
在申请专利之前,确保你没有侵犯别人的知识产权(IP)是必不可少的一步。出于这个原因,发明家和专利律师花费了相当多的时间来分析类似的专利–这些时间本来可以花在研究上。
化学专利和其他专利一样,包含大量信息:文本和非文本。为了快速分析数据,提取信息并以编程方式分析它们变得越来越流行,例如,使用OCR提取文本和查找关键字。但是使用OCR将提取的信息限制为文本数据。其他重要的细节,如化学结构、反应图片等,不能用这种方式提取。
目标检测等基于深度学习的方法解决了这一问题。许多最先进的(SOTA)对象检测模型有助于快速检测化学结构和反应等非文本信息。可以进一步裁剪检测并将其用于其他任务。
YOLOv5就是这样一个模型。YOLOv5
YOLO概述
YOLO(你只看一次)是一类目标检测模型,它通过只“看”一次图像来运行推理,即只有一次前向传播。这种方法节省了大量时间,使YOLO成为目前最快的目标检测算法之一。在需要一次分析100甚至1000个页面的用例中,YOLO的快速推理使其成为首选。
此外,YOLO学习广义表示,因此如果训练数据只包含专利文档,它仍然可以在其他场景中检测化合物。
YOLOv5是目前可用的最快、最准确的开源模型之一。与其他YOLO机型不同,YOLOv5在PyTorch中完全实现,使用起来非常简单。
YOLOv5性能比较: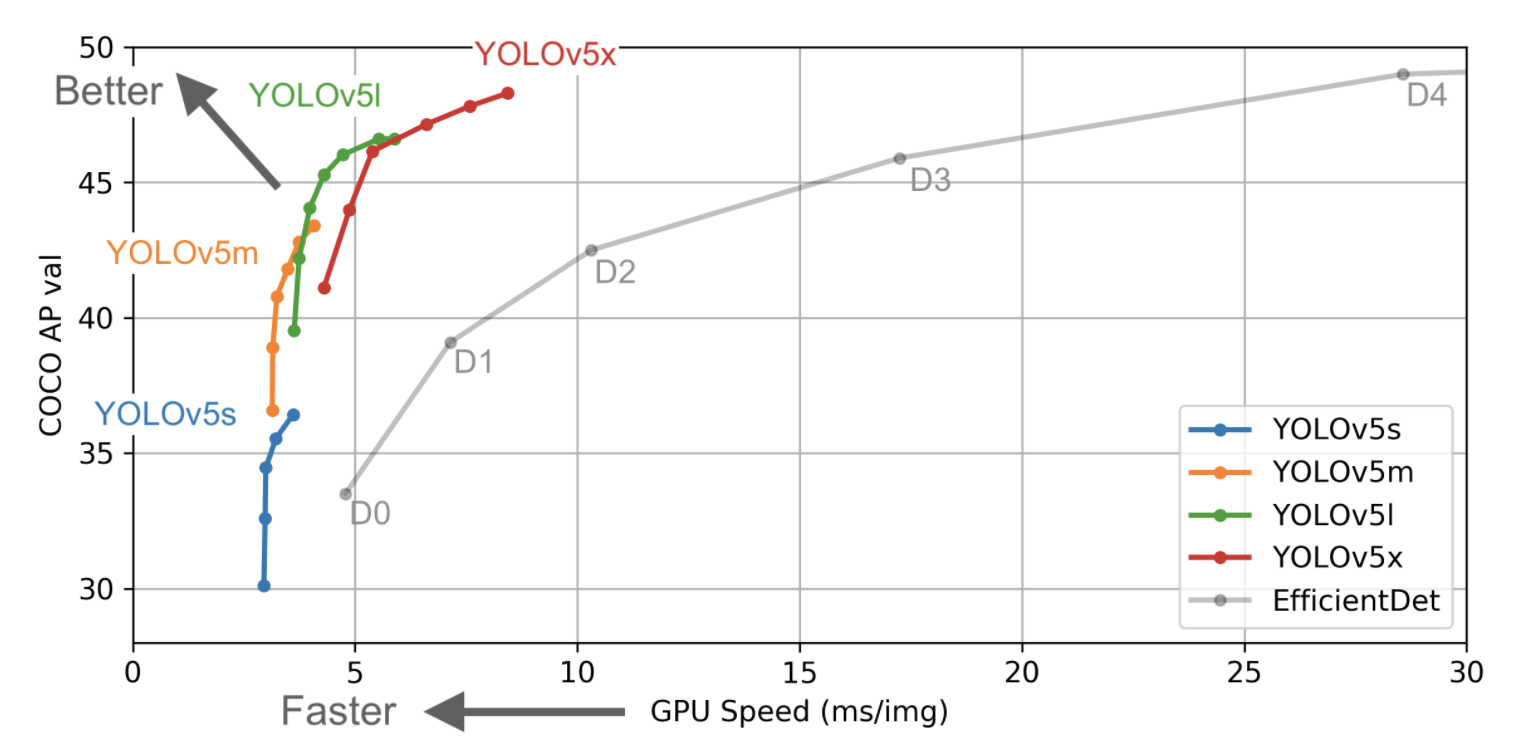
迁移学习
迁移学习,简而言之,就是使用一个真正擅长某一特定任务的预先训练的模型,并将知识转移到另一项任务中,同时提高绩效和减少训练时间的过程。
知识可以通过“冻结”前几层的权重并只更新其余层的权重来传递。在我们的例子中,YOLOv5有24层,所以我们冻结了40%的顶层(模型的主干)并开始训练。freezing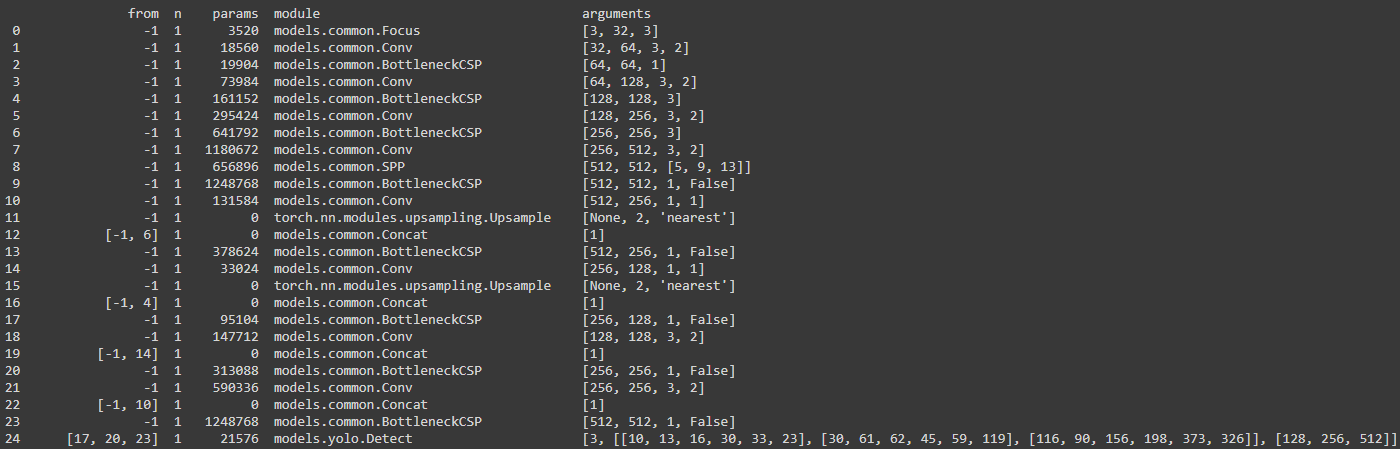
超参数调整
为了最大限度地利用可用的训练数据,拥有最优的超参数至关重要。最优的参数不仅能提供最准确的结果,而且还能在最短的时间内完成,从而使用最少的计算资源。
我们运行了300代遗传算法来寻找最优参数,同时对模型进行了30个历元的训练。这极大地提高了模型性能,尽管只有71幅图像可供处理,但却给出了非常准确的结果。研究结果总结如下。genetic algorithm
结果
我们开发了一款网络应用程序,可以让你上传pdf并输出检测到的化合物。该应用程序裁剪这些检测,并将它们存储在每个类的单独目录中。然后可以通过单击生成的链接下载这些结果。所有这些都是以惊人的低推理时间完成的。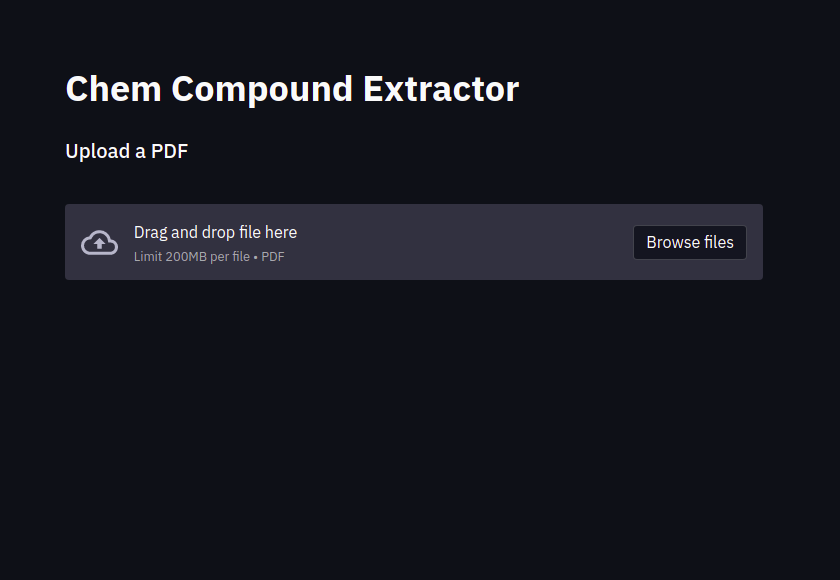
与谷歌专利的比较
我们查找了几个关于谷歌专利的化学专利文件,并记录了谷歌专利提取的化学结构的数量。然后,我们下载了相同的文档,并将它们上传到我们的Web应用程序,以比较结果。
示例1:文件File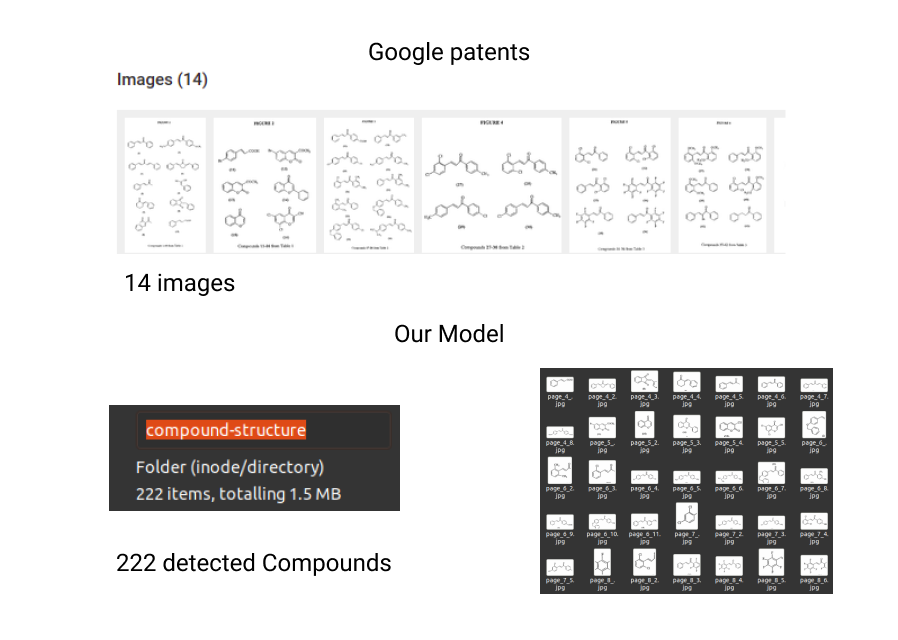
示例2:文件File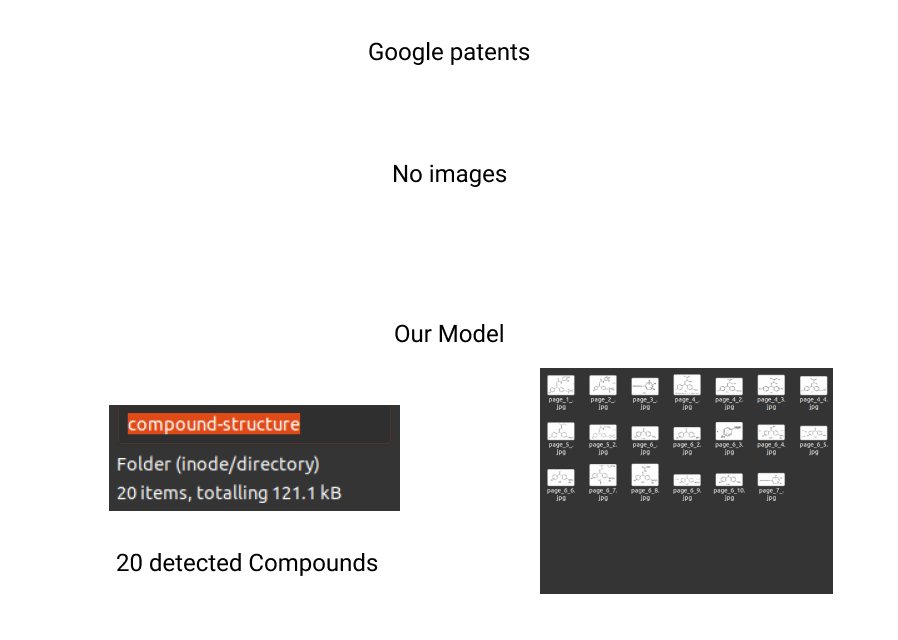
示例3:文件File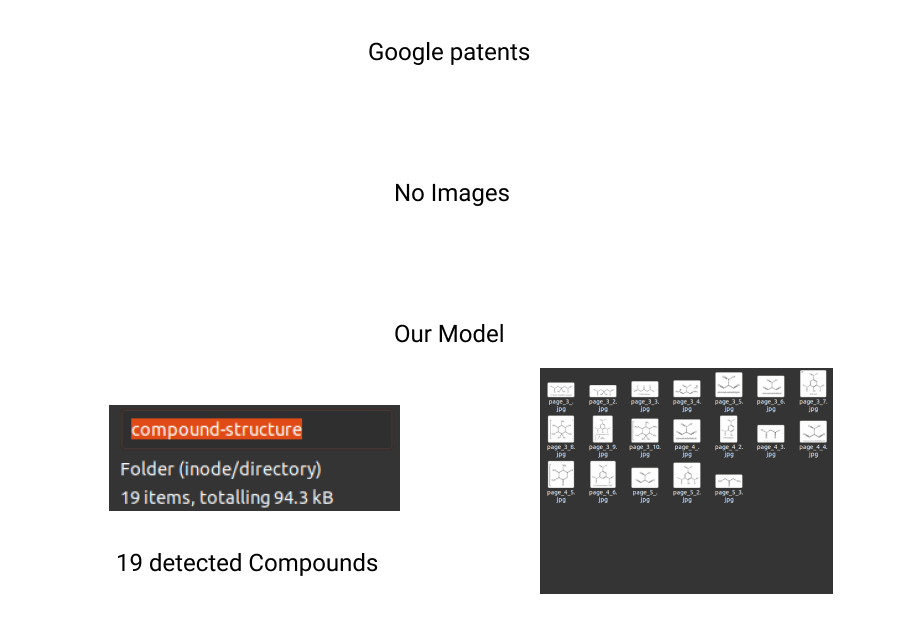
由于谷歌的专利依赖于提取PDF中的图像元素来检测化合物,它无法提取文档中存在的所有化合物结构。
今后的工作
继续提高模型精度。
区分化合物、马库什结构和中间体。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/11/%e8%b6%85%e8%b6%8a%e7%ae%80%e5%8d%95ocr%e7%9a%84%e5%8c%96%e5%ad%a6%e4%b8%93%e5%88%a9%e5%88%86%e6%9e%90-2/
