成所有工作。因此,与LSTM网络一样,转换器可以自然地对远程依赖项进行建模。然而,与它们相反的是,它适合并行化,从而允许高效的实现。要解释注意力机制是如何计算的,请查看这篇优秀的博客文章,我们关于神经语言模型的网络研讨会或已经提到的论文注意力就够了。excellent blog article webinar on neural language models Attention is all you need
令牌/嵌入
NLP中基于变压器的模型(如BERT)具有固定的词汇表。这个词汇表的每个元素都称为一个记号。此词汇表的大小可能因型号而异。对于BERT-BASE-UNCESS,它由30,522个令牌组成。请注意,在下面的代码示例中,一些单词是如何被标记器拆分的。对于不同的模型,输入可能会以不同的方式进行标记化。在这段代码中,我们从Great Huggingface Transers库中导入了一个Bert模型。BERT-base-uncased huggingface transformers
通过在模型训练期间学习的嵌入层将这些标记映射到高维向量空间中的向量(768或1024是嵌入维度的常见选择)。当通过随后的编码块传播时,结果矢量表示通过注意机制或其变体(如多头注意)和建立上下文来更新。
对于已经带有数字表示的图像,嵌入层就会过时,而且也不需要担心固定的词汇表大小。然而,如何将通常表示为矩阵的图像转换为向量序列仍有很多含糊之处。我们现在要看几种不同的方法来实现这一点。
从句子到图像
在我们了解图像标记化的过程之前,让我们先从卷积神经网络(CNN)的简短离题开始。
像素卷积范例
计算机视觉中一种常见且到目前为止仍然非常成功的技术是将卷积图层应用于图像并创建所谓的特征地图。著名的型号,如ResNet和它的后继者都遵循这种方法。通常,可以按以下方式重复此过程:假设输入是ℝ^{512×512×3}格式的图像,即大小为512×512的图像,具有3个颜色通道。在第一步中,可以应用8(3×3)卷积核,以便输出为ℝ^{512×512×8}(特征映射的确切大小可能相差几个像素,这取决于我们是否决定填充图像的边缘)。在第二步中,可以应用16(3×3)核,并使用降维技术(如池化),因此输出将成为ℝ^{256×256×16}的一个元素。普遍的共识是,随着网络深度的增加,应该添加越来越多尺寸越来越小的特征地图。ResNet
通常的观点是,网络中更深的特征映射表示更高级别的特征,如某些特定对象的形状,而更靠近输入的特征映射表示低级别特征,如边缘。虽然已经证明这种深度完全卷积神经网络的方法是非常成功的,但是它有三个主要的缺点:
要克服这一点,注意力机制就会介入。让我们看看几种不同的方法如何做到这一点。
通过打补丁实现标记化
一种相当幼稚的构建令牌的方法是简单地将图像分成更小的块,将它们平整成矢量,然后瞧-这就是您的令牌。视觉转换器(Vision Transformer,VIT)就是这样做的-在扁平化之后进行额外的转换以降低标记的维度,并进行位置编码,这对于变形金刚来说是很常见的。这个想法最酷的地方在于,它根本不依赖于不同的架构(特别是CNN)。所以,再一次,你需要的只是关注。具体地说,该过程的工作方式如下:假设我们有一幅具有3个颜色通道的512×512图像。对于16×16的固定面片大小,这将导致N=1024个面片。现在,每个面片仍然是ℝ^{16×16×3}中的一个矩阵(甚至实际上是秩3张量),但是我们可以简单地将所有条目堆叠成长度为16²⋅3=768时的向量(碰巧这也是原始BERT模型中嵌入的令牌的大小)。作者现在应用(可学习的)线性变换来降低结果向量序列的维数并获得记号,然而这是可选的。Vision Transformer (ViT)
VIT的创建者将其用于分类,其中仅使用编码器部分,并且与在BERT模型中一样,添加了分类令牌。在输出层中,分类基于此令牌进行。进一步的应用包括通过解码器馈送输出以执行回归任务或分段。值得注意的是,VIT根本不使用卷积,在具有挑战性的数据集上仍然表现良好。然而,这种良好的性能是有代价的:需要非常非常大量的数据(以及时间和资源),这在基于Transformer的体系结构中是很常见的。VIT在JFT数据集上接受了图像分类培训,该数据集由超过3亿张图像组成,然后在ImageNet上对其130万张图像进行了“微调”。有关其在CV基准上的性能的详细讨论,请务必阅读该白皮书。paper
您还可以在变压器库中找到现成的、经过培训的VIT。pretrained ViT
由于只依赖变压器和注意力只有在处理令人难以置信的大型数据集时才有可能,让我们来看看如何将这种方法与卷积相结合,以便从两个世界获得最好的结果。
从要素地图生成令牌
视觉变换器(VT)就是这样一种架构,它不应该与视觉变换器(VIT)混淆!它通过以下方式创建令牌:Visual Transformer (VT)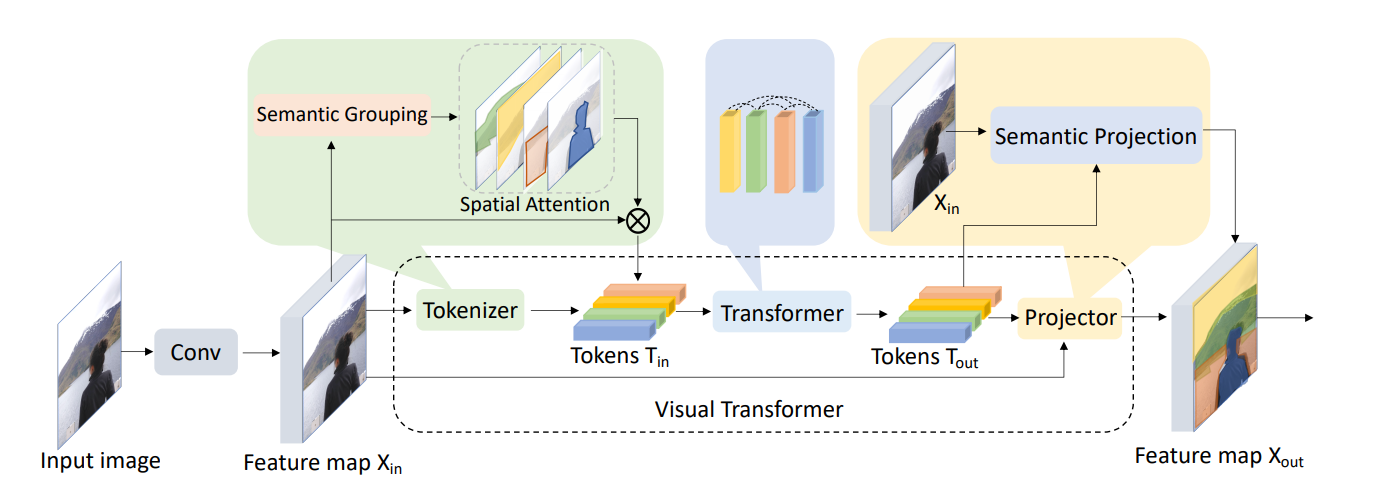
首先,应用卷积层从输入图像中提取一些低层特征。接下来,将记号器应用于特征地图以将像素分组为视觉记号。这些令牌通过常规转换器对令牌之间的关系进行建模。然后,可以直接使用它们更新后的表示进行分类,或者将它们投影回特征映射以执行语义分割。对我来说,最有趣的部分是记号器是如何工作的,所以让我们更详细地了解一下。
该过程由几个步骤组成。给定ℝ^{H×W}(高度H,宽度W)中的一组C特征映射,首先将它们展平并排列成2D矩阵X∈ℝ^{HW×C}。现在,一个可学习矩阵W_A∈ℝ^{C×L}从右到X相乘,形成L个语义组。应用(行式)Softmax运算,这产生矩阵,该矩阵在每行(即,原始特征地图的像素)中的L个语义组上承载概率分布。通过现在将该矩阵的转置从左乘到X,对于结果矩阵T中的L行中的每一行,每个条目都是原始特征映射中所有像素的加权平均,其中像素用它们属于语义组l∈L的概率加权。这如下图所示:
所以,正式地说: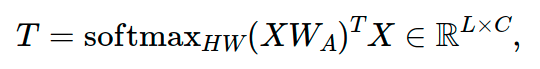
其中,作者认为可以选择比HW小得多的L,这降低了模型的复杂性。这个标记化的过程也被称为计算空间注意力。通过将标记投影回它们在图像中的位置,可以可视化语义组是什么样子。请注意,不同的标记如何在图像中突出不同的语义概念(红值较高,蓝值较低)。
在目前的实验中,作者调查了令牌数量(L)对其模型性能的影响。他们查看了L=16、32和64,相当令人惊讶的是,使用更多的令牌时,性能仅略有提高。当使用ResNet-34骨干网创建特征地图时,L=16的ImageNet上的Top1精度甚至高于较大值。因此,一个图像确实可以用少量的视觉符号来表示,至少看起来是这样。
VT在计算机视觉的各种基准测试中取得了很好的结果,尽管参数较少,但几乎总是优于卷积同行。与Vision Transformer相比,它只需要很少的时间和数据来训练(它只在ImageNet上训练,它仍然有100多万幅图像)。
有关性能的更详细评估,请务必查看论文。paper
结论
要结束这篇文章,让我们回顾一下要点:
- 变形金刚最初是用来处理NLP任务的。
- 很长一段时间(直到今天),计算机视觉的标准工具是卷积。然而,它们也有自己的问题,比如关联空间距离像素的问题,以及使一些任务“过于复杂”的问题。
- 与卷积一起使用,甚至不使用卷积,变压器都可以成功地应用于计算机视觉。当完全放弃卷积时,需要大量的数据和计算资源。
- 我们看了两个具体的例子,以及对图像进行标记化可能意味着什么。
- 如果您想要在总体上试验变压器,HuggingFace变形器库是一个很好的起点。TIMM(火炬图像模型)包还为计算机视觉任务提供了转换器的实现。
当然,我们只是触及了变形金刚在这一领域的应用的皮毛。如果您想了解更多,请查看计算机视觉中关于变压器的这项调查。survey on transformers in Computer Vision
最初发表于https://dida.do.https://dida.do
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/11/%e8%a7%86%e8%a7%89%e5%8f%98%e5%bd%a2%e9%87%91%e5%88%9a%ef%bc%9a%e4%b8%banlp%e8%ae%be%e8%ae%a1%e7%9a%84%e6%9e%b6%e6%9e%84%e5%a6%82%e4%bd%95%e8%bf%9b%e5%85%a5%e8%ae%a1%e7%ae%97%e6%9c%ba%e8%a7%86-2/
