
目标检测是对图像中的目标进行分类和定位。换句话说,它是图像分类和对象定位的结合。构建用于图像分类的机器学习模型更简单,我在这里的一篇帖子中描述了这一点。然而,图像分类器不能说出对象在图像内的确切位置。为了实现这一点,我们需要建立一个神经网络,它除了对图像中的对象进行分类外,还可以定位图像中的对象。在这篇文章中,我将描述我如何通过解决这两个问题来构建一个用于目标检测的神经网络。here
要检测的对象
由于我的目的是在不花费太多时间准备数据的情况下从头开始构建模型,因此我选择了我能想到的最简单的对象。我的选择是用一块硬纸板做一个简单的红色视觉标记。由于视觉标记只是一个2D形状,可以捕获它的不同角度是有限的-因此训练集所需的图像数量也是有限的。我把视觉标记做成圆形和手掌大小,以便于操作。
模型的体系结构
在深入到实现细节之前,我想向您描述模型的体系结构。首先,我的目标是推断出两个答案:
- 无论图像中是否包含对象
- 物体的确切位置在哪里?
要解决第一个问题,我可以使用图像分类器-具有两个输出神经元的卷积神经网络。其中一个输出神经元可以代表物体的存在,而另一个神经元可以代表物体的不存在。换言之,图像分类器的输出是不同对象类之间的概率分布-或者在这种情况下,对象的存在(“圆形”)或不存在(“非圆形”)。然后,可以通过在输出层应用SoftMax函数来确定具有最高概率的类别。
解决第二个问题是完全不同的。我想要的是通过在物体周围画一个边界框来定位它。为此,我必须找到边界框左上角和右下角的像素坐标。这意味着我的神经网络必须计算出图像中那两个点的x,y坐标。我可以通过设计一个在输出层有4个神经元的卷积神经网络来做到这一点-代表4个数值坐标值。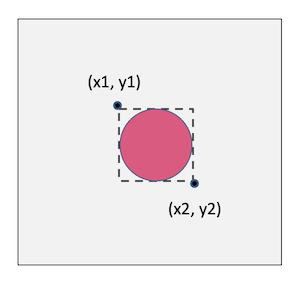
然后,挑战是使用单一的神经网络来实现这两个目标。一方面,解决方案的图像分类器部分将输出神经元的值视为概率分布。然后,它选择概率最高的一个,并将其标签作为答案。另一方面,解决方案的对象定位部分需要4个输出神经元给出实际的边界框坐标。因此,神经网络很难训练其完全连接的致密层来同时满足这两个要求。因为,优化分类的权重和偏差将危及本地化的输出,反之亦然。
这个问题的解决方案是设计一个具有两个分支输出的神经网络。由于两个问题的特征提取必须同等执行,所以我使卷积层成为公共的和可共享的。然而,在卷积层之后,我将网络分成两个-每个网络都有自己的致密层和输出层,以实现两个不同的结果。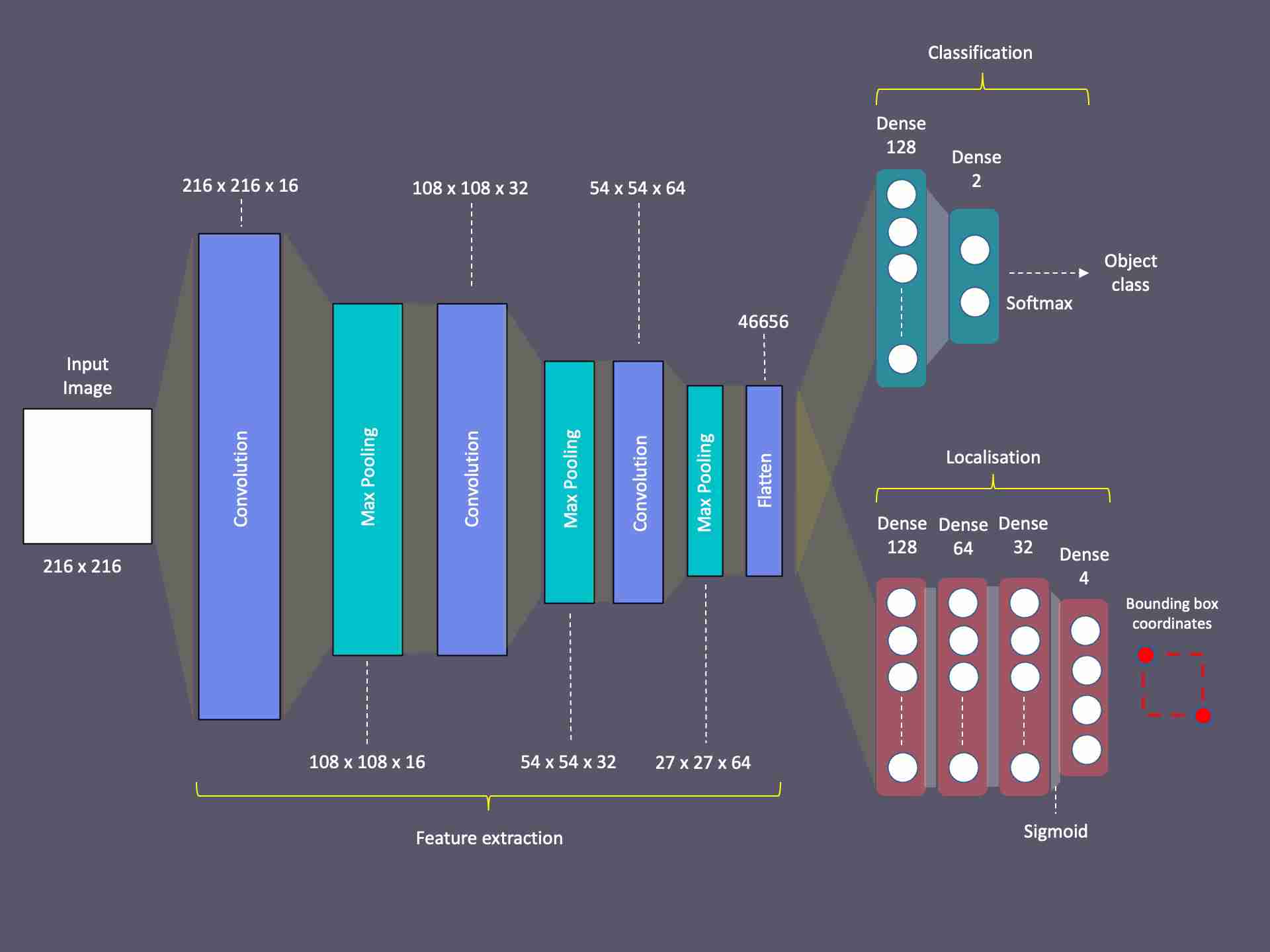
这个架构使我能够训练这两个具有不同损失功能和激活功能的主管或分支机构。此外,这使得我可以使用不同的数据集分别对它们进行培训。我将在这篇文章的后面描述我是如何做到这一点的,以及为什么这样做是重要的。
数据准备
与任何其他机器学习项目一样,数据准备也是这里的关键。首先,我将相机配置为通过将图像分辨率设置为2160×2160来捕捉正方形图像。然后,我拍摄了大约126张视觉标记的照片,将其放置在图像框内的不同位置,并将其放置在距相机不同的距离处。而且,我用不同的背景拍了这些照片。训练数据集中的这些变化帮助模型最终实现了更准确的预测。
我又拍了62张没有视觉标记的照片。这样做是为了训练模型以识别标记的缺失。然后,我将所有照片的分辨率调整为216×216像素,因为没有必要使用更高分辨率的图像来识别如此简单的对象。
图像标注
下一步是使用边界框注释视觉标记。与图像分类器不同,这是构建对象定位器的重要一步。为此,我使用了免费的开源批注工具vott。
首先,我在VOTT中创建了一个名为“视觉标记检测器”的项目,并为源图像和生成的注释创建了源连接和目标连接,分别指向计算机中的文件夹位置。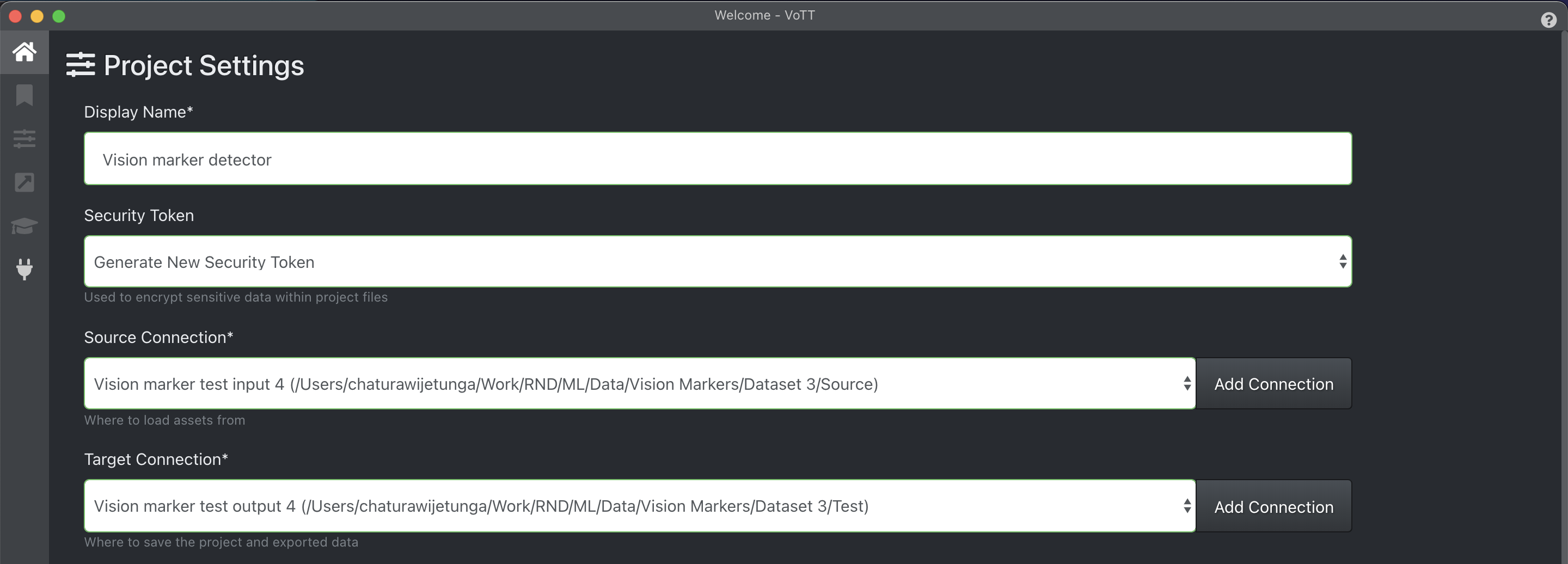
此外,我创建了一个名为“Circle”的标记(标签)来注释图像中的视觉标记。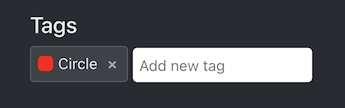
然后,就到了为图像添加注释这一不太有趣的任务的时候了!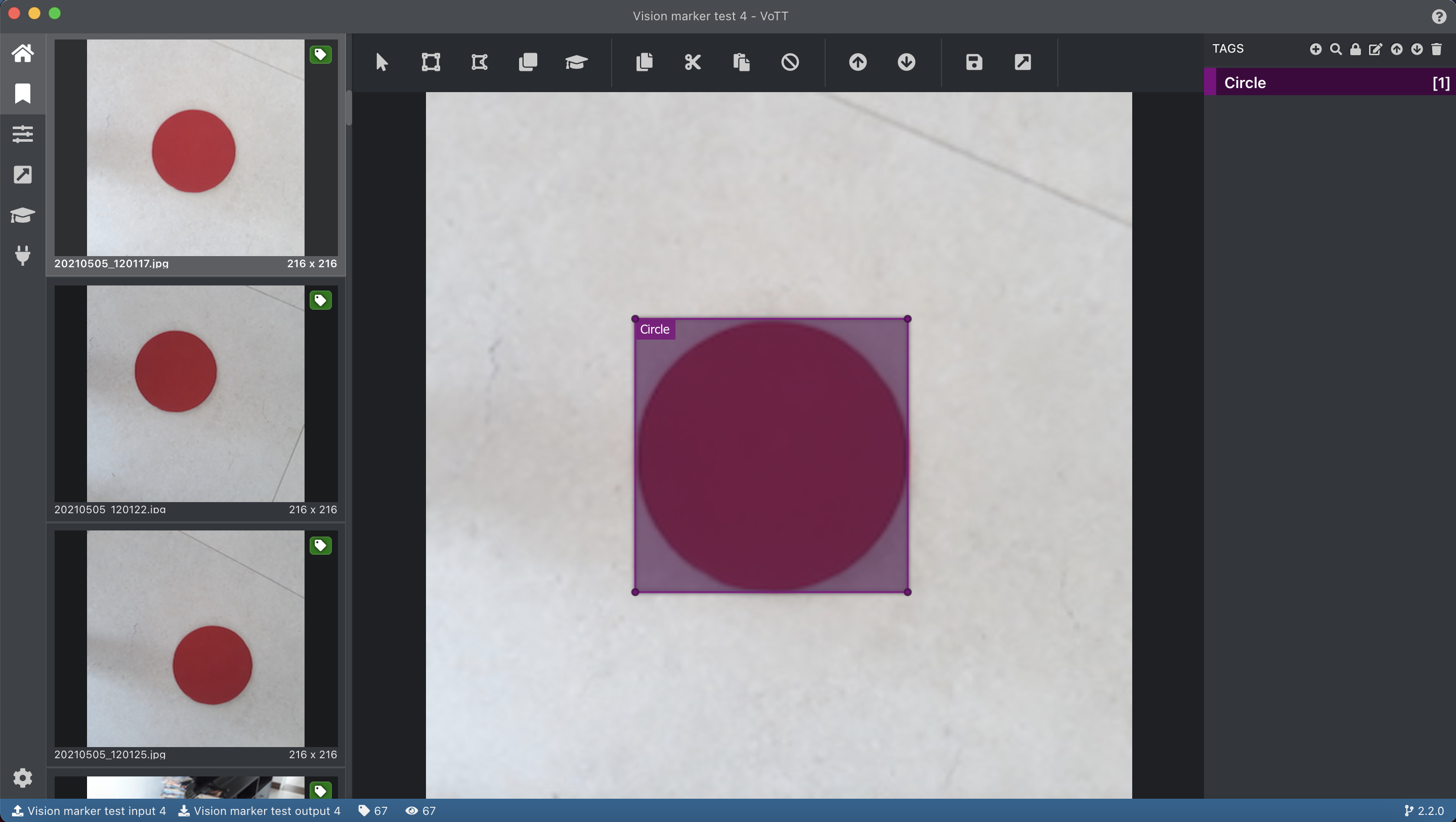
没有视觉标记拍摄的照片在这里被跳过了。在这篇文章的后面,我将描述我是如何将这些图片用于培训的。但是,我确保将导出设置中的以下设置也设置为为未分配(未标记)的图像生成注释XML文件。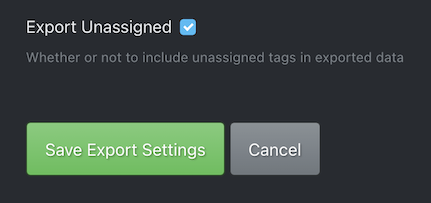
在冗长的图像注释任务之后,我使用vott中的导出选项将所有注释导出为Pascal VOC格式。
组织文件夹结构
我将图像和相应的注释XML文件分成两个集合-一个表示训练集,另一个表示验证集。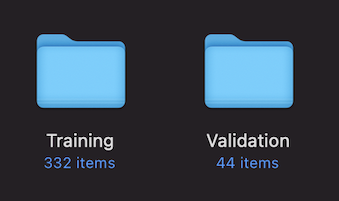
然后我将它们移到项目文件夹结构中名为“Images”的父文件夹中。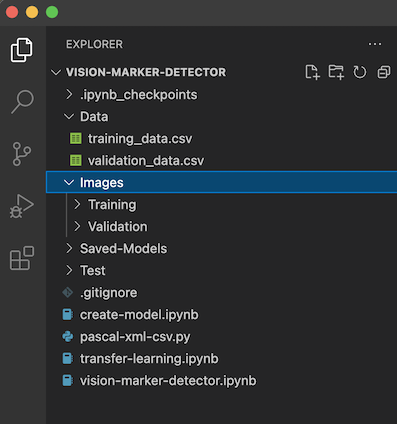
创建数据集
除了图像及其标签之外,在准备用于训练对象检测器的数据集的过程中使用边界框坐标是很重要的。为此,我使用了一个python脚本,该脚本读取vott生成的所有XML文件,并为训练和验证数据集生成两个CSV文件。我编写这个脚本的方式是,我可以在配置变量-SKIP_NECTIVE设置为True或False的情况下运行它,以排除或包括负片图像(其中没有对象的图像)。
然后,我编写了以下代码,通过读取上述步骤生成的Training_data.csv文件来创建训练数据集。这里我创建了3个列表-第一个列表用于图像数据数组列表,第二个列表和第三个列表分别用于相应的边界框坐标和图像标签。
我也使用相同的代码加载验证数据集。然后,我使用以下代码将列表转换为Numpy数组。
train_images = np.array(train_images)
train_targets = np.array(train_targets)
train_labels = np.array(train_labels)训练模型时,使用Train_Image数组作为Kera API中Model类Fit方法的输入数据参数(或参数x)。然后,在字典中将数组-Train_Targets和Train_Label一起用作FIT方法的目标参数(或参数y)。稍后您将在本文中注意到这一点。
构建模型
然后就是构建模型的时候了!
首先,我将必要的依赖项导入到脚本中。
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf我以变量的形式创建了一些配置参数,并定义了用于模型的类数组。
width = 216
height = 216
num_classes = 2然后我编写了定义模型的代码。首先定义输入层,然后定义重定标层,将像素数据转换到0-1的数值范围内,然后创建卷积层,将一层的输出链接到另一层的输入。我用前缀“bl_”命名了所有这些卷积层,目的是稍后使用这个前缀抓取它们。
其次,按照前面讨论的体系结构,我通过输入来自卷积层的扁平输出来定义分类分支层。这里我只添加了两个致密层-一个有128个神经元,最后一个只有2个神经元,与我们要预测的两个类别标签相对应。此外,我还为分类分支的各层指定了前缀“cl_”。
第三,我再次定义了局部化分支层,输入来自卷积层的平面化输出。在这里,我添加了4个独立的致密层,神经元数量减少,最后一层有4个神经元,对应于用于预测的4个边界框坐标值。此分支中的图层使用前缀“BB_”命名。
最后,可以通过传递输入层和两个输出分支来创建模型类。这就是我们将两个输出分支焊接到基本模型中的地方。
model = tf.keras.Model(input_layer,
outputs=[classifier_branch,locator_branch])该模型的摘要如下所示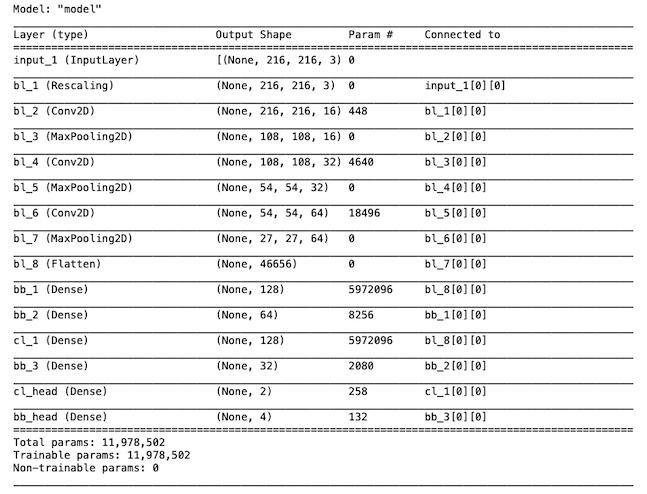
编译模型
由于两个输出分支的设计目的是实现两个不同的结果(一个是输出概率分布,另一个是预测实际的边界框值),因此有必要为每个分支设置适当的损失函数。我对分类头使用稀疏的分类交叉损失函数,对定位头使用均方误差(MSE)。我通过定义下面的字典实现了这一点。
然后,我将其与ADAM优化方法一起使用,并编译了模型。
model.compile(loss=losses, optimizer='Adam', metrics=['accuracy'])本地化-包围盒回归模型的训练
正如我在模型体系结构一节中所描述的,我的计划是首先训练模型进行对象本地化。在这部分训练期间,模型的本地化分支将执行边界框回归,然后将调整其权重和偏差,以优化边界框预测。
这里重要的是,我只使用了带注释的图像(只使用带有视觉标记的图像)来训练模型的本地化部分。在运行数据集生成代码之前,我运行CSV生成脚本,并将SKIP_NECTIONS参数设置为True,如上数据集创建一节中所述,从而实现了这一点。
在训练定位分支时跳过负图像(没有视觉标记的图像)的原因是,否则它会影响边界框预测的准确性。因为我们必须设置虚拟边界框坐标值-例如,如果我们在训练数据集中也使用负片图像,则它们是(0,0)(0,0)。例如,如果我们在培训集中同时使用正面和负面图像进行培训,则下图显示了本地化分支的培训绩效情况。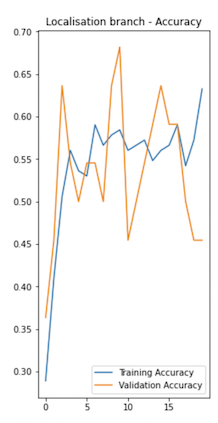
然而,仅使用正面图像来训练本地化分支的缺点是,它会给负面图像带来错误的肯定。但是,因为我不打算依赖本地化分支来确定视觉标记的存在或不存在,所以这对我来说不是问题。
我使用了以下代码,它为两个命名分支cl_head和bb_head的训练和验证目标定义了两个字典对象。在这里,您将注意到标签数组用于分类分支,边界框坐标数组用于本地化分支。
trainTargets = {
"cl_head": train_labels,
"bb_head": train_targets
}我最初将纪元数设置为20,将Batch_Size设置为4。然后,我运行以下代码来训练模型。
history = model.fit(train_images, trainTargets,
validation_data=(validation_images, validationTargets),
batch_size=4,
epochs=training_epochs,
shuffle=True,
verbose=1)以下图表显示了这两个分支机构的培训绩效。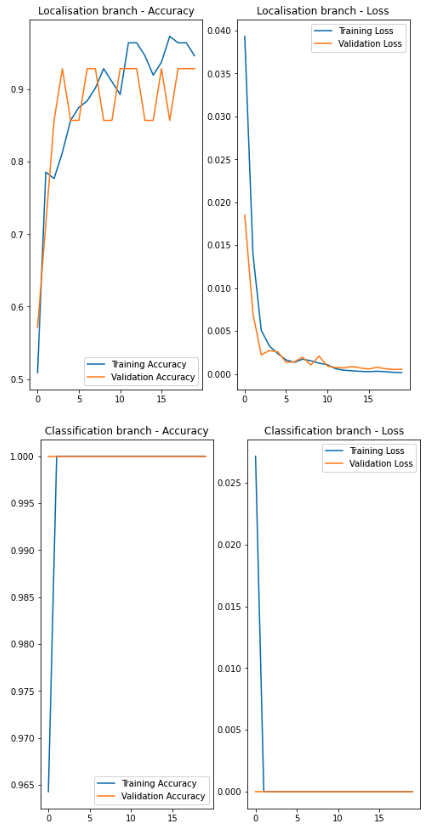
在上面的图表中,您会注意到本地化分支的表现相当不错。然而,分类分支实现的准确率太好了,以至于令人难以置信。它的表现是不可信赖的,因为到目前为止还没有看到任何负面的形象。这意味着模型(它的分类部分)总是将它看到的东西归类为“视觉标记”,因为它从未见过没有它的东西。
然而,即使在这个阶段,该模型仍然能够准确地预测包围盒。
但话又说回来,当用它来对付负片时,它会给出假阳性,正如预期的那样,给出了一些随机的边界框坐标。
这就是我想通过下一步培训分类分部来解决的问题。
训练模型进行分类
然后就是训练模型的分类分支的时候了。
这里的不同之处在于,我们需要使用正图像和负图像来训练分类器,因为模型需要学习图像的存在和不存在,以正确地对它看到的图像进行分类。
为此,我再次运行了CSV生成脚本,但是这次将SKIP_NECTIONS参数设置为FALSE。这将生成包含正片和负片图像记录的CSV文件。对于底片图像,它为边界框坐标创建全零记录,并指定标签“No-Circle”作为标签。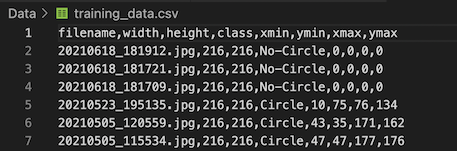
创建新数据集的步骤睡觉与创建用于培训本地化分支的数据集的步骤相同。
在第二阶段训练模型之前,我做的另一件重要的事情是保留已经训练好的卷积层和本地化分支的权重和偏差。因为,否则,使用不同的图像集进行新一轮训练可能会危及这些层已经训练好的权重和偏差,从而导致性能下降。该问题的解决方案是在用新数据集训练分类分支之前冻结卷积图层和边界框分支。
为此,我使用各自的前缀抓取基本层和本地化分支层,并将每个层的Training属性设置为false。
for layer in model.layers:
if layer.name.startswith('bl_'):
layer.trainable = False
for layer in model.layers:
if layer.name.startswith('bb_'):
layer.trainable = False在此步骤之后,模型中有大量不可训练的参数。它在模型的摘要中可见。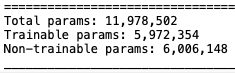
然后,我使用包含正负图像的第二个数据集来训练模型。由于基本层和本地化分支层被冻结,因此它基本上只能训练本地化层。如下图所示,仅在20个时期内,分类分支的培训性能并不太差。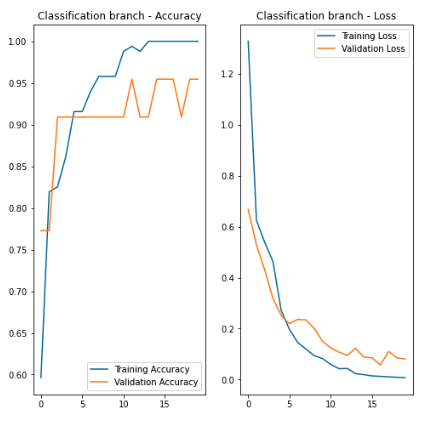
使用该模型进行目标检测
然后是使用模型做一些预测的有趣部分。
我使用了一组新的照片,分别使用和不使用视觉标记来测试一些预测。在这里,本地化输出总是给出一个边界框,即使其中没有视觉标记。但这在应用程序中不是问题,因为我们总是可以首先依赖分类输出,以了解图像中是否存在对象,然后避免在不存在的情况下绘制边界框。当我在Jupyter笔记本中显示下面的图像和它们的边界框时,我使用了相同的技术。
结论
这个练习向我证明,我们可以从头开始构建一个简单的单类对象检测器,而不需要依赖大型预先训练的模型。其次,双输出结构和针对不同数据集的两阶段训练是实现这一结果的关键。该模型给出了几个假阳性和假阴性,但这主要是由于有限的训练数据集和非最优的超参数造成的。通过调整超参数和使用更大的训练数据集,我们将能够获得更好的结果。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/13/%e5%88%a9%e7%94%a8%e5%8c%85%e5%9b%b4%e7%9b%92%e5%9b%9e%e5%bd%92%e5%9c%a8tensorflow%e4%b8%ad%e6%9e%84%e5%bb%ba%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b%e5%99%a8-2/
